Abstract.
小目标检测的应用存在于我们日常生活中的许多不同场景中,该课题也是目标检测与识别研究中最难的问题之一。因此,提高小目标检测精度不仅在理论上具有重要意义,在实践中也具有重要意义。然而,当前的检测相关算法在这项任务中效率低下;因此在本研究中,提出了一种基于YOLOv4模型的 广义改进算法。在常规的 跨阶段局部网络(CSPNet)的 “ADD” 和 “Concat” 层之后,增加了一种 混合注意力模块(MA),以加强目标的空间和通道特征信息;然后使用 膨胀卷积模块(DC)扩展目标小物体周围的感受野信息。
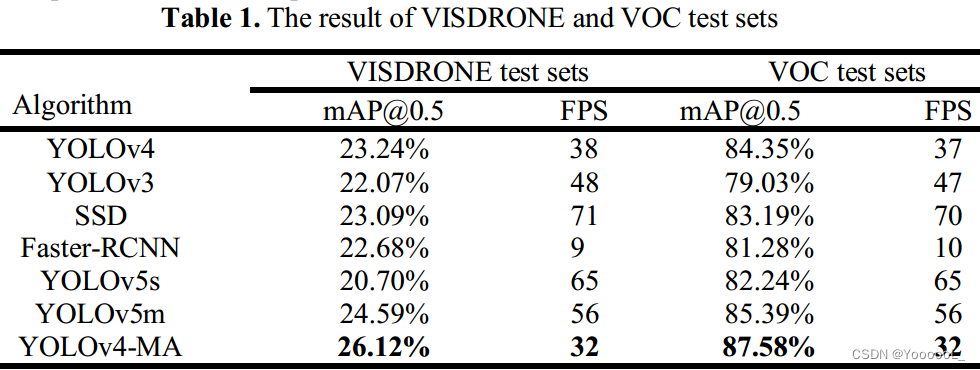
多项数值实验表明,这种与其算法相关的改进模型在 Pascal VOC 和 VISDRONE 数据集 ([email protected]) 上实现了更高的平均测试精度。与YOLOv4相比,这些性能评估指标分别提升了3.23%和2.88%。在输入图像大小设置为416*416的条件下 对YOLOv4网络结构进行改进后,模型在Pascal VOC数据集上的平均准确率达到87.58%,在VISDRONE数据集上达到26.12%。这些结果表明,在不影响实时性能的情况下,该方法在识别小物体方面明显优于原始检测算法。
1. Introduction
目标检测是计算机视觉领域中一个重要但困难的课题,广泛应用于智能监控和无人驾驶车辆导航等任务[1]。由于大多数物体在日常生活中以小或微小物体的形式出现,因此这种检测的任务已被世界各地的学者研究。以前,图像的特征和分类器经常用于构建此任务中的数学模型 [2]。但是,这种方法会导致 检测精度低 和 泛化性能弱的问题。结果,很难达到高精度。在ImageNet大规模视觉识别挑战赛(ILSVRC)的比赛中,AlexNet[3]在2012年以84.6%的Top-5精度夺冠后,基于深度学习的目标检测算法引起了广泛关注。一般来说,这个策略由两部分组成;第一部分包括 两阶段检测算法,其余部分包括 单阶段检测算法。这些两阶段检测算法通常首先在目标周围生成许多候选区域,然后通过分类和回归选择最合适的区域。典型案例有经典的RCNN[4]、Faster-RCNN[5] 和 Mask-RCNN[6]。单阶段回归算法直接定位目标。经典的单阶段算法是 YOLO [7] 和 SSD [8]。
