Abstract
遥感图像中准确的目标检测非常重要,因为军事和民用领域的安全、交通和救援应用需要充分分析和使用这些图像。针对遥感图像中许多小尺寸目标难以检测的问题,本文提出了一种基于S2A-NET网络的改进S2ANET-SR模型。本文 将原始图像和缩小图像同时馈入检测网络,然后设计了缩小图像的超分辨率增强模块,以增强小目标的特征提取,之后,感知损失和纹理匹配损失被提出作为监督。进行了扩展实验以评估通用遥感数据集 DOTA 的性能,结果表明我们提出的方法可以达到 74.47% mAP,比 S2A-NET 的精度提高 0.79%。
1. Introduction
遥感技术的发展使人类进入了立体、多层次、多方位的对地观测新时代。遥感影像数据处理可用于军事、气象等领域。然而,由于遥感图像是鸟瞰图,因此包含许多复杂的空间场景和大量不同的对象。遥感图像中的目标检测不同于一般的目标检测,因为存在大量的小的、杂乱的和旋转的目标,这使得行人和车辆等遥感图像中的小目标的检测变得更加困难。
目标检测是计算机视觉领域的一个基础性问题,可广泛应用于环境监控、入侵检测、人机交互等诸多领域。其目标是快速准确地检测场景中的特定物体,从而为一些计算机视觉应用场景提供不可或缺的信息。目标检测的发展大致可以分为传统方法和基于深度学习的方法。传统的人工特征提取方法的性能自2010年以来鲜有提升。基于卷积神经网络的深度学习方法成为全球研究领域的焦点。随着计算能力的快速发展和优秀网络结构的出现,基于深度学习的目标检测获得了极大的成功。
深度学习的出现给遥感图像中的目标检测领域带来了前所未有的机遇。尽管研究人员在各个研究领域都在贡献自己的想法和解决方案,但仍有一些问题没有得到有效解决。小目标检测是这些重要而紧迫的问题之一,仍然需要持续努力来克服[1,2]。在本文中,我们基于 S2A-NET [3] 提出了一种名为 S2ANET-SR 的遥感图像目标检测算法,旨在提高遥感图像中小目标的检测精度。由于本文给出的框架具有普适性,本文提出的算法也可以应用于其他需要小目标检测的领域。
该工作的贡献总结如下:
• 本文提出了一种基于超分辨率方法的目标检测模型S2ANET-SR,设计了一个损失函数来提高遥感图像中小目标的检测性能。
• 本文删除了FAM 模块中的分类组件,以保持模型复杂度和参数数量与S2A NET 几乎相同。
• 本文在DOTA 数据集上的定向对象检测任务上报告了74.47% 的mAP,与S2A-NET 基线模型相比实现了0.79% 的改进。
2. Related work
2.1. 遥感图像中的目标检测
在过去的十年中,自然场景中的目标检测取得了重大进展,但遥感图像中目标检测领域的进展一直缓慢,因为航拍场景中缺乏注释良好的数据集。为促进对地观测和遥感图像目标检测的研究,提出了航拍图像目标检测(DOTA)的大规模数据集[4]。同时,在定向边界框上训练的 Faster R-CNN (FR-O) 被用作 DOTA 的基线模型,在 Faster R-CNN 的回归分支中添加了一个额外的回归目标 θ 来表示旋转的对象 [4]。 RoI Transformer 不是密集地对不同角度的锚点进行采样,而是通过在 RPN 阶段 [5] 轻型全连接层学习旋转 RoI 的变换参数来提取感兴趣区域 (RoI) 的旋转不变特征。最近提出的 S2A-NET 可以通过一种新颖的 对齐卷积 Alignment Convolution 提取细化的锚框的位置信息,并通过 Anchor Refinement Network锚框细化网络生成高质量的锚框[3] 。这些巨大的进步为对齐特征提供了新的方法,以便算法学习更准确的特征,但遥感图像中的密集物体和小尺寸目标仍然是检测器面临的挑战。
2.2.小目标检测
