—— 大牛:杨庆雄
NOTE
这篇paper是基于树来优化(性能角度)双边滤波?
思想是否阔以直接应用到视频流之类的refine中?
The proposed method can be naturally extended to the time domain for enforcing temporal coherence without deteriorating the depth edges when all the video frames are considered
answer:
——记于20191018
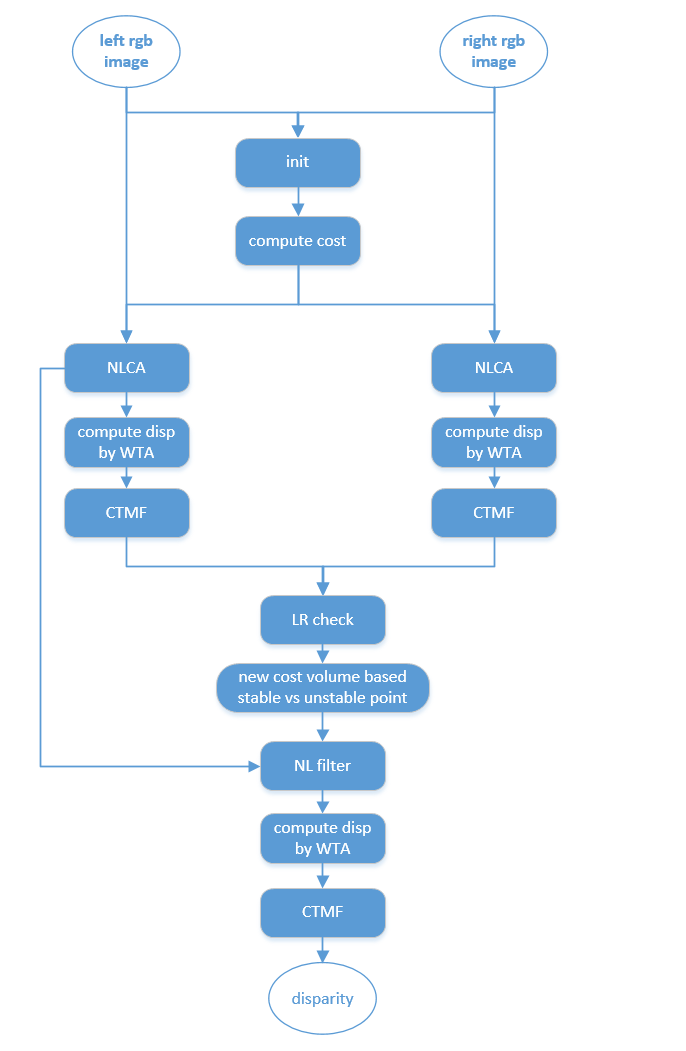
- NLCA只是作者将树和滤波结合应用在立体匹配的代价聚合中而已,可以统称为propagation的一个动作;
- 传统局部法滤波,通常是限定一个局部窗口,定义窗口内其他点与当前点之间的相似性关系之后,作加权平均即可,e.g. Guided Filter, Bilateral Filter等
- non-local类,常见的是去噪领域的non-local filter,和bilateral filter的区别仅是去除了后者的空间距离限制。考虑到全局计算和当前点的相关性计算成本过高,在实际应用中通常还是会限定一个大一点的范围来做,而非全图范围;
- 本文也属于一种non-local的filter,只是本文利用了树节点之间的关系,以彩色图定义的颜色相似度为边权重来控制节点间的影响程度,并未显式去设定代价聚合的空间范围;
- 因此,双边滤波和本文的算法逻辑还是会有所差异,两者不存在性能上优化的这种说法
- 因此,本文的算法逻辑是可应用到time-domain,增强帧间连续性的
- NLCA在光流的应用?