针对 小目标检测中 分辨率低、特征表达能力弱 等问题,Hou等[9]引入了YOLOv4-TIA网络,利用 三元组注意力机制 改进CSPDarknet53网络,并在路径聚合网络Path Aggregation Network[10]( PANet)中 加入跳跃连接 skip connections 以获得更多的特征信息。
尽管这些研究在小目标检测方面取得了相当大的成就,但仍然存在以下问题:(1)特征图分辨率 和 小目标的特征 会因为过多的下采样而受到严重破坏; (2) 小目标样本少,尺寸小,容易被忽略。
针对上述问题,在本研究中,我们对 YOLOv4 网络进行了相关修改,以适应小目标检测。在 YOLOv4 [11] 算法中,无论目标是大、中还是小,都将相同的权重分配给通道特征图。该操作可能会忽略小物体的特征图数量有限的问题,这 不利于小目标检测的精度。为了提高小物体的检测精度,我们 在原始的 YOLOv4 网络中引入了一种 MA,以 增强小目标的通道和空间特征权重。第 2 节中介绍的 YOLOv4 网络通过多次下采样获取语义信息,这可能会降低图像的分辨率并减少物体的特征信息,从而导致错误的小物体检测。因此,我们在 CSPDarknet53 网络中嵌入了一个 DC,以 提高特征图的分辨率 并 减少特征信息的丢失。第 3 节详细介绍了提出的修改网络和算法。第 4 节介绍了两个典型数据集的实验结果,证明了所提出方法的有效性。第 5 节给出了结论和讨论。
2. 基于YOLOv4的小目标检测模型
YOLOv4算法结合了近年来优秀的算法思想。它将 CSPNet [12] 集成到Darknet53中,不仅通过 截断梯度流 策略 避免不同层网络学习重复的梯度信息,而且消除了 计算瓶颈 并 减少了内存消耗。 YOLOv4算法 采用mish激活函数,降低了计算成本,使梯度传播更加高效。此外,它还利用 Squeeze and Excitation Net [13] (SENet) 来 增强对象的特征图权重。最后,该算法将 CSPDarknet53 视为骨架网络。在 YOLOv4 的瓶颈部分,原来的 特征金字塔网络(FPN)被空间金字塔池化[14](SPP)层的路径聚合网络(PANet)所取代。该模块在一定程度上减轻了目标位置信息和轮廓轮廓信息的特征损失。 detection head用的是原来YOLOv3算法中的那个。
