一、论文简述
1. 第一作者:Tianqi Liu
2. 发表年份:2023
3. 发表期刊:CVPR
4. 关键词:MVS、深度学习、特征表示、极线聚合、Transformer
5. 探索动机:基于学习的多视图立体方法严重依赖于特征匹配,因此需要设计独特的描述性表示。 有效的解决方案是应用非局部特征聚合,例如 Transformer。 尽管有用,但会给MVS带来大量的计算开销。
匹配的重要性:A critical part of MVS is to match pixels to find the corresponding points. This matching process heavily relies on the feature representation: corresponding points in different views should be close in the embedding space.
传统方法的不足:Traditional MVS approaches adopt hand-craft feature representation, which faces challenges on repetitive-pattern, weak-texture, and reflective regions.
卷积方法的不足:Powerful as convolutional neural networks (CNNs) are, they still prefer to aggregate local context, which may be less accurate for matching.
非局部特征聚合优势:One feasible solution is to adopt non-local feature augmentation strategy with large receptive field and flexible feature aggregation, which is crucial for robust and descriptive feature representations.现有非局部聚合的劣势:Techniques such as deformable convolution, attention, and Transformers, are introduced to the feature encoding of MVS. Albeit useful, these general-purpose non-local operators introduce huge computation overhead for MVS, as each point need to densely attend the reference and source images. In this case, distractive or irrelevant features can also be attended which are harmful to the feature matching.
6. 工作目标:如何挖掘MVS的非局部上下文?受经典的极线几何的启发,提出将非局部特征聚合约束在极线内,既具有效率又具有描述性。
7. 核心思想:引入了一种基于极线约束的非局部特征聚合策略。
- 将非局部特征增强限制在一对线内:每个点仅关注相应的一对极线。 该想法受到经典极线几何的启发,它表明具有不同深度假设的一个点将投影到另一个视图上的极线。 该约束将2D搜索空间减少为立体匹配中的极线。 类似地,这表明MVS的匹配是为了区分位于同一条线上的一系列点。因此设计了一种线对点非局部增强策略,提出了一种在两个校准图像中搜索极线对的算法。
- 设计了一个极线内增强(IEA)模块和一个跨极线增强(CEA)模块来挖掘极线内部和跨极线的非局部上下文。
- 将这些模块打包到一个名为Epipolar Transformer的模型中,并将ET集成到基线网络中以构建ET-MVSNet。
- ET还可以作为集成到其他MVS方法中的即插即用模块。
8. 实验结果:
Thanks to Epipolar Transformer (ET), the depth estimation and 3-D representations have greatly improved and achieved state-of-the-art results on both the DTU and the Tanks and Temple benchmark. Besides, compared with the prevailing global attention that mines global context, Epipolar Transformer (ET) shows significantly better performance and efficiency.
9. 论文及代码下载:
https://github.com/TQTQliu/ET-MVSNet
二、实现过程
1. ET-MVSNet
ET-MVSNet的整体架构如下图所示。所提出的ET模块被集成到FPN中。 为了对极线执行非局部特征聚合,首先搜索参考视图和源视图之间的极线对。 利用搜索到的极线对,通过采样将原始特征图分解为不同的极线对。 然后,通过极线内增强(IEA)和跨极线增强(CEA)模块在这些极线对之间传输非局部上下文,可以堆叠Na层。在实现中,设置Na = 1。生成的序列被映射回特征映射,然后由局部增强(LA)模块平滑增强的特征映射。最后,将增强的特征映射输入到FPN的上采样层,然后进行代价体构建和正则化。


极线几何。参考图像中具有不同深度假设的像素可以投影到源图像中的同一极线上,称为点对线。穿过两个相机中心和一个三维点的平面与图像平面相交时产生极线。两个图像的两个极线形成一个极线对,称为线对线。
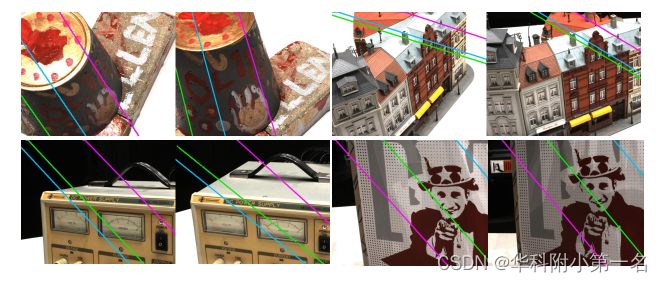
极线对的可视化。相同的颜色表示相应的极线。
2. 极线对搜索
MVS的关键部分是通过特征匹配将像素与一组预定义假设中最合适的深度假设进行匹配。 如果假设接近GT,则像素对的特征应该是相似的,这表明假设的区分很大程度上依赖于特征表示。 由于用于匹配的特征体自然位于极线上,因此使用极线作为非局部特征的来源可以有效地实现高质量的表示,有利于区分不同的假设。 应该注意的是,极线同时存在于参考视图和源视图中,并且由于几何限制成对出现。 这表明同一极线上的像素共享相同的非局部特征源,并且这些像素的特征聚合过程是相同的。 并行聚合将提高效率。 为了实现并行过程,需要预先搜索位于同一对极线对上的像素,为此提出了一种极线对搜索算法。

