一、论文简述
1. 第一作者:Wanjuan Su
2. 发表年份:2023
3. 发表期刊:AAAI
4. 关键词:MVS、3D重建、从粗到细、改进上采样、光度一致性监督
5. 探索动机:现有的基于学习的MVS方法仍然难以在薄结构和目标边界处恢复深度,难以平衡效率和泛化能力。
基于3D卷积的代价体正则化通常会由于其平滑特性导致物体边界的过度平滑问。此外,由于采样深度假设是离散的,并且假设的数量有限,很难捕获薄结构和目标边界的精确深度,导致估计深度图中的模糊伪影。在广泛使用的从粗到精的架构中,这一问题进一步加剧。该架构首先在低分辨率下使用粗深度假设估计初始深度图,然后在高分辨率下使用更精细的代价体逐步细化初始深度图。由于初始深度假设非常稀疏,精细阶段的深度搜索范围在前一阶段估计的深度图附近,因此在第一阶段很难恢复目标边界处的深度,并且初始深度图中的误差将传播到精细阶段。此外,在粗精结构下,现有方法一般采用简单的双线性上采样,将低分辨率深度图上采样到高分辨率深度图,从而产生交叉边缘插值。这进一步加剧了估计深度图中的模糊伪影问题。模糊伪影不仅降低了深度图的精度,而且破坏了视图之间的几何一致性,降低了重建点云的完整性。

深度域和图像域的误差图对比,其中误差图是利用GT与估计深度图之间的绝对误差或者GT与估计深度图合成的图像得到的。GT图像中存在没有真实深度的像素点,合成图像中存在无效像素点,在误差图和合成图像中用0掩盖它们,在GT和误差图中显示为白色,在合成图像中显示为黑色。L和H表示误差的高低。
6. 工作目标:为了解决上述问题,原文写的很明确。
7. 核心思想:By embedding the proposed HEPR module and CPC loss into our lightweight cascade framework, an Efficient edgePreserving multi-view stereo Network (EPNet) is presented in this paper which can ensure high performance while maintaining high efficiency.
- We present a novel efficient edge-preserving multi-view network that exploits context information in the image for high-quality edge-aware depth estimation with friendly memory and run-time consumption;
- We propose a hierarchical edge-preserving residual learning module to perform the depth refinement which supports blur-free depth upsampling;
- We introduce a cross-view photometric consistency loss to effectively enhance the gradient flow of detailed regions during training.
8. 实验结果:
Extensive experiments show that our method achieves state-of-the-art performance with fast inference speed and low memory usage. Notably, our method tops the first place on challenging Tanks and Temples advanced dataset and ETH3D high-res benchmark among all published learning-based methods.
9.论文下载:
二、实现过程
1. EPNet概述
MSDE采用轻量级级联结构和从粗到精的策略,以高效的方式估计深度图。主要由两个模块组成:Multi-Scale Depth Estimation(MSDE)模块和HEPR模块。HEPR嵌入到MSDE中,逐步实现边缘保留深度改进。
- 首先使用共享权重的二维U-Net提取多尺度图像特征。2D U-Net的编码器和解码器由多个残差块组成。
- 然后,逐阶段深度估计。首先通过单应性变化构建8个组的组相关双视图代价体Ci。在第一阶段对使用双层3D CNN,然后进行Sigmoid激活和最大池化层,获得每个源视图的可见性图Vi,用于在所有阶段以加权融合的方式将两视图代价体聚合为统一的代价体。
- 与以往直接使用双线性采样将估计深度图上采样到下一个尺度的方法不同,本文采用HEPR模块对估计深度D^o进行进一步改进和上采样。这样可以得到边缘保留的深度D^r,作为确定下一阶段深度采样范围的依据,深度假设采样策略类似CasMVSNet,对深度假设进行均匀采样,深度采样范围逐渐减小,深度采样次数逐渐减少。与大多数基于学习的方法(下一阶段估计的深度图的分辨率通常是前一阶段的两倍)不同,EPNet在第0阶段和第1阶段、第2阶段和第3阶段估计的深度图的分辨率是相同的,因此可以在不增加大量内存和运行时间开销的情况下尽可能地增加深度假设样本的数量。在这种情况下,EPNet由5个阶段组成,最粗阶段估计深度分辨率为1/8H×1/8W,最细阶段估计深度分辨率为1/2H×1/2W。避免在全分辨率下估计深度图可以大大减少内存和运行时间的消耗,这也是一些方法效率高的主要原因。
- 在训练过程中,将CPC损失与L1损失一起用于监督MSDE,以增强细节结构的梯度流动。