在输入端,如果图像尺寸为416*416,则会被分成三种不同尺寸的网格图像,分别为13*13、26*26和52*52,分别对应小、中、大目标。下面的图 1 展示了 YOLOv4 网络的结构。我们将继续利用经典算法进行研究,并引入MA模块来完善该算法在小目标检测中的应用。
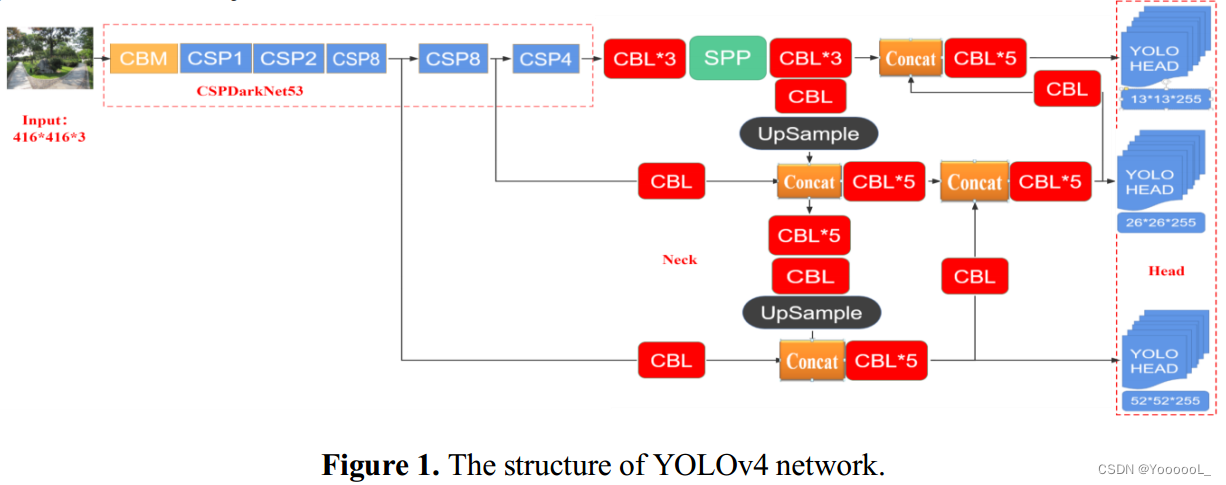
3. YOLOv4-MA网络
3.1. DC
膨胀卷积 Dilated convolution [15] 通过在特征图上 注入“空洞” 来扩大感受野,不仅提高了下采样时 特征图的分辨率,还保留了更多的特征信息。常规的卷积的计算公式为:
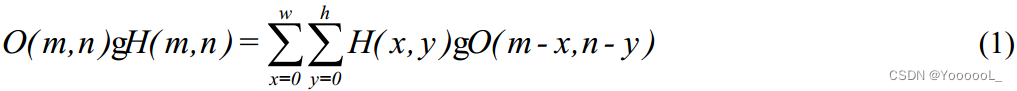
在等式(1)中,O(m,n)表示点(m,n)处的原始像素值,H(m,n)表示卷积核。 膨胀卷积 的计算公式为:
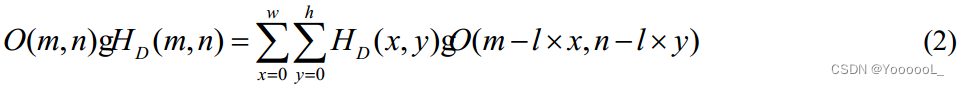
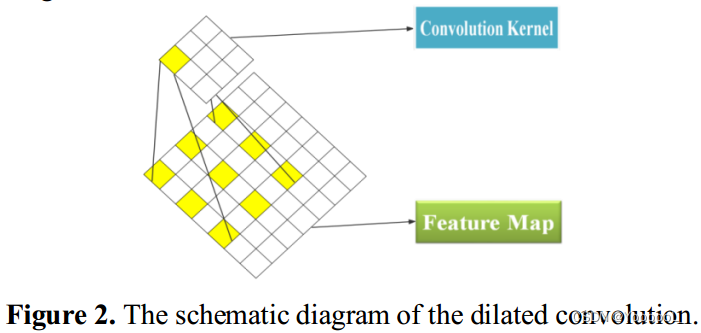
式(2)中,l为 dilation ratio 扩张比,用于描述普通卷积核的扩张比。 HD(m,n) 是膨胀卷积核。 膨胀卷积的示意图如图2所示,其中卷积核大小为3*3,膨胀率为1。
YOLOv4网络在YOLOv3网络中引入了一些优秀的算法,因此 在以大中型物体为主的数据集上取得了较高的准确率。但是,经过多次下采样处理后,小目标的分辨率和特征信息会被削减,从而削弱了模型的能力。因此,为了提高小目标的检测率,我们 将 膨胀卷积 嵌入到 CSPDarknet53 网络中,以 提高小物体的分辨率 并 获取更多的特征信息。卷积核大小为3*3,stride为1,dilation ratio为2。将经过膨胀卷积后大小为 208*208*64 的特征图与原始特征图进行拼接,得到这个结果再次与后面的内核进行卷积。改进后的结构如下图3所示。
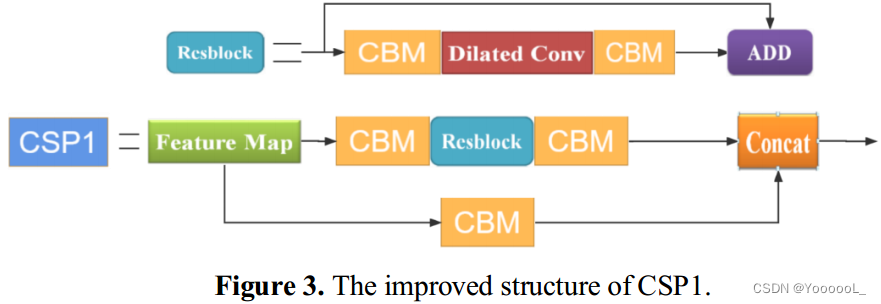