自动驾驶技术需要准确检测交通信号灯和行人。小的早期肿瘤区域的检测在医学治疗中具有重要意义。因此,提高图像中存在的小目标的识别和分割精度对于许多应用来说都是非常有益的。 T.-Y. Lin 等人在 2017 年提出了特征金字塔网络(Feature Pyramid Networks,FPN),通过构建多尺度特征图,使检测算法能够检测图像中不同尺度的目标,有效提高了小目标的检测精度[6]。多分支预测的思想也被 Yanghao Li 等人所借鉴,他们 提出了用于目标检测的尺度感知Trident 网络,并基于 ResNet-101 [7] 构建了具有不同感受野的并行多分支。 Jianan Li 等人提出了一种新的感知生成对抗网络(Perceptual GAN)模型,通过缩小小目标与大目标的特征信息差异来提高小目标检测能力[8]。检测难度较大的小目标在图像中频繁出现,因此检测算法整体性能的提升需要在小目标检测上有所突破。
2.3. 超分辨率方法
超分辨率是一种利用低分辨率图像生成高分辨率图像,同时恢复尽可能多的详细信息的技术 [9]。 SRCNN 是首次成功尝试仅使用卷积层进行超分辨率 [10],其结构简单明了,因为它仅由具有 ReLU 非线性的卷积层组成。与线性网络相比,残差学习利用跳跃连接来避免梯度消失,并使深度网络的设计成为可能。Enhanced Deep Super-Resolution 增强型深度超分辨率 (EDSR) 去除了 ResNet 每个残差块中的批归一化层,因为它们摆脱了网络的范围灵活性,并提出了一种新的多尺度深度超分辨率系统,其中大部分参数共享 [11]。受基于注意力模型的成功启发,提出了残差通道注意网络(RCAN)[12],具有 残差中残差residual in residual(RIR)结构 以形成非常深的网络,通道注意机制以通过通道之间的相互依赖性重新缩放通道特征。然而,大多数方法为了追求更好的超分辨率结果而采用规模大、参数多的模型,导致计算资源消耗较高,网络运行速度较低。
3. The proposed method
3.1.  A-NET 分析
A-NET 分析
深度学习算法近年来在计算机视觉领域取得了巨大成功,被认为是遥感图像处理的首选方法。 S2A-NET 是遥感图像中性能最好的端到端目标检测算法之一,在 DOTA 数据集上取得了优异的结果 [4]。 S2A-NET 针对 anchors 和 轴对齐卷积特征 之间的错位问题 提出了一种新颖的Alignment Convolution。 S2A-NET 没有使用其他方法中使用的密集采样的锚框,而是为特征图中的每个位置仅使用一个方形锚框,并通过锚框细化网络将它们细化为高质量的旋转锚框。
基于深度学习的应用通常需要提取图像的潜在特征,然后通过神经网络的前向传播得到预测结果。具有足够输入信息的样本和合适的神经网络是取得良好结果所必需的。然而,遥感图像中的小目标在图像中所占比例很小,导致边缘特征和纹理信息不明显甚至缺失。同时,检测模型的骨干网络通常包含多个下采样过程,这可能会使特征图中小物体的尺度仅为个位数像素。这种现象可以使检测算法在检测大目标时取得很好的效果,但不太适合小目标检测。
3.2. S2ANET-SR
目前最先进的检测方法对大型目标的检测精度较高,说明 这些方法具有准确检测目标的能力。因此,小目标的检测精度低是由于其特征信息提取不够。Perceptual GAN 使用大目标作为正样本,小目标作为负样本生成大对象,从而增强小对象的表征,使其与真实的大目标相似[8]。受此启发,我们利用遥感图像中 具有相同特征但不同尺度的大目标信息,增强了对小目标的特征提取。例如,利用该算法提取的原始大型车辆特征以逐像素加法的方式,可以提高小型车辆的检测精度。在基于FPN的检测算法[6]中,经过特征提取后的大小目标前向传播的网络结构和参数是相同的。可以推断,输出结果的差异是 由于输入目标的特征不同造成的。在本文中,我们在以下章节中对网络结构和损失函数提出了一些改进,以提高遥感图像中小目标的检测精度。
