一、论文简述
1. 第一作者:Khang Truong Giang
2. 发表年份:2022
3. 发表期刊:ICLR
4. 关键词:MVS、3D重建、曲率、动态尺度
5. 探索动机:虽然目前的方法显著提高了MVS的性能,但它们的特征提取网络存在一些缺点,降低了三维重建的质量。
- First, they observed a restricted size of receptive fields from the fixed size of convolutional kernels. This leads to difficulty in learning a robust pixel-level representation when an object’s scale varies extremely in images. As a result, the extracted features cause the low quality of matching costs, especially when the difference of camera poses between reference and source images is large.使用固定大小的卷积核获取大小受限的感受野,当对象在图像中的比例变化极大时,难以提取鲁棒的特征表示。这会降低代价匹配的质量,特别是当参考图像和源图像间相机姿态差异较大时。
- Second, MVS networks are often trained on low-resolution images because of limited memory and restricted computation time. Therefore, the existing feature extraction methods utilizing fixed-scale feature representation on deep networks could not generalize to high-resolution images in prediction; the MVS performance is downgraded on a high-resolution image set.为了减少内存消耗和推理时间,MVS网络通常在低分辨率图像上训练。将低分辨率训练的网络推广到高分辨率图像,MVS性能会降低。
6. 工作目标:提出了一种新的特征提取网络,可以适应不同的物体尺度和图像分辨率。
7. 核心思想:we endeavor to propose an Attention Aware Cost Volume Pyramid Multi-view Stereo Network (AACVP-MVSNet) for 3D reconstruction.
- 提出了一种曲率引导的动态尺度卷积(CDSConv),它根据图像的法向曲率(沿极线方向)为每个像素选择合适的块尺度,以学习动态尺度特征。该操作通过在多个候选尺度中计算近似的表面法曲率,并通过轻量级分类网络选择适当的尺度来实现。
- 提出了一种曲率引导的动态尺度特征网络(CDSFNet),它由多个CDSConv层组成,用于在像素级学习鲁棒的表示。CDFSNet评估最优的像素尺度学习特征,尺度是根据结构、纹理和极线约束自适应选择的。它训练了更多的区分性特征,用于精确匹配代价计算。
- 提出了用于MVS深度估计的CDS-MVSNet。CDS-MVSNet通过处理图像匹配过程中的模糊性和可见性来执行精确的立体匹配和代价聚合。它由级联网络结构组成,用于从粗到细的估计高分辨率深度图。对于每个级联,它根据CDSFNet的输出特性来构造代价体,通过使用适当的像素比例来减少匹配模糊度。应用法曲率信息(该信息隐式编码特征的匹配能力)估计像素级的可见性,以消除噪声和错误匹配,提高立体匹配的性能。并在保持重建质量的同时处理半分辨率图像,显著减少了运行时间和内存消耗。
8. 实验结果:
Extensive experiments showed that the proposed method outperforms other methods on complex outdoor scenes. It significantly improves the completeness of reconstructed models. As a result, the method can process higher resolution inputs within faster run-time and lower memory than other MVS methods.
9.论文&代码下载:
https://arxiv.org/pdf/2112.05999.pdf
https://github.com/TruongKhang/cds-mvsnet
二、实现过程
1. 法曲率
法向曲率用于估计曲面在特定点沿特定方向弯曲的程度。设p(X,σ)为以像素X为中心的块,其尺度σ与窗口大小成正比。L(X,Isrc)表示为参考图像I ref上的极线,该极线穿过X并与源图像I src相关。为了减少I ref中的p和I src中的正确面片p0之间的匹配模糊度,当对应的块p(X,σ)与其沿极线L的周围块线性相关性较小时,应选择适当的尺度σ。 根据尺度空间理论,面片p(X,σ)可以被视为图像表面上的一个点,用比例σ表示。因此,如果以该比例表示的图像表面在X点沿极线方向显著弯曲,则该比例σ是立体匹配的最佳选择。这需要计算面片p(X,σ)沿极线L的方向ω=[u,v]T的法曲率。该公式可以用图像表面的一阶导数和二阶导数表示:

其中,Ix,Iy,Ixx,Ixy,Iyy分别是图像I沿x轴和y轴的一阶和二阶导数。
2. 曲率引导的动态尺度卷积CDSConv

给定K个不同大小的卷积核对应K个候选尺度,CDSConv的目的是为每个像素X选择合适的尺度。因此,它可以根据所选择的尺度,从输入Fin中产生一个鲁棒的输出特征Fout。上图显示了CDSConv的整个过程,包括以下步骤:
- CDSConv估计K候选尺度上的近似法向曲率。
- 执行尺度选择步骤,从K个估计曲率中输出最优尺度(计算每种尺度的权重);这种选择是通过一个由两个卷积块和一个Softmax激活输出组成的分类网络来实现的。
- 通过使用加权和得到输出特征。
2.1. 法曲率计算
以X为中心沿着极线ω=[u,v]T方向的块的法曲率公式可以改写为:

式中I(X,σ)=I(X)*G(X,σ)是像素X在图像尺度σ的图像强度,通过图像I与窗口大小为σ的高斯核G(X,σ)卷积得到。导数Ix、Iy、Ixx、Ixy和Iyy可以通过原始图像I与高斯核G(X,σ)导数之间的卷积来计算:

式中,*是卷积算子。
2.2. 法曲率近似
直接将法曲率计算公式嵌入深度神经网络,有两个主要缺点:由于计算导数Ix、Iy、Ixx、Ixy和Iyy有五个卷积运算,计算量很大。当像素X是潜在特征Fin(X)而不是图像强度I(X)时,计算曲率是不可行的。基于这些原因,推导出了法曲率的近似形式,它降低了计算成本,并且可以处理高维特征输入。注意到曲率曲线σ和导数Ixiyj与高斯核G成比例。此外,使用分类网络从曲率输入中自动选择面片尺度。因此,可以通过重新缩放核G来对曲率进行归一化,将高斯核限制在一个小范围内,即G(X,σ)<<1。因此,导数Ix、Iy、Ixx、Ixy和Iyy也远小于1。可以用1来近似法曲率计算中的分母:

2.3. 可学习的法曲率
为了使上式适用于高维图像特征Fin(X,σ),使用可学习的核,而不是使用高斯核的固定导数。特别地,对于每个尺度σ,引入三个可学习的卷积核Kxxσ、Kxyσ、Kyyσ来分别替换Gxx、Gxy和Gyy。这些核函数适应输入特征,近似计算图像表面的二阶导数。在训练端到端网络时,它们通过反向传播进行隐式训练。这些核的权重需要限制在一个较小的值Kσ<<1,通过在损失中添加一个正则项来实施这一约束。提出了可学习的法曲率,其公式如下(以矩阵形式编写)

其中Kσ是可学习核,||kσ||→ 0,Fin是输入特征。
2.4. 尺度选择
据观察,小范围内无法获取足够的上下文信息来学习区分特征,尤其是在低纹理区域。同时,大尺度平滑了纹理丰富区域的局部结构。通过使用加权和,得到输出特征:

此外,还可以得到尺度选择下的法曲率:

2.5. 示例说明
CDSConv预测自适应块尺度,在薄结构或纹理丰富的区域,比例较小,在无纹理的区域,比例较大。此外,根据图像分辨率,尺度是动态的。CDSConv通常在低分辨率图像中生成小比例值(蓝色区域较多),在高分辨率图像中生成大比例值(黄色区域较多)。

3. 曲率引导的动态尺度特征网络CDSFNet

CDSFNet用作MVS框架的特征提取步骤,由多个CDSConv层组成,而不是标准的卷积层。通过扩展搜索尺度空间,CDSFNet可以为每个像素选择最优尺度来学习鲁棒表示,从而减少匹配模糊。
体系结构。CDSFNet是一种类似于Unet的结构,有三个层次的空间分辨率,以适应从粗到细的MVS框架。给定参考图像I0和N个源图像{I1,I2,…,IN},以及相应的相机参数{Q0,…,QN},可以基于极线几何计算每个参考源图像对{(I0,Ii)}Ni=1的极线对{(e0,i,ei)}Ni=1。输出:三种分辨率的特征图及法曲率。
理解CDSFNet。CDSFNet的主要目标是选择像素级尺度进行鲁棒特征提取。尺度动态变化,取决于图像对象的细节和极线约束,即参考和源图像之间的相对相机姿态。为了降低计算复杂度,CDSConv层中的候选尺度数量应该较小,只使用2或3个候选尺度。当多个CDSConv层堆叠在CDSFNet中时,搜索尺度空间会大大扩展。下图显示了从CDSFNet的前两层粗略估计的每个像素的块规模或窗口大小。对于每个参考视图和源视图,分别绘制参考和源尺度图。CDSFNet的两个主要优点如下:首先,丰富纹理、薄结构和近边缘区域的估计尺度往往较小,而无纹理区域的估计尺度较大。其次,根据视点(图a)和参考视图和源视图之间的相对相机姿势(图b),尺度发生变化。在图a中,视点越近,估计的尺度越大。在图b,当相机姿态差异不大时,参考尺度图与源尺度图相似。反之,当差异较大时,则改变参考视图的尺度图以适应源视图,即红圈所示的源视图。这是CDSFNet的一个优势,因为它基于参考和源视图之间的极线约束来估计尺度。

