一、论文简述
1. 第一作者:Yuesong Wang、Zhaojie Zeng
2. 发表年份:2023
3. 发表期刊:CVPR
4. 关键词:MVS、3D重建、传统方法、自适应块、无纹理区域
5. 探索动机:传统的基于PM的方法使用传播和局部细化策略来寻找适当的匹配,不需要代价体构建,因此需要很少的内存,但是受限于感受野,难以处理无纹理区域。基于深度学习的方法由于卷积的广泛应用,感受野野比传统方法大得多。AA-RMVSNet和TransMVSNet都是通过引入变可形卷积来扩大感受野。 随着感受野的增大,不可靠像素可以从周围可靠像素中获得足够的几何信息,从而获得更好的深度估计。 尽管如此,如下图所示,较大的感受野导致更多的内存消耗,使得它们难以使用主流GPU设备处理包含大规模无纹理区域或高分辨率图像的数据集。
6. 工作目标:开发一个内存开销小并同时可以很好地处理大规模的无纹理区域的解决方案,
因此本文将可变形卷积的思想迁移到传统的基于PM的MVS机制中。
To develop a memory-friendly solution that can well handle large-scale textureless regions at the same time, in this paper, we transplant the spirit of deformable convolution to a traditional PM-based MVS pipeline.
7. 核心思想:实现了一种基于PatchMatch(PM)的MVS方法,APD-MVS,采用了自适应块变形和基于NCC的匹配度量。We realize a PM-based MVS method, APD-MVS, which adopts our adaptive patch deformation and an NCC-based matching metric.
- For PM-based MVS, we propose to adaptively deform the patch of an unreliable pixel when computing the matching cost, which increases the receptive field when facing textureless regions to ensure robust matching.
- We propose to detect reliable pixels by checking the convergence of matching cost profiles, maintaining the accuracy of detection while being able to find more anchor pixels, which ensures better adaptive patch deformation.
8. 实验结果:
Our method achieves state-of-the-art results on ETH3D dataset and Tanks and Temples dataset with lower memory consumption.
9.论文下载:
https://github.com/whoiszzj/APD-MVS
二、实现过程
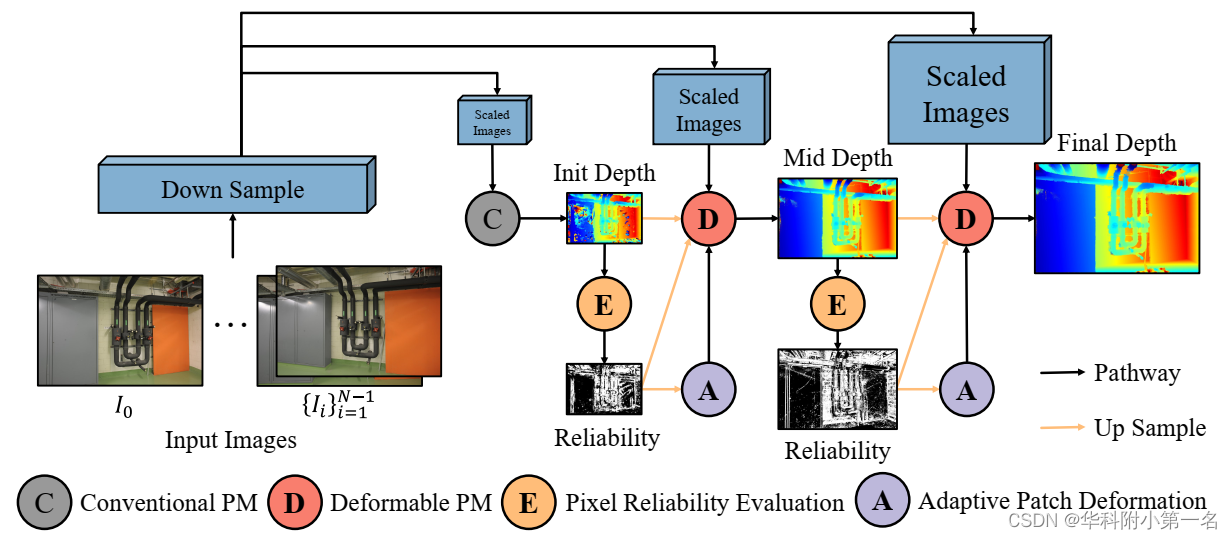
1. APD-MVS概述
对于每个参考图像I0及其源图像Ii,通过缩放得到金字塔结构Li,其中第1层对应原始图像。在第k层,采用传统的PM方法得到初始深度图,然后用它来评估每个像素的可靠性。对于每个不可靠像素,将其对应的块自适应形变,以覆盖足够的高可靠性锚点像素。在中间层,深度通过上采样从前一层继承。根据像素的可靠性,采用不同的匹配策略。对于可靠的像素,应用传统的PM,对于不可靠的像素,匹配策略被替换为可变形的PM。同样,在获得深度后,再次计算像素的可靠性和不可靠像素的可变形块,然后输入到下一层。最后,在第1层,融合深度估计得到密集的点云。此外,对传播和改进模块进行了一些更改,以更好地利用像素的可靠性。
2. 可变形PatchMatch
先回顾传统的PM方法。给定平面假设,可以得到以参考图像中的一个像素为中心的固定尺寸的块在源图像上的投影块。两个块之间的匹配代价通常基于NCC度量来计算。具体来说,假设相机参数为Pi ={Ki, Ri, Ci}的参考图像Ii具有带有相机参数Pj = {Kj, Rj, Cj}的源图像Ij,其中K是内参,
R为旋转矩阵,C为相机中心。对于Ii中具有齐次坐标p = [u, v, 1]T的像素p,设其平面假设为fp = [nT, d]T,其中n为平面法线,d为深度。单应性定义为:

