一、论文简述
1. 第一作者:Yisu Zhang
2. 发表年份:2023
3. 发表期刊:CVPR
4. 关键词:MVS、3D重建、符号距离场
5. 探索动机:像素深度估计仍存在两个棘手的缺陷。一是无纹理区域的估计置信度较低。二是物体边界附近的许多异常值。这主要是因为表面通常被视为一组不相关的采样点,而不具有拓扑结构。由于每条射线只与一个表面采样点相关联,因此不可能注意到表面的相邻区域。如下图所示,每个深度值的估计仅受一个表面采样点的约束,无法利用周围表面进行推断。然而,在没有纹理的区域和物体边界中,如果没有更广泛的表面信息,很难进行推断。因此,太小的感知范围限制了现有的基于学习的MVS方法。
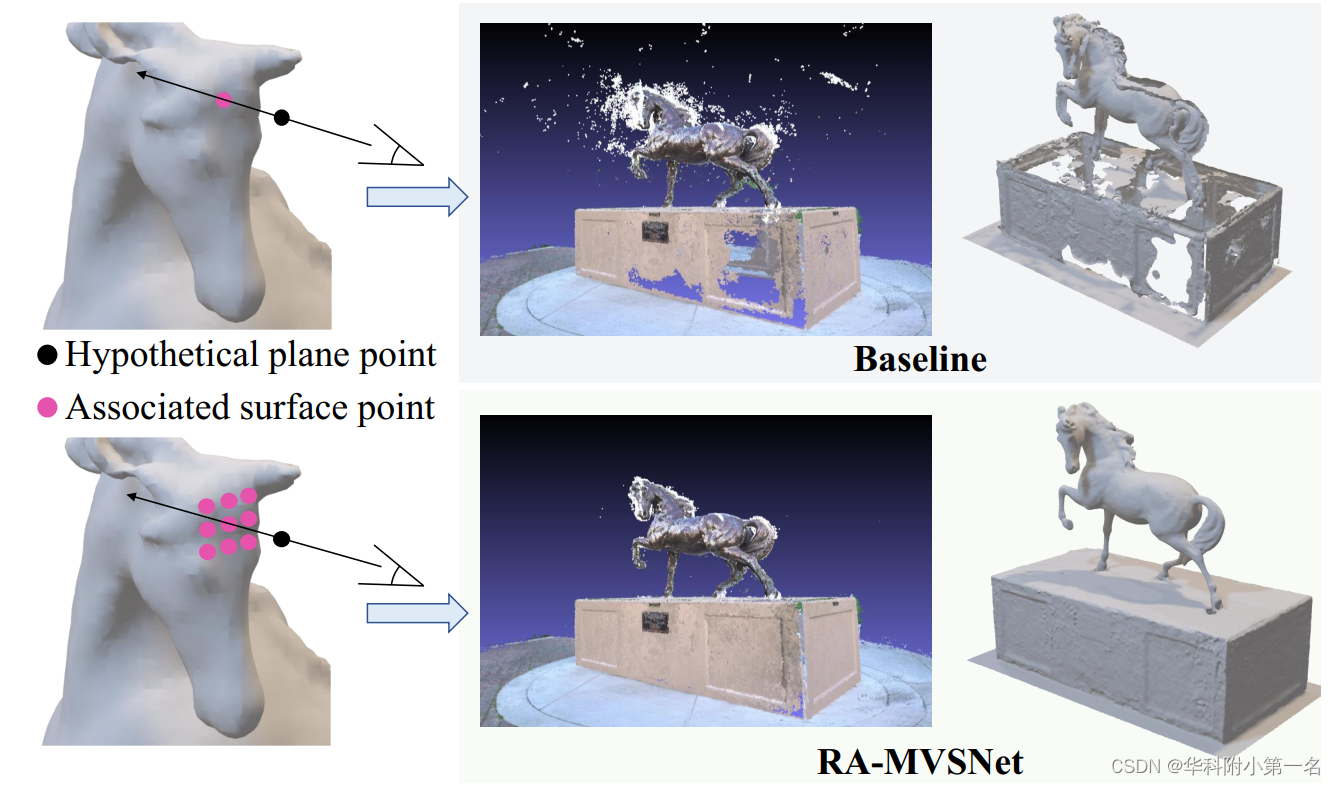
6. 工作目标:通过利用表面信息解决上述问题。
7. 核心思想:提出了一种新的RA-MVSNet框架,该框架能够通过点对面距离使每个假设平面与更宽的表面相关联。因此,该方法能够在无纹理区域和物体边界推断周围表面信息。
- We introduce point-to-surface distance supervision of sampled points to expand the perception range predicted by the model, which achieves complete estimation in textureless areas and reduce outliers in object boundary regions.
- To tackle the challenge of lacking the ground-truth mesh, we compute the signed distance between point sets based on the triangulated mesh, which trades off between accuracy and speed.