2. 分层边缘保留残差学习
仅基于几何信息估计深度的缺点是估计深度图的某些区域与参考图像的上下文不对齐,即深度图中存在模糊伪影。此外,从粗到精的结构依赖于粗阶段的估计,存在误差累积和模糊伪影加剧的问题。通过使用HEPR模块对从粗到精的结构的中间输出执行边缘保留细化来解决这些问题。具体来说,通过逐步学习深度残差,以帮助粗糙估计在参考图像的指导下以更高的分辨率恢复精细细节。
如图(b)所示,HEPR模块首先采用上下文编码器提取参考图像的多尺度上下文特征,用于引导深度残差学习网络学习精细细节。然后,应用深度残差学习网络对MSDE的中间输出进行分层改进,从而逐步恢复复杂结构。深度残差学习网络的输入是深度特征提取网络提取的深度图特征和上下文编码器提取的上下文特征。深度特征提取网络有一个三层的浅CNN,接着是一个步长为2的反卷积层,从归一化深度图中提取特征。深度图归一化为:

其中,D^n表示归一化深度,D^o表示MSDE估计的深度,mean(·)和std(·)表示计算深度图的平均值和标准差。
深度残差学习网络主要由一个编码器和一个解码器组成,通过跳跃式连接将上下文特征和深度图特征耦合起来。深度残差学习网络的编码器和解码器由多个残差块组成,以学习更好的耦合。最后,将输出深度残差并添加上采样和归一化后的深度图中,生成更高分辨率的边缘保留深度图,该过程可表述为:

其中,D^rn表示精细化归一化后的深度图,Up(·)表示使用双线性上采样将输入上采样到其原始大小的两倍,∆D^表示学习到的深度残差。D^rn未被原始均值和标准差归一化,边缘感知深度图D^r为:

3. 跨视图光度一致性损失
跨视图光度一致性的核心思想是通过参考视图GT得到的合成图像与基于源视点图像估计深度的差值,放大细节区域的梯度流。对于参考图像X0中深度值为d的像素pj,其在源视图中的对应像素p^j计算为:

经过上述变换,由第i个源图像基于参考视图深度图D合成的图像I0,i,通过可微双线性采样得到:

在此过程中还生成一个二进制掩码Mi,表示合成图像中的无效像素I0;i,即投影到图像外部区域的像素。在这种情况下,跨视图一致性是:

分别表示第i个源图像基于GT深度图和估计深度图合成的图像,N表示视图数,Mi表示有效像素。使用深度域的CPC损失和L1损失来约束EPNet的MSDE模块:

其中Ds gt和D^os分别表示第s阶段的gt和估计深度图,λs和µ是权重系数。HEPR部分仅受深度域L1损耗的约束,因此EPNet的总损失表示为:

式中D^s r为HEPR在第s阶段的深度输出,ηs为第s阶段的权重系数。
4. 实验
4.1. 实现细节
实验在一个GeForce RTX 2080Ti GPU上进行。EPNet首先在DTU上进行训练,然后在BlendedMVS上进行微调。在训练时,DTU和BlendedMVS的图像分辨率设置为640 × 512, DTU为5,BlendedMVS为7。EPNet由5个阶段组成,每个阶段的深度假设数分别为32、16、8、8、8,相应的深度采样范围在第二阶段衰减0.5,其余阶段衰减0.25。
对于包含HEPR模块的模型,先单独训练MSDE 1个epoch,然后单独训练HEPR模块2个epoch来预热该分支,最后再训练完整模型9个epoch,在第8、10、11个epoch的初始学习率0.001下降了一半。
4.2. 与先进技术的比较
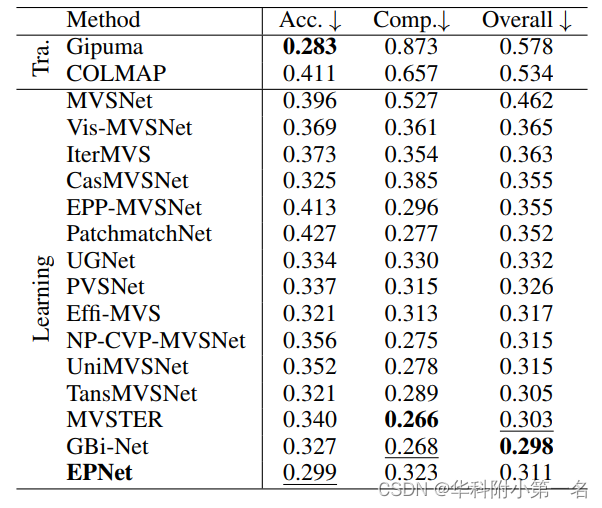
视图数为11,图像分辨率为1920×1024
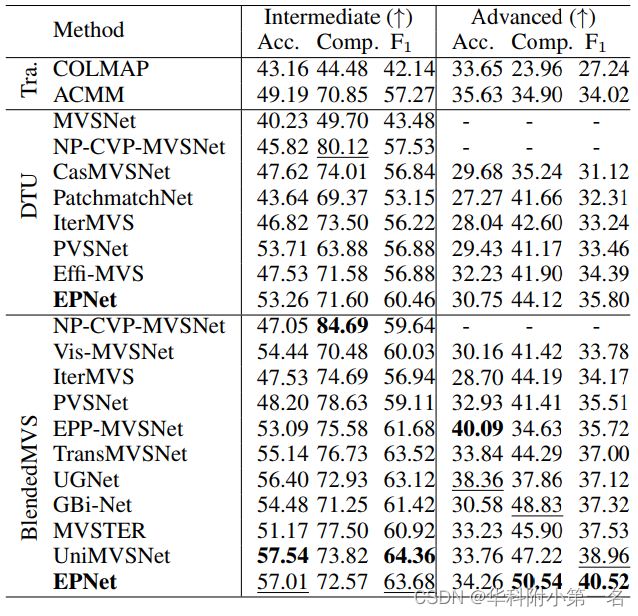
The number of views is 7 for the model trained on DTU and 10 for the model fine-tuned on BlendedMVS, the resolution of images is 2432 × 1600.

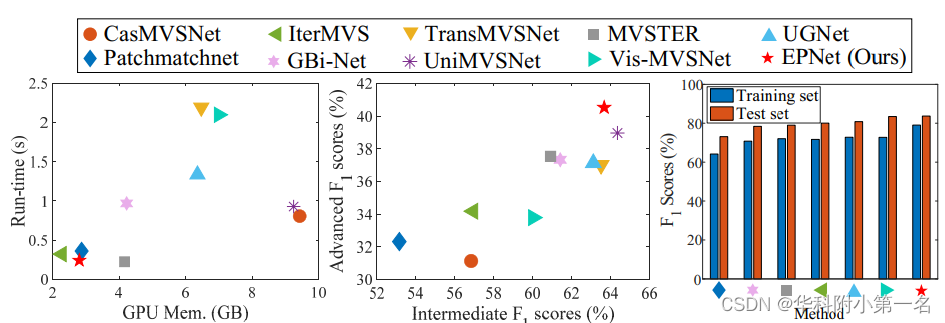
4.3. 内存及时间
EPNet消耗大约2753 MB和0.2298s来推断DTU上的深度图。