3.2.1. 图像的多尺度前向传播
以前的检测网络仅使用最后一层特征图进行预测,对图像中目标尺度的方差不鲁棒。 FPN 给出了解决这个问题的思路。如图 1 左侧所示,FPN 自下而上的输入特征图分别有 256、512、1024 和 2048 个通道,而输出特征图均为 256 个通道,如图 1 右侧所示。对此,FPN选择多个特征图作为最终提取的特征图,解决了目标检测中的多尺度问题,取得了较高的检测性能。

大物体和小物体的区别在于尺度的不同。将图像尺寸缩小2倍,图像中物体的尺寸自然会缩小2倍。在卷积神经网络上下文中,感受野是特征图中的一个点可以映射到原始图像上的区域的大小。本文根据特征图的感受野,将FPN自下而上四层特征图中用于回归的方形锚框的宽度分别设置为32、64、128和256,使得目标在相应尺度的特征图层上可以更容易地检测出不同尺度的特征图。

在本文中,我们在网络中进一步添加了两个前向传播过程,如图 2 所示,其中输入 I2 表示将原始图像尺寸缩小 2 倍生成的图像,输入 I4 表示将原始图像尺寸缩小 4 倍得到的图像。这样,大物体就被缩小为小物体,从而得到原始图像和缩小图像的多尺度特征图。因此,原始图像的检测结果可以用来监督缩小图像的检测结果。
3.2.2. Feature enhancement module
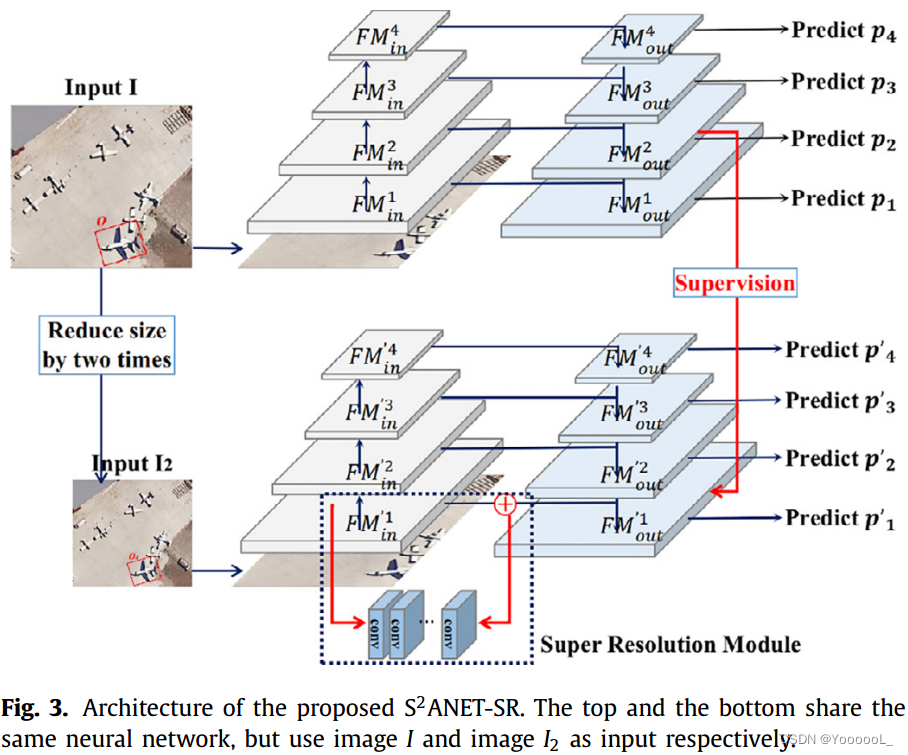
FPN 的底层(图 3 右侧)主要检测 32×32 像素左右的小物体,第二层主要检测 64×64 像素左右的物体,而较高的两层分别主要检测128×128和256×256的物体。将 64×64 像素的对象(例如图 3 中图像 I 中的飞机)表示为 o。如果我们将图像尺寸缩小 2 倍并得到一个新图像 I2,则 I2 中的 o 可以表示为 o2,其大小为 32 × 32 像素。 FPN 在原始图像和缩小图像中的特征图分别表示为 FM 和 FM'。我们用 和
分别表示FPN的输入特征图和输出特征图,其中i表示FPN自底向上四层特征图的层数(i=1,2,3,4),它与 FM’相同。网络的预测组件表示为 Pi,其中 i 表示 FPN 自底向上四层特征图的层数。对于图像 I,目标 o(图 3 中的一个飞机)预计将在 FMout2 层被检测到。对于图像 I2,由于图像尺寸缩小了 2 倍,物体 o2 的尺寸为 32×32 像素,因此,物体 o2 预计在
层被检测到。但由于图像尺寸缩小会降低图像分辨率,缩小后的物体o2的特征信息较少,从而导致对小目标的检测精度较低,因此在
处可能检测不到o2。
由于图像分辨率降低导致的特征信息不足会使检测算法失效,我们构建了一个基于S2A-NET的超分辨率模块来增强小目标的特征提取,这些小目标有望在FPN 的底层被检测到,如图3所示。超分辨率是一种图像到图像的转换任务,其中 源图像与目标图像 高度相关 [9]。如图3所示,超分辨率模块的构建 是为了使
能够学习到更小目标的更充分的特征。所提出的模块由 3 个堆叠的全局残差模块 [13] 组成,它们仅学习源特征图
和 目标特征图
之间的残差,以恢复缺失的高频细节,并以原始图像
的相应特征图作为
的监督。由于两个特征图
和
之间的大部分残差接近于零,因此残差模块的学习难度没有明显增加。
3.2.3.损失函数
大尺寸物体具有足够的特征,可以很好地检测到。在本文中,我们以 和
作为监督 来提高较小目标的检测性能。最先进的检测网络可以对具有足够特征的大物体表现良好,因此无需调整预测组件的参数。如果使用P2的输出作为P1' 输出的超分辨率监督,预测分量P1' 的参数将被调整,检测器的性能将受到影响。因此,本文不使用网络的最终输出作为监督,而是直接应用特征图作为监督,以促进两个特征图
和
具有相似的特征。此外,两个特征图具有相同的维度,我们可以以像素级的方式计算损失。