设置一个以像素p为中心的正方形窗口Bp来表示参考块。对于Bp,可以使用Hij在源图像Ij中找到它对应的块Bjp。匹配代价计算为1减去NCC分数:

其中cov(X, Y)=E(X−E(X))E(Y−E(Y)),x和y为X和Y中的颜色值,E(·)为期望值。然后利用视图权重进行聚合,得到考虑所有源图像的m(p, fp, Bp)。
与传统的PM只考虑方形窗口中的像素不同,提出了可变形PM,计算一个不可靠像素在可变形块内的匹配代价,该块覆盖了足够的高可靠性锚点像素。假设p是一个不可靠的像素,具有包含锚点像素S的可变形块。给定平面假设fp,定义可变形PM计算的匹配代价为

其中λ是一个权重值,用于调整锚点像素对中心像素p的影响。Bp的窗口大小设置为w×w,增量设置为θ,Bs的窗口大小与Bp的相同,但增量设置为w/2,这加快了计算速度。实验中,设λ=0.25, w =11,θ=2,|S|=8。
mD(p, fp, S)的计算如下图所示。为了获得鲁棒的局部特征,为每个锚点像素s生成一个局部窗口Bs (s∈S),得到m(s, fp, Bs)。然后对每个窗口Bp,B(s∈S)分别进行计算,最后按权重进行汇总,以保留更多的特征信息。之所以采用权值聚合而不是计算m(p, fp, Ball),Ball=Bp∪{b|s∈S},是因为Ball中包含的不可靠像素通常会超过可靠像素的数量。直接计算m(p, fp, Ball)将导致来自可靠像素的特征信息作为噪声被过滤掉。