如算法1所示,极线对的搜索包括两个步骤:点对线搜索和极线匹配。 第一步,我们计算参考图像中每个像素的极线参数。 然后,将参考视图中的像素聚合到不同的簇中; 同一簇中的像素共享相同的极线。 因此,在极线对搜索之后,参考图像和源图像中的像素被划分为极线对。
由于一对多视图匹配可以分解为多个一对一视图匹配,为了便于理解,以一个源视图来说明极线对搜索。 给定参考视图中的像素pr ,源视图中对应的像素ps为:
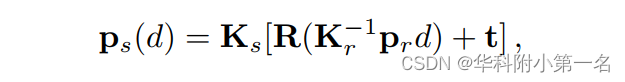
其中d表示深度,R和t表示参考视图和源视图之间的旋转和平移。Kr和Ks分别表示参考视图和源视图的内参。 因此, ps(d)的坐标可以通过以下方式计算:
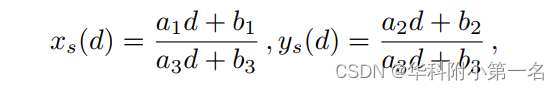
ai,bi是与相机参数和pr坐标相关的常量。 然后,消去深度d,即可得到极线标准方程ys(d)=kxs(d)+b,其公式为:

具体来说,当∆xs(d)→0时,我们使用方程xd(s) = k'ys(d)+b'。由于k、b与d无关,用与pr坐标相关的常数表示,如果两个像素在同一极线上,它们的k和b理论上是相同的。然而,在实际操作中,由于像素的坐标离散,不同像素在极线周围计算的ks和bs可能在很小的范围内变化,这样直接将相同ks或bs的像素分组会导致过分割。
为了减轻过度分裂,通过四舍五入来量化ks和bs。因此,具有近似参数的像素将被分组到同一极线中。 以此完成参考视图的分组。然后,在源视图中搜索相应的极线。ks和bs表示源视图上对应的极线,因为极线周围像素的坐标将满足上式。对于源图像,通过计算k和b表示的极线上的像素点的距离来确定该像素点是否位于k和b表示的极线上。
通过将像素划分为其相应的极线对,参考特征图和源特征图都被分解为特征序列集。 具体来说,假设获得m对极线,将参考和源特征集定义为ER和ES,其公式为:
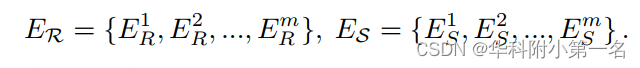
它们是形状为n × c的特征序列,其中n表示对应极线中的像素数,c表示特征维度。
3. 极线内和极线间增强
利用极线对ER和ES进行非局部特征增强。 由于具有不同深度假设的点落在极线上,因此匹配过程是区分位于同一条线上的一系列点。 受立体匹配中点对线搜索策略的启发,提出了一种point-to-line非局部增强:参考图像中的每个像素仅关注其对应的极线对。 为了描述源图像中具有非局部信息的像素,基于自注意力设计了极线内增强(IEA)模块。 然后,交叉极线增强 (CEA) 模块将参考极线ER的信息通过交叉注意力传播到源极线ES中。
Intra-Epipolar Augmentation (IEA)。IEA 利用极线内的自注意力来聚合非局部结构信息,这可以为困难区域(例如弱纹理区域)生成描述性特征表示。 对于 ES中的每条极线 ESi ,增强过程定义为:

其中MHSA(x) 是多头自注意力模块,把一个序列x作为输入。
Cross-Epipolar Augmentation (CEA)。由于视点不同,潜在的透视变换对具有不同几何形状的相同语义像素提出了挑战。 通过跨极线传输信息来缓解这一问题。 具体来说,使用交叉注意力模块将信息从参考线ER传播到ES中,用CEA表示。 在CEA中,ESi首先由交叉注意力层处理:

其中MHCA(q,k,v)是多头交叉注意力,具体来说,在交叉注意层之后添加了一个前馈网络,如标准Transformer块中一样。 IEA 和 CEA 块可以堆叠以增强功能。
Local Augmentation (LA)。尽管极线内的非局部特征增强是有效的,并且在实验中被证明有效,我们发现增强的特征图包含一些空洞,其中像素位于两幅图像的公共视图之外,或者由于像素的离散性质引起的量化误差而未被算法检测到,这可能导致特征表示的不连续性并且对匹配不友好。 为了解决这个问题,我们在IEA和CEA块之后使用额外的卷积层来重新聚合局部上下文,以填充特征孔并平滑增强特征。
4. 实现细节
延续MVSTER,采用8、8、4、4个深度假设的四阶段深度估计,并采用逆深度采样。为了简化训练,将原有的单目深度估计辅助分支从MVSTER移除。将Epipolar Transforme(ET)加入到FPN中处理最粗糙的下采样率为8的特征映射中,以节省计算成本。
对所有阶段都使用交叉熵损失。总损失如下:
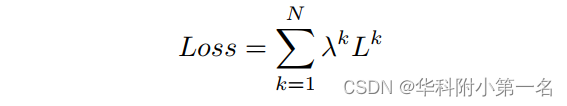
式中,N为阶段数,Lk为第k阶段的损失,λk为第k阶段的损失权重。其中,N = 4, λ1 =…= λN = 1。
5. 实验
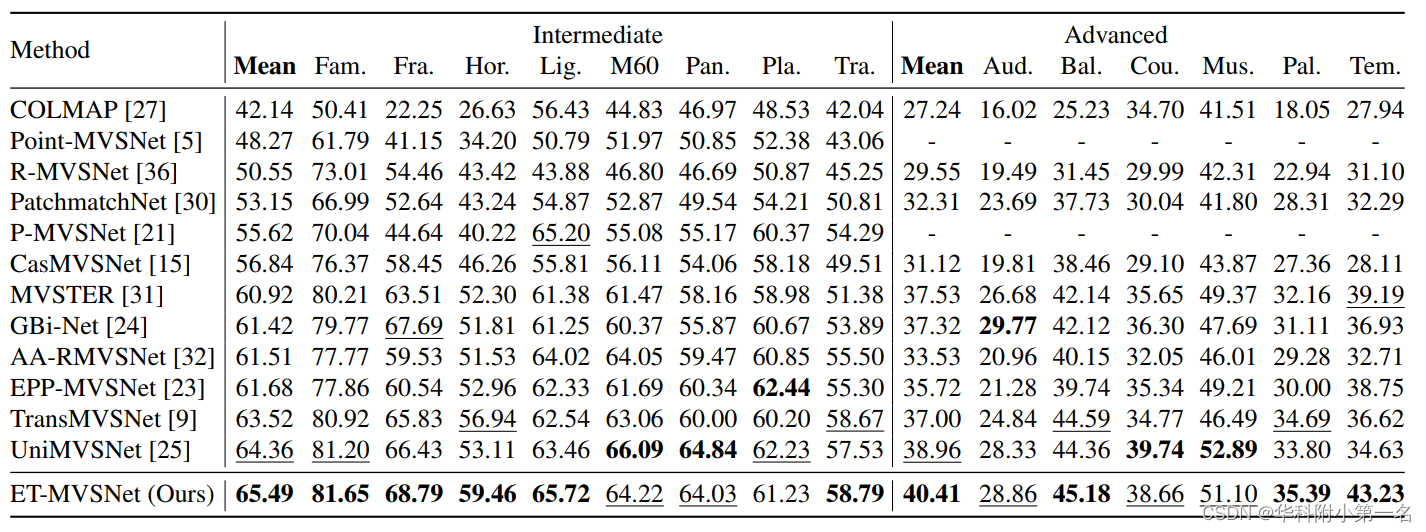
5.1. 与先进技术的比较

5.2. 注意力图可视化
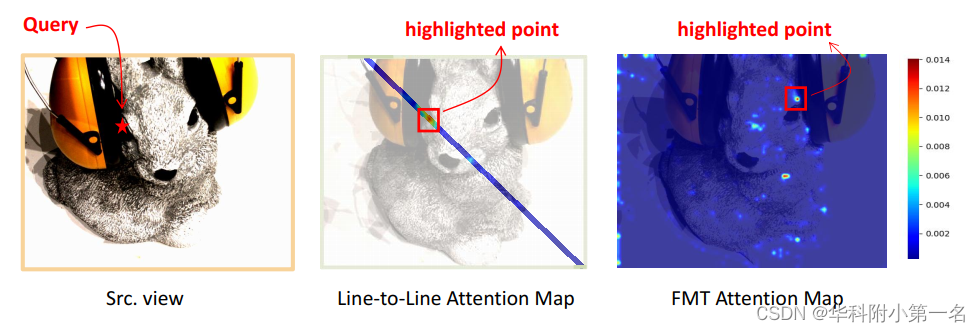
线对线的Epipolar Transformer的注意力图是两条对应的极线,特征匹配Transformer(FMT)的注意力图是一个像素和另一个图像之间。给定源图像的极线上的一个查询点,ET关注其对应的极线区域,而FMT则考虑整个参考图像。红框指向ET和FMT注意力图中注意力得分最高的区域。