Geirhos R. 等人对卷积神经网络技术 [14] 的分类问题进行了广泛的验证实验,并提出目标检测中的深度学习技术在很大程度上依赖于纹理,而不是目标的形状。与较大的目标相比,特征信息较差的小目标往往表现更差,因为它们包含的细节和纹理信息要少得多,尽管较小和较大的目标具有非常相似的形状。如图1所示,我们引入了结合 原始的分类损失 和 回归损失 的超分辨率损失。我们使用 Enhance Net [15] 提出的 感知损失 和 纹理匹配损失 作为本文中 特征图的超分辨率损失。
(1) Perceptual Loss 感知损失
待增强的低分辨率特征图用FLR表示,用于监督的高分辨率特征图用FHR表示。两个特征图都被输入到一个可微函数中,损失由等式(1)计算。

本文取FM2out 和FM1'out作为损失函数的输入,分别对应FLR和FHR。我们使用像素级 MSE 训练我们的模型。
(2) Texture Matching Loss 纹理匹配损失
纹理特征损失的引入,如式(2)所示,可以促进网络提取更丰富的纹理信息的能力。

在等式(2)中,![]() ,其中F表示FPN中的一层特征图。如等式(3)所示,F中每对通道的特征内积,Gram矩阵G定义为位于图像相同位置下的每对特征之间的组合,其中 fi 是特征F中第i个通道的值。两个通道fi和fj的特征值之间的相关性可以推导出高级纹理信息,因此Gram矩阵G可以帮助捕捉图像的一般纹理风格。
,其中F表示FPN中的一层特征图。如等式(3)所示,F中每对通道的特征内积,Gram矩阵G定义为位于图像相同位置下的每对特征之间的组合,其中 fi 是特征F中第i个通道的值。两个通道fi和fj的特征值之间的相关性可以推导出高级纹理信息,因此Gram矩阵G可以帮助捕捉图像的一般纹理风格。

4.实验与分析
4.1. 数据集
基准 DOTA-v1.0 是一个带有定向边界框注释的大型遥感图像目标检测数据集。它包含从多个传感器和平台(例如Google Earth、GF-2 和 来自中国的 JL1 卫星)收集的 2806 张大尺寸遥感图像,具有多种分辨率。图像尺寸从800×800到4000×4000,共有15个类别18882个实例:飞机(PL)、棒球内场(BD)、桥梁(BR)、田径场(GTF)、小型车辆(SV) ), 大型车辆(LV), 船舶(SH), 网球场(TC),篮球场(BC), 储罐(ST),足球场(SBF),环岛(RA),海港(HA),游泳池 (SP) 和 直升机 (HC)。随机抽取原始图像的一半作为训练集,1/6作为验证集,1/3作为测试集。我们可以用训练集和验证集训练模型,然后将测试集的检测结果提交给服务器进行评估。
4.2. 实现细节
目标检测任务和分类任务在网络的图像特征提取部分遵循相同的过程。在本文中,我们采用预训练的分类模型并以微调的方式在 DOTA 数据集上对其进行训练,同时保留特征提取网络的参数。
该算法由 PyTorch 在具有 4 个 12G 显存的 GeForce RTX 2080 Ti 的服务器上实现。我们采用 S2A-NET ResNet50 FPN 作为骨干网络,并使用与 MMDetection [16] 相同的训练计划。在我们的实验中,我们从 S2A-NET 中的 FAM 模块 [16] 中删除了分类组件,因为该分类组件的预测对主网络的训练没有贡献,并且发现检测精度没有降低。 DOTA 数据集的训练时间设置为 12 个 epoch。输入图像分别缩小2倍和4倍,得到原图和缩小图的多尺度特征图。我们训练模型总共进行了 32,000 次迭代,初始学习率为 0.01,并且在第 21,000 次和第 29,000 次迭代时将学习率除以 10。动量和权重衰减分别设置为 0.9 和 0.0001。我们采用学习率预热 500 次迭代。我们使用四个 2080 Ti GPU,总批大小为 8 进行训练和测试,并使用 SGD 进行损失优化。平均精度 (mAP) [17] 用于评估所提出模型的性能。
