一、论文简述
1. 第一作者:Yongrong Cao
2. 发表年份:2022
3. 发表期刊:BMVC CCF-C类
4. 关键词:MVS、3D重建、上下文、自注意力、全局信息
5. 探索动机:CNN的局限性,缺少全局上下文通常会导致无纹理或弱纹理区域出现局部歧义,从而降低匹配的鲁棒性。
- Local features are well captured by convolutions. The locality of convolution features prevents the perception of global context information, which is essential for robust depth estimation at challenging regions in MVS, such as weak texture, repetitive patterns, and non-Lambertian areas.
- When decoding matching costs, the features to be simply added, and potential depth information correspondences are not taken into consideration.
- Convolution operation has strong ability to extract local feature information, such as texture and color. However, for a whole input image, the correlation degree of the relevant information of the image itself seriously affects the learning of the global features of the object.
6. 工作目标:自注意力可以在每个视图中挖掘全局上下文。
Self-attention modules complement convolutions and help model long-range, multi-level dependencies across image regions. With self-attention, the network can capture images in which fine details in each local area are carefully coordinated with fine details in distant parts of the image.
7. 核心思想:
- We propose a novel end-to-end deep neural framework, namely Global Context Complementary Network (GCCN), for robust long-range global context aggregation within images. Moreover, the combination of local and global information contributes to converge network.
- In addition, to better regress the depth map, we introduce a contextual-feature complementary learning module to restore the 3D structure information of the scene.
8. 实验结果:
Our method achieves state-of-the-art results on the DTU dataset and the Tanks & Temples benchmark.
9.论文下载:
https://bmvc2022.mpi-inf.mpg.de/919/
二、实现过程
1. GCCN概述
结构如图所示。采用CVP-MVSNet作为主干网络,给定1张参考图像和N张源图像:
- 首先,建立一个从高到低分辨率的图像金字塔。然后,利用FPN提取特征。接下来,采用代价体金字塔结构,在各个级别共享权重。该操作可以用低分辨率图像进行训练,并且在推理过程中仍然可以处理任何高分辨率图像。最后,通过3D CNN回归代价体,并估计最终的深度图。
- GCCN引入了全局上下文交互模块(GCIM),该模块主要包括两个关键点:局部细节提取和全局特征获取。这种组合不仅可以防止网络变差,还可以捕捉到底层语义特征与高层结构特征之间的长距离依赖关系。因此,特征图像包含了丰富的局部和全局特征信息。
- GCCN在3D CNN回归代价体计算中引入了一种有效的上下文特征互补学习模块(CCLM)策略,可以互补学习两个不同深度的输入代价体的特征。最后,通过用像素级损失约束深度图。

2. 全局上下文交互模块(GCIM)
GCIM模块可以有效地结合局部和整体特征,提高网络在二维特征提取阶段的性能。如下图所示,利用卷积神经网络(CNN)在下面的分支中提取局部细节。同时,运用自注意力来学习另一分支的整体信息。最后,根据通道的重要性,采用SE融合模块,更好地整合局部依赖特征和长距离依赖特征的互补特征。为了防止网络受损,GCIM基于跳跃连接和自注意力机制,防止网络过拟合。

3. 上下文特征互补学习模块(CCLM)
CVP-MVSNet,其3D代价体回归网络采用标准的3D CNN U型网络,过程分为编码(下采样)部分和解码(上采样)部分。编码阶段和解码阶段相同深度的3D 代价体结构采用直连。由于U型结构本身的局限性,先下采样再上采样会导致高级语义信息的削弱和空间信息的丢失,从而影响深度图最终的完整性。为了有效地融合3D代价体并保留不同深度的丰富上下文关系,采用上下文特征互补学习模块(CCLM)。CCLM将两层特征之间更广泛的上下文信息解码为局部特征,从而增强了它们的表示能力。CCLM的具体操作步骤如下图所示。

给定深度不一致的两层3D代价体f eature_x, f eature_y∈C×D×H×W,首先将它们输入一个步幅为1 × 1 × 1的卷积层,分别生成两个新的特征图Xout和Yout。然后,在Xout和Yout的转置之间进行矩阵相乘,并应用softmax层计算空间注意图S−XY。
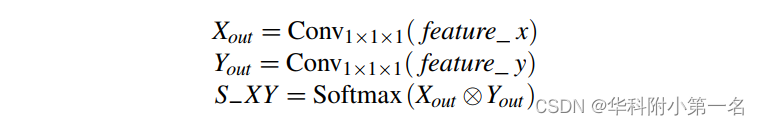
同时,在Yout和S−XY的转置之间进行矩阵乘法得到特征F−XY。最后,我们对feature_y和F−XY执行逐元素求和操作,定义为:
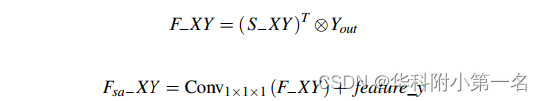
F−XY为输入的3D代价体f eature_x和f eature_y的相关系数矩阵,Fsa−XY为上下文特征互补学习模块后输出的3D代价体。
4. 损失函数
类似于现有的从粗到细的MVS,在每个尺度上应用平均绝对误差(MAE)来监督不同分辨率的深度估计结果,可表示为:

其中Pvalid表示真实深度图中有效的像素集,l表示金字塔图像的层数。在训练中,l被设置为2。将预测的初始深度图上采样至与输入图像金字塔相同的大小,然后逐层累积误差值。
5. 实验
5.1. 实现细节
通过PyTorch实现,在GPU of NVIDIA GeForce GTX 1080Ti和CPU of Intel Core i9-9900K [email protected] GHz上训练。训练时,源图像的数量N设置为2,输入图像的分辨率设置为640×512。Adam对该网络进行了优化。
5.2. 与先进技术的比较

没有Tanks & Temples数据上的结果。