3.2. MA
注意力机制的主要作用是集中在特征图中有用的信息,有利于获取对象的全局信息。 YOLOv4 网络平等对待每个特征图,这可能不利于小目标检测。因此,为了提高这种检测的精度,受 SENet 和卷积块注意模块 [16] (CBAM) 的启发,我们设计了一种 MA 来改进 CSPDarknet53 网络,我们将修改后的网络命名为 YOLOv4-MA。网络结构如图4所示。
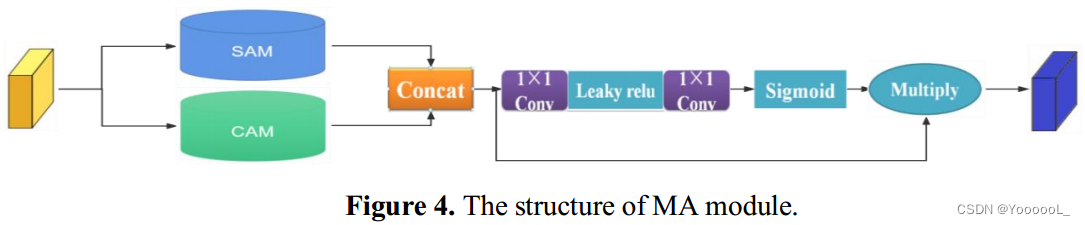
具体来说,我们 首先在通道维度上以“Concat”的方式连接 通道特征图和空间特征图。其次,我们通过 应用大小为 1*1 的卷积核提取每个特征图的权重,并将它们输入到 sigmoid 函数中以计算它们的最终权重。最后,我们 将最终的权重值乘以原始特征图,输出最终的特征图。

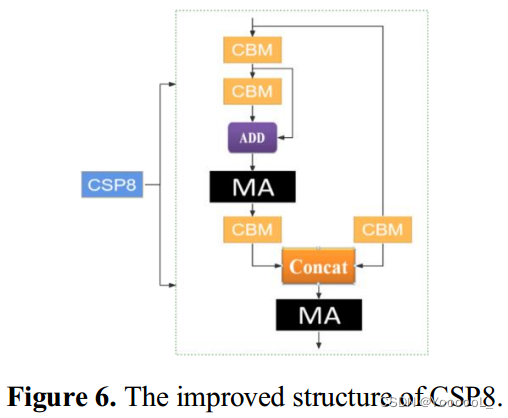
为了展示 MA 相对于原始 SENet 和 CBAM 的优越性,我们应用 Grad-cam 技术来比较 MA、SENet 和 CBAM 对两组不同小目标的注意效果。它们的热图如图5所示。因此,MA不仅增强了物体的纹理和形状特征,还扩展了小物体的空间位置特征。结合MA的CSPDarknet53网络结构 如下图6所示。
4. 实验结果与分析
数值实验在两个数据集上进行:PASCAL VOC 2007+2012 和 VISDRONE 2019 数据集。 PASCAL VOC 数据集总共包含 27088 张图像和 20 个类别。 VISDRONE 数据集总共包含 10 个类别的 8629 张图像。
为了公平比较,我们遵循官方评估协议,例如 mAP 和每秒帧数 (FPS)。 mAP和FPS的计算公式为:
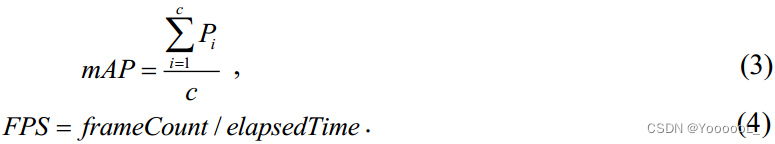
式(3)中,c表示目标类别的个数,Pi 表示 第i个目标的检测精度。式(4)中,frameCount表示帧数,elapsedTime表示检测时间。