4.3.消融研究
为了验证本文设计模块的有效性,我们对提出的两个损失函数进行了一系列消融实验。我们使用 S2A-NET 作为我们的基线,它可以为 DOTA 数据集实现 73.89% 的 mAP。
由于计算量大和不需要学习的背景区域占据了大部分特征图,从表1可以看出,当使用整个特征图作为监督来计算损失时,与基线相比,检测精度甚至下降了0.32,从73.89% mAP到73.57% mAP。同时,当直接在整个特征图上计算纹理匹配损失时,由于纹理信息在整个图像中被平均化,纹理信息的多样性降低,也会导致结果不佳。如果 以掩码的方式计算损失以关注图像中有前景物体的区域,我们可以达到 74.15% 的 mAP。对局部特征 逐块级地 计算纹理匹配损失时 检测精度为74.03%mAP,旨在 保证局部区域纹理信息的一致性。根据 Enhance Net [15],我们将patch大小设置为 16 × 16 像素,以在 准确可靠的纹理生成 和 特征的整体感知质量 之间保持最佳平衡。如果以 mask 和 patch 的方式计算损失,我们提出的方法最终可以达到 74.47% mAP。
4.4.与 S2A-NET 的比较

S2A-NET和S2ANET-SR算法对遥感图像中不同类别目标的检测精度和mAP如表2所示。可以发现,所提出的算法S2ANET-SR在11个类别上优于S2A-NET。特别是,我们在小型车辆类别中提高了约 3% 的 AP,在飞机类别中提高了约 2% 的 AP。这表明对于遥感图像中的小物体,S2ANET-SR 可以提取出更明显、有利于检测的特征。总体而言,S2ANET-SR 可以将 mAP 从 73.89% 提高到 74.47%,有效提高了检测的准确性。

图4显示了小型车辆和飞机的检测结果对比,其中图4a和d 代表待检测的原始图像。此外,图4b和e表示使用S2A-NET算法的检测结果,图4c和f表示使用S2ANET-SR算法的检测结果。对比观察表明,由于特征信息不足,S2A-NET 对遥感图像中的车辆和飞机等小物体的召回率较低。在图 4b 和 e 中,有 3 个和 2 个对象没有被 S2A-NET 算法检测出来,这 5 个对象用红色文本标记。在本文中,我们添加了一个超分辨率模块 并引入了适当的损失函数来提高小目标的召回率,从而显著提高了目标检测的总体性能。
(文章里没有给图)由于原始图像和缩小图像的一般特征信息相似,因此与检测损失(蓝色、橙色和绿色曲线)相比,超分辨率损失(红色和紫色曲线)的初始损失值要低得多。经过 32,000 次迭代后,模型可以收敛。提出的超分辨率模块增加了模型复杂度和参数数量,然而,我们通过去除 FAM 模块中的分类组件在一定程度上降低了模型复杂度和参数数量。如表 3 所示,输入图像大小为 1024 × 1024 时,模型复杂度 (Flops) 和参数数量分别仅增加 7.61%(从 172.48 GMac 到 185.62 GMac)和 0.35%(36.21 M 到 36.34 M)。
5.结论
在本文中,我们提出了 S2ANET-SR 目标检测算法,以提高 S2A-NET 对遥感图像中小目标的检测精度。鉴于检测算法对两个具有相同特征但大小不同的目标检测结果不同,我们在FPN中使用原始图像的特征信息作为对缩小图像特征信息的监督。我们引入了感知损失和纹理匹配损失来与原始检测损失联合训练网络。 S2ANET-SR基于超分辨率增强对小目标的特征提取,对检测速度影响很小,从而最终提高遥感图像中小物体的检测精度。我们在空中目标检测数据集 DOTA 上与 S2A-NET 进行了相关的消融研究和比较实验,并证明了所提出的 S2ANET-SR 在检测遥感图像中的小目标方面的优越性。