4. 其他细节CDS-MVSNET
CDS-MVSNet从参考I0和N个源图像Ni中预测深度图。采用CasMVSNet的级联结构,以从粗到细的方式预测深度图。每个阶段通过基于CDSFNet的特征提取、代价体构建及正则化和深度回归三个步骤估计深度。
由于特征提取的鲁棒性,与其他级联MVS方法相比,CDS-MVSNet可以在更粗糙的阶段产生更准确的深度。因此,与CasMVSNet不同的是,CDS-MVSNet仅使用三步MVS计算半分辨率图像的深度,然后在最后阶段将深度上采样到原始分辨率,通过二维CNN进行细化,得到最终深度,大大减少计算时间和GPU内存需求。

4.1.鲁棒的特征提取
为每一对参考图像和原图像提取特征对,参考图像的特征是随源图像变化的。
4.2. 代价体聚合
对每个特征对,在深度假设d处使用内积计算两视图的代价体。
我们还利用公式7中由CDSFNet估计的法曲率图NCest。使用法曲率,对所有特征对进行聚合。法向曲率可以隐式地提供关于表面层次细节的信息。例如,法向曲率小的像素表示它属于一个大的无纹理区域。在这种情况下,其特征是不匹配的,需要从代价聚合中消除,以减少正则化步骤中的噪声。估计的法曲率隐含地编码了学习特征的匹配能力。

式中,NCesti是与源视图i相关的参考视图的估计法曲率,Hi是根据两视图匹配代价体Vi计算的熵。Vis(.)是一个简单地2D CNN,预测视角i的权重Wi,最后,通过加权平均值计算总代价。
5. 损失函数
5.1. 特征损失:用于有效训练CDSFNet.给定参考图像的真实深度Dgt,将源图像的特征通过该深度图扭曲,然后计算匹配代价V(Dgt)。将该图标记为正,其分类标签定义为c=1。为了生成负标签c=0的匹配代价,随机采样Dgt周围的Nd相邻深度Dneg,然后计算这些深度的匹配代价V(Dneg)。最后,利用二元交叉熵定义特征损失。添加正则化项,以将CDSFNet的卷积权重、wCDSF和估计法曲率NCest限制在一个小范围内。最终特征损失定义为:

其中sig(.)是Sigmod函数,M是像素总数,λ1=0.01和λ2=0.1是正则化超参数。
5.2. 深度损失
采用L1损失。
5.3. 最终的损失函数

6. 实验
6.1. 实现细节
输入图像分辨率:DTU和BlendedMVS数据集都使用640×512。视角数:3。深度假设平面数:{48,32,8},深度间隔:{4,2,1}。epoches:30。两个实验场景:在DTU训练集上训练模型,然后在DTU测试集评估,之后在BlendedMVS数据集上对这个预先训练好的模型进行15个epoch的微调,学习率为10e-4.之后对tanks and temples数据集进行评估。其次,在DTU和BlendedMVS数据集上训练了一个单一模型,并使用该模型进行评估。由于DTU中所有场景的摄影机轨迹都很简单,因此还使用了具有不同相机轨迹的BlendedMVS数据集进行训练。
4.2. 与先进技术的比较
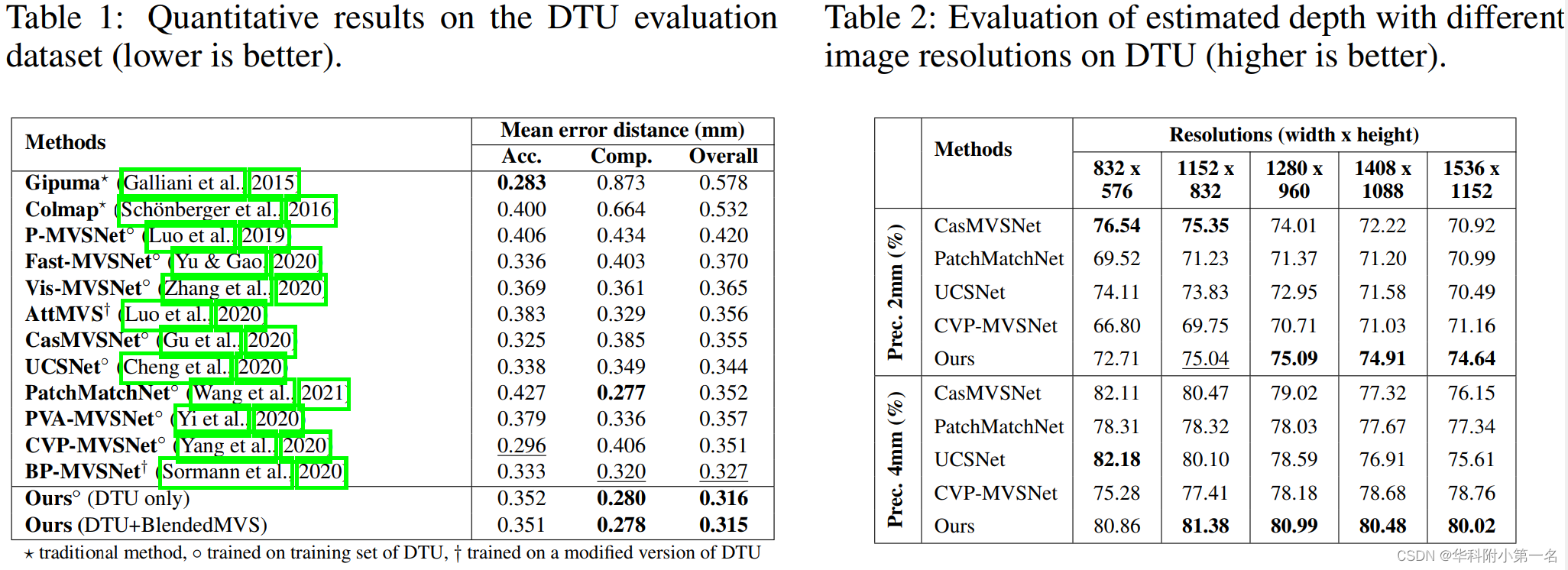
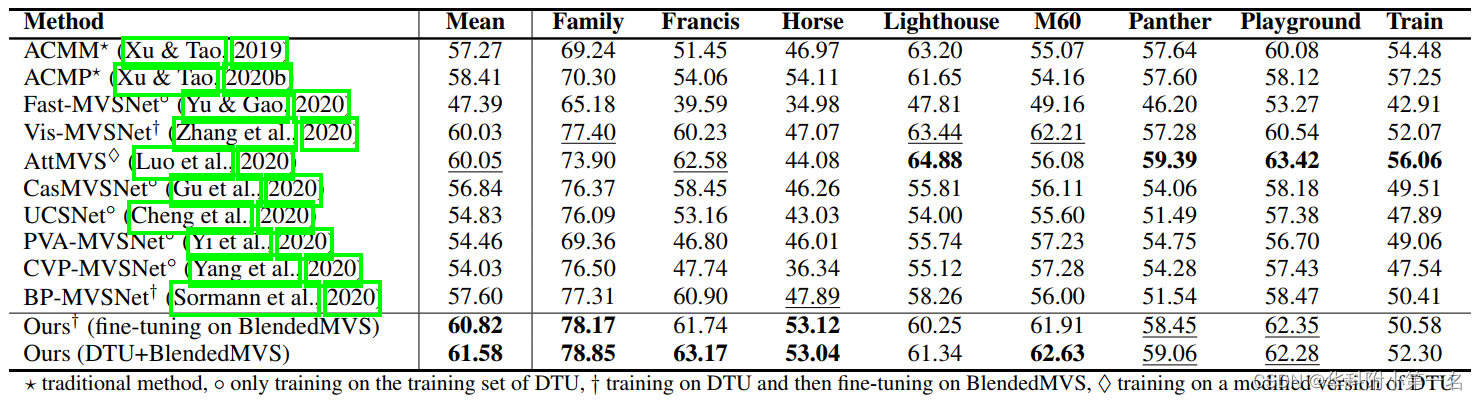

GPU内存和运行时长,DTU集与输入分辨率。原始图像分辨率为1600 × 1200(100%),最高分辨率1536 × 1152(95.2%)。