本实验使用的训练和测试平台为Intel(R) I7-8700 CPU、GeForce RTX1080-Ti GPU。软件包基于Ubuntu 18.04、Python 3.7、PyTorch 1.4.0深度学习框架。 CUDA版本为10.2,CUDNN版本为7.5。训练过程的初始学习率为0.001。每25次迭代后,学习率下降到原来的0.1倍,动量为0.9,衰减系数为0.0005。使用 Adam 优化器,batch value 设置为 4,训练 Epochs 设置为 100 次。
我们比较了改进后的 YOLOv4 网络与 YOLOv3 和 v5 网络、SSD 和 Faster-RCNN 网络在 VOC 和 VISDRONE 测试集上的性能。这里,[email protected] 表示置信度为 0.5 时的平均精度,FPS 表示模型的检测速度。实验结果如下表1所示。根据表1的结果,提出的YOLOv4-MA算法 在VOC和VISDRONE测试集上分别比原YOLOv4算法提高了3.23%和2.88%。然后,我们将表 1 中的次优算法与每个数据集上的 YOLOv4-MA 算法进行比较。我们的算法在 VISDRONE 和 VOC 测试集上的精度分别提高了 1.53% 和 2.19% [email protected]。表明所提出的YOLOv4-MA算法可以在保证实时性的前提下提高小目标检测的精度。
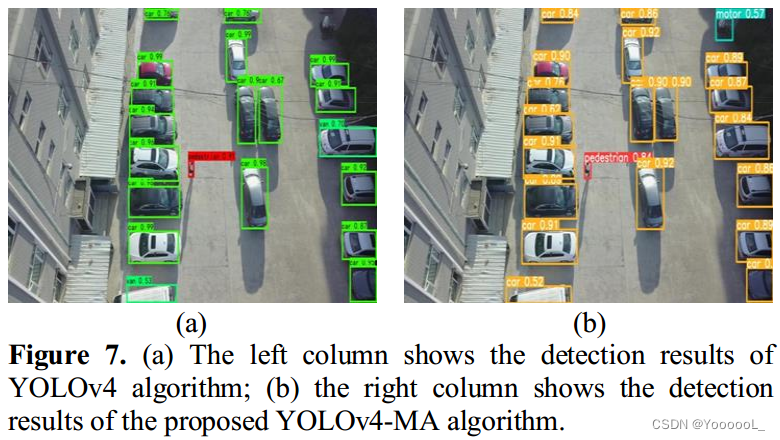
为了直观地比较 YOLOv4-MA 和 YOLOv4算法,下图7展示了他们在VOC和VISDRONE数据集上的结果对比。在图 7 中,YOLOv4-MA 算法可以实现比之前版本更高的置信度。因此,实验结果证明了我们提出的 YOLOv4-MA 算法的有效性。
5. Conclusion
为了提高小目标的检测精度,我们 对YOLOv4算法提出了两类改进。首先,我们将 DC 嵌入到骨干网络中,以提高小物体的分辨率,以获得更多的特征信息。其次,我们 引入 MA 来增强小目标的特征权重。实验结果表明,提出的方法在 PASCAL VOC 和 VISDRONE 数据集上的 [email protected] 指数分别比原始 YOLOv4 算法高 3.23% 和 2.88%。在未来的研究中,建议对模型进行剪枝以在不损失精度的情况下提高检测率。此外,可以将不同场景下的更多数据作为增强策略引入训练阶段,以泛化模型的性能。