前言
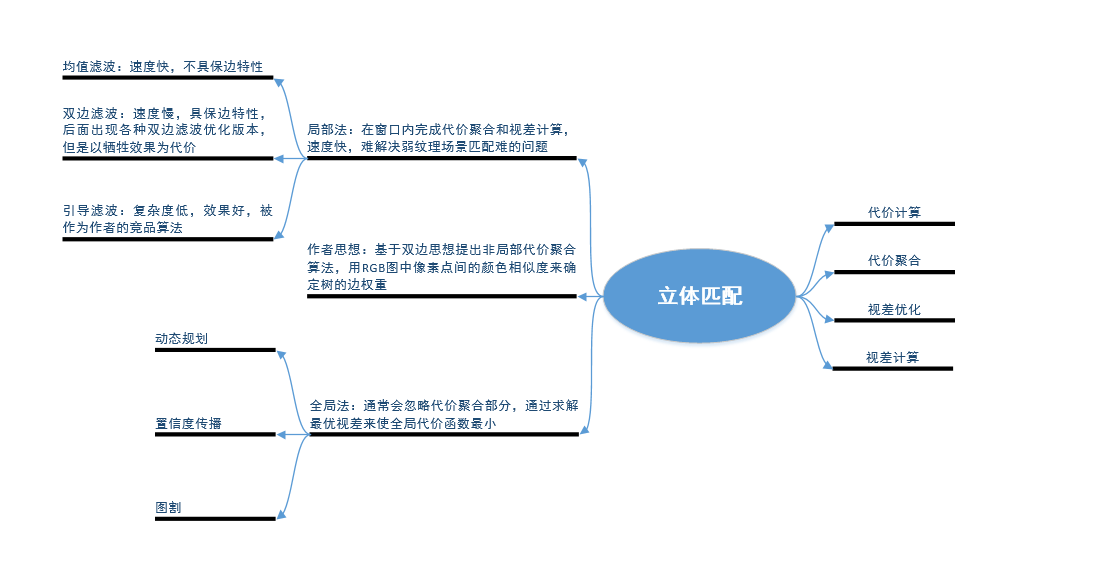
- 立体匹配流程:
- 代价计算(cost compute)
- 代价聚合(cost aggregation)
- 视差计算(disparity computation)
- 视差优化(disparity refine)
代价聚合(cost aggregation)是立体匹配中一个重要的模块,主要分为:
局部法:通过设计窗口形状、大小以及滤波权重在窗口内实现局部最优代价聚合(窗口外的像素可看做权重为0),优点是速度快,缺点是结果为局部最优
全局法:通过构造能量函数或是建树,以全局代价值最小为目标来实现代价聚合,优点是精度高,缺点是速度慢
Abstract
主要思想:
通过构建最小生成树来完成最优代价聚合,树节点为像素点,连接树节点的边权重由树节点间的相似度决定
贡献点:
- 非局部代价聚合,能处理局部法难处理的弱纹理场景
- 算法复杂度低:\(O(N*D*5)\),其中,\(N\)为像素点数,\(D\)为视差层级,每个视差层级下每个像素点包括2次加法和3次乘法
- 可将non-local思想扩展到视差图refine部分,速度是文献【7】中基于guided filter refine的70x
- 和unnormalized boxfilter比较,速度会慢1.25x,引用了【24】,主要是提出用积分图加速boxfilter
风险点:
在复杂纹理场景精度较低,容易导致左右视差不连续,通过连续性检测标记出这类点为不可靠点,可通过non-local tree refine即可解决
However, the proposed method may be less accurate around highly-textured regions where stereo matching is expected to perform well (but may be not due to noises), thus the supports from the neighbors are relatively small according to the proposed method. Errors around highly-textured regions are mostly due to noises and will cause inconsistency between the left and right disparity maps. Mutual consistency check will classify these pixel- s into unstable pixels, and the proposed non-local disparity refinement method is expected to correct these errors.
时间性能:
- 硬件:1.8 GHz 酷睿i7 CPU,4 GB缓存
- 数据集:middlebury
- 耗时:90ms
关键文献:
future(关于加速):
【1】 D. Bader and G. Cong. A fast, parallel spanning tree algorithm for symmetric multiprocessors (smp- s). Journal of Parallel and Distributed Computing, 65:994–1006, 2005.
【11】D. Min, J. Lu, and M. Do. A revisit to cost aggre- gation in stereo matching: How far can we reduce its computational redundancy? In ICCV, 2011.
对比算法:
【7】 C.Rhemann, A. Hosni, M. Bleyer, C. Rother, and M. Gelautz. Fast cost-volume filtering for visual cor- respondence and beyond. In CVPR, pages 3017–3024, 2011
【24】P. Viola and M. Jones. Robust real-time face detection. volume 57, pages 137–154, 2003.
研究背景
算法思想
核心:
代价聚合本质:
\[C_d^A(p) = \sum_q{S(p, q)C_d(q)}\tag{1}\]
建树:
边:颜色相似度:
\[S(p, q)=S(q, p)=\exp(-\frac{D(p,q)}{\sigma})\tag{2}\]
节点:像素点
节点基于边的连接:参见基于kruskals构建最小生成树的思想:
https://www.cnblogs.com/biyeymyhjob/archive/2012/07/30/2615542.html
节点与节点间的联系:
遍历连接好的节点,记录节点间的连接关系(父节点,子节点,边权重的记录)
遍历:from leaf to root
——树深度层次的代价传播
\[C_d^{A\uparrow}(v)=C_d(v) + \sum_{P(v_c)=v}{S(v, v_c)·C_d^{A\uparrow}(v_c)}\tag{3}\]
遍历:from root to leaf
——树广度层次的代价传播
\[C_d^A(v)=C_d^{A\uparrow}(v) + S(P(v), v)·\left[ C_d^A(P(v)) - S(v, P(v))· C_d^{A\uparrow}(v) \right] \\ = S(P(v), v)·C_d^A(P(v)) + \left[ 1 - S^2(v, P(v))\right]· C_d^{A\uparrow}(v) \tag{4}\]
NLCA pipeline

NLCA & NLPP based stereo matching pipeline