可变形PM计算的可视化。绿色的点代表中心的不可靠像素。红色虚线形成可变形块,锚点像素s(i = 1…8)用红色点表示。中心点的匹配代价通过加权聚合形式得到。
3. 自适应块变形
为了方便计算不可靠像素的匹配代价,需要提前对块进行自适应变形。在对块进行变形时,应尽量遵守以下原则:
- 不可靠像素的可变形块应自适应覆盖足够的附近锚点像素;
- 可变形块的深度应该是连续的,确保块中的像素是相关的;
- 锚点像素应该尽量靠近不可靠的像素,以提供更好的拟合变形块;
- 锚点像素应该在各个方向找到,以增加可变形PM的鲁棒性。
因此,提出了一种基于轮辐状方法和RANSAC的自适应块变形算法来满足上述要求。为了便于后续处理,将每个像素点的最近可靠像素提前获取为:

其中Ω为以p为中心的搜索范围(在实验中,将Ω定义为100×100的正方形窗口),R(p)为p的指标,其中1表示可信,0表示不可信。
算法的主要思想是获得ϕ个候选可靠像素{Ci}ϕ,然后通过RANSAC保留适应性良好的像素。当在所有方向上搜索中心像素p的候选像素时,采用类似辐条的方法,将搜索空间分割为具有相同角度的ϕ扇区。对于每个扇区,给定初始搜索半径,在该扇区内生成一个随机方向向量,得到搜索像素q。如果存在有效的N(q),且N(q)在扇区内,标记在该扇区中找到了合适的候选可靠像素。否则,将在此半径下进行多次随机搜索。如果仍未找到候选点,则扩大半径,重复上述过程,如图5所示。该算法确保在每个方向上都有一个可靠的像素,并且候选像素尽可能靠近中心。

在得到{Ci}ϕ后,通过RANSAC算法进行滤波,目的是提高抗遮挡能力。由于方法是基于PM的,因此可变形块中的像素隐含地要求具有相同的平面假设。如果存在不能适合于一个一致平面的候选者,将其视为异常值。因此,每次迭代,随机采样三个候选像素,拟合平面π由它们组成3d点。中心像素需要在这三个候选像素组成的三角形内,确保锚点像素在中心像素的各个方向上。然后,计算π与候选像素对应的三维点之间的距离{Di}ϕ =1。则该随机样本的代价(π)由

其中ε是过滤异常值的阈值,I(·)是使I(true) = 1且I(false) = 0的指示函数,Dp是中心像素p的3D点到拟合平面π的距离。在比较不同选择的代价时,首先考虑α, α越小代表平面拟合越好。
如果两个代价在α维度上相等,则考虑β的效果。经过一定次数的迭代,如果能找到最佳拟合平面πbest(足够多的点分布在平面附近),则从可靠像素点最多可达1 × S ×{Ci|Di≤ε,i = 1…ϕ}根据它们到拟合平面的距离πbest来选择φ。然后形成一个可变形的块。否则,中心像素可能位于非平面区域。在这种情况下,仍然采用传统的PM来获得匹配代价。
为了更好地处理非平面区域,首先放宽平面拟合阈值ε,将其视为平面区域,然后随着优化的进行逐渐缩小拟合阈值,使非平面区域摆脱平面约束。通过这种方法,非平面区域在良好的初始化条件下更容易从可变形的PM中找到正确的深度估计。在实验中,设置ϕ = 32,并将ε场景深度范围逐渐从1%降低到0.5%。

右图是自适应块变形的演示。绿色的点代表中心像素,它周围的蓝色点代表传统的块,红色的点构成可变形块的感受野。左图显示了真实值周围的匹配代价(绿色虚线)。与传统PM相比,变形PM对于不可靠像素具有显著的真值收敛性能。
4. 像素可靠性评估
现在只剩下一个问题:如何评估像素的可靠性。一开始就把像素严格划分为可靠和不可靠两类是不合适的。随着优化的进行,更多像素的深度估计将落入不存在匹配模糊的搜索范围,使其足够稳定,可以作为可变形PM的锚点像素。更多的锚点像素可以带来更好的拟合变形块,进一步提高深度估计精度。因此,提出了一种在优化过程中检查匹配代价分布的像素可靠性评估机制。具体而言,对于每个像素,使用当前深度估计附近的传统PM计算的匹配代价来形成匹配成本曲线。然后通过检查轮廓的谷值和收敛性来评估可靠性。
由于深度范围在不同的场景中是不同的,直接在其上采样不具有普适性,所以在视差空间下进行采样操作。对于参考图像I0中的每个像素p,给定平面假设fp= [nT, d]T和相机焦距f,则平均视差计算为:

其中Sgood是{Ii}的子集,由联合视图选择,bIj定义为参考图像I0与源图像Ij之间的基线长度,E(·)为期望值。然后通过传统的PM计算匹配代价,得到曲线图P(D)。

其中B是以p为中心的常规方形窗口,δ是样本范围。在获得匹配代价曲线后,可以根据匹配代价曲线的几何性质来评估像素的可靠性,如算法1所示。该算法的主要思想是计算全局最小值与其他局部最小值的显著性。对于可靠像素,全局最小值应该比不可靠像素的最小值更有区别。

将像素分为两种状态:可靠和不可靠的。函数FindLMins的目标是在概要文件中找到局部最小值,而FindGMin的目标是找到全局最小值。参数t1, t2, t3为阈值,在实验中分别设置为0.50 0.15和0.20。η (< δ)是判断深度估计优化是否收敛的阈值。随着优化的进行,η将动态减小,使可靠像素的确定更加严格。在实验中,设δ = 30,η=max(6−2 * i, 2),其中i为迭代次数。
5. 传播和细化
在[37]的基础上改进了传播和细化过程,以更好地利用不可靠像素的可变形块信息。在对不可靠像素进行联合视图选择时,直接使用可变形块中的锚点像素来计算的代价矩阵M,提高了视图选择的鲁棒性。
在传播过程中,传播到不可靠像素的候选平面假设被锚点像素的平面假设所取代。此外,在细化步骤中,将可变形块的拟合平面假设加入到候选点中,加快了收敛速度。上述方法使得不可靠像素的深度估计部分依赖于可靠像素的深度估计。因此,在每次迭代中先处理可靠的像素,然后处理不可靠的像素。
当真正可靠像素的深度估计优化尚未收敛时,即算法1中的|DGM−D'|>η ,可靠像素会像不可靠像素一样采用可变形的PM。这一方面是为了利用周围的信息来加快收敛速度,另一方面是为了防止这类可靠像素损害不可靠像素的自适应patch变形。然而,强加的平面约束将导致深度估计在这类像素的精度下降。因此,在优化结束时添加了一个局部优化。通过在原始深度附近进行小采样,根据传统PM的代价值获得了最优深度。如果最优深度的代价远小于原始深度的代价,则采用最优深度,在真正可靠的像素处提高精度,而对真正不可靠的像素影响不大。
6. 实验
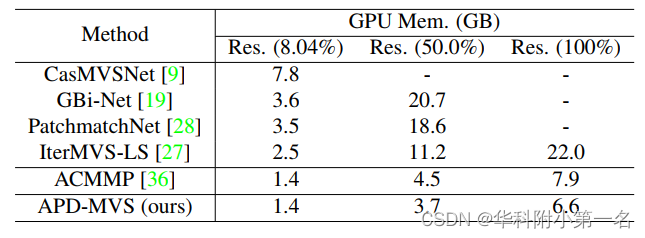
6.1. 内存开销
在NVIDIA TITAN上测试内存成本。基于学习的方法仍然不能很好地平衡内存开销和重建结果。相反,传统方法通常不会消耗太多GPU内存。CasMVSNet是一种广泛使用的基于学习的基线,而PatchmatchNet、GBi-Net和IterMVS是为了减少内存消耗而设计的。与最新的传统方法ACMMP相比,这些基于学习的方法的性能仍然不尽人意。考虑到所有这些最新的方法,APD-MVS可以实现更低的内存消耗和更好的重建效果。

6.2. 与先进技术的比较