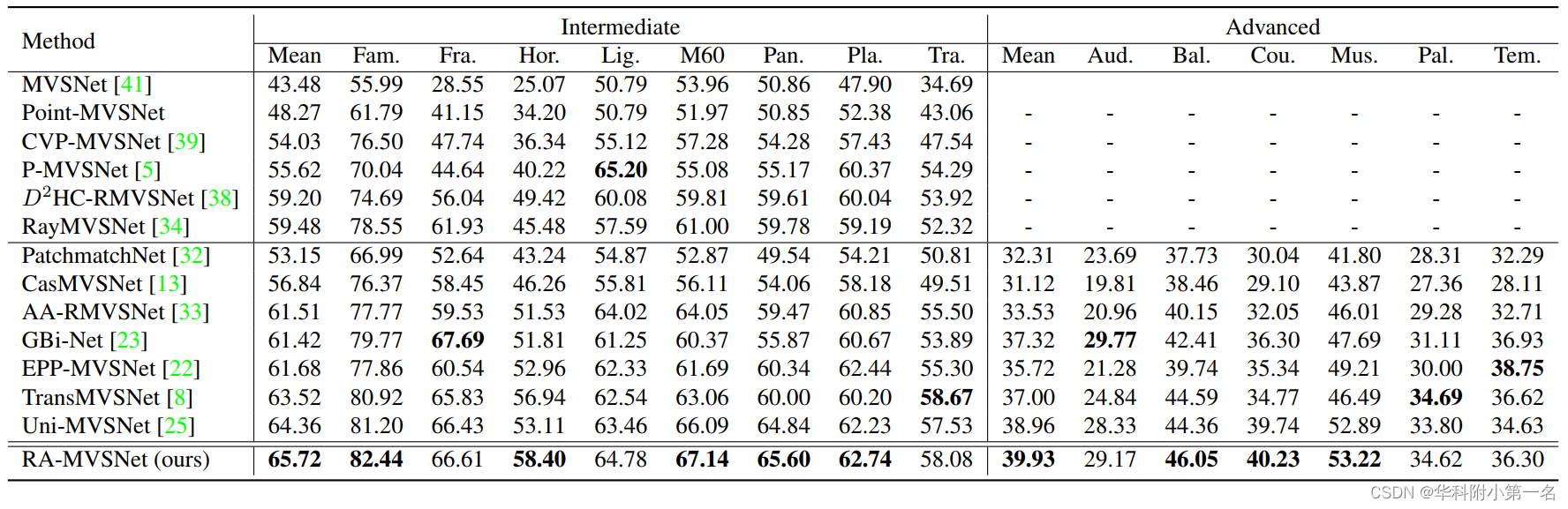
8. 实验结果:
Experimental results on the challenging MVS datasets show that our proposed approach performs the best both on indoor dataset DTU and large-scale outdoor dataset Tanks and Temples.
9.论文下载:
https://arxiv.org/pdf/2304.13614.pdf
二、实现过程
1. RA-MVSNet概述
总体框架主要包括代价体构建、多尺度深度图和符号距离预测、真值处理三个部分,由两个分支组成。第一个分支预测概率体,第二个分支估计符号距离体。RA-MVSNet融合两个分支可以得到过滤后的深度图,而SDF分支可以生成隐式表示。由于点到面距离监督采用了一个额外的分支,通过代价体来计算采样点在表面周围的符号距离,因此很容易添加到现有的基于学习的MVSNet方案中,只需稍加修改。采用了级联MVSNet为基准,并使用两个分支Cas-MVSNet,分别预测深度和符号距离。
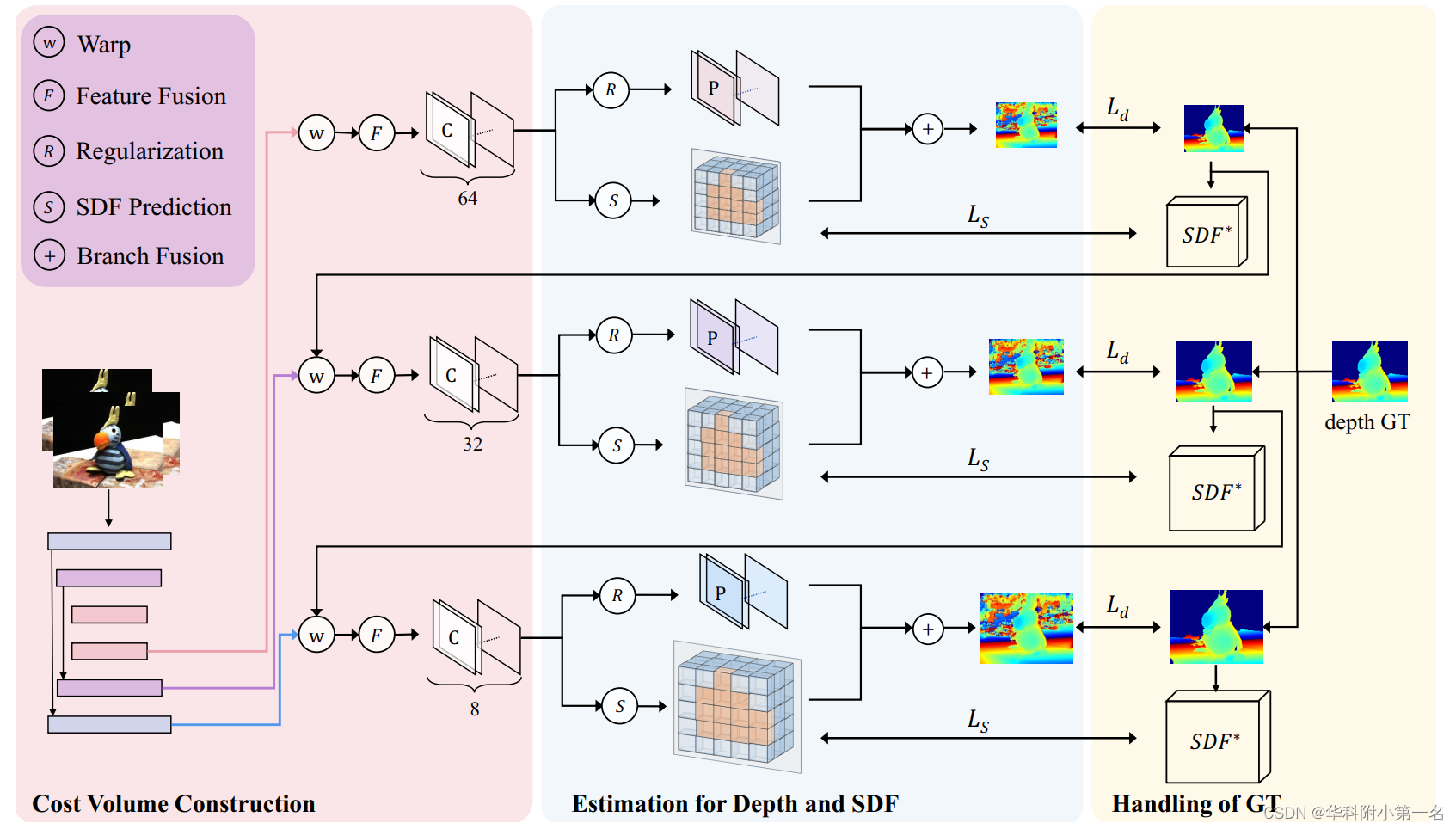
2. 代价体构建
依据MVSnet,通过单应性变化构建。采用递归特征金字塔(RFP)作为图像编码器共享权值提取三个尺度的特征。 为了处理任意数量的源图像,采用自适应策略聚合了所有的特征Vi到单个代价体C∈D×C'×H'×W',用几个3D CNN层来预测逐像素加权矩阵Wi。最终的代价体可以计算如下:
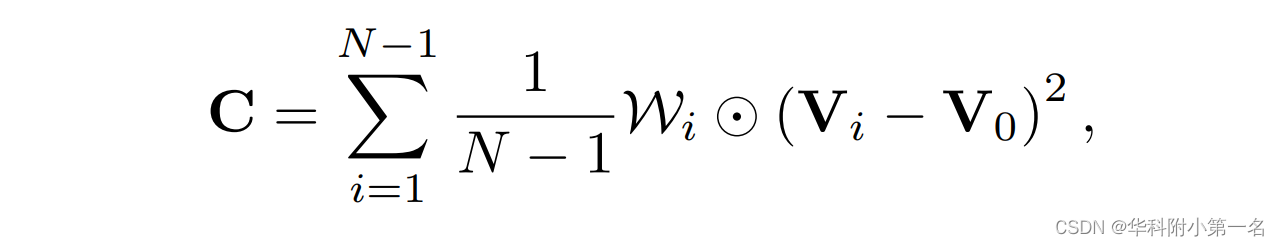
其中C为参考视图的代价体。⊙表示逐元素的乘法。Vi和V0是使用图像编码器从源图像和参考视图中提取的特征。
3. 符号距离监督
点到面的距离通常表示为SDF(signed distance field 符号距离场)。这种隐式表示的核心是计算表面附近采样点到物体的距离。因此遵循SDF的思想,构建一个距离体来预测点到面的距离,从而利用隐式表示的优势。
对于聚合了参考视图和源视图特征的三维代价体,通常采用正则化网络来获得概率体P, P被视为不同深度假设平面的权值:

其中Fsoftmax是基于softmax的3D CNN正则化网络。距离体S表示这些假设平面的带符号距离:

式中Ftanh为基于tanh的3D CNN正则化网络。由于离表面较远的点通常不利于重建,采用tanh作为距离体的激活层。因此可以关注附近的采样点。
由于引入了距离的预测,需要将深度图的真值扩展到符号距离场。因此,深度图只包含距离为0的采样点,缺乏表面周围点的地面真实性。
对于代价体C的每个假设平面上的精确查询点pi,我们计算从pi到表面采样点p'的最短距离作为符号距离的真值。如图所示,将每个假设的平面看作是表面周围的一个采样点,并找到其对应的最近邻表面采样点,采用Kaolin计算的两点距离d(pi, pj')作为真实符号距离。

为了加快这一过程,从所有表面采样点中寻找最近邻替换为基于块的局部搜索,如图所示。最近邻通常位于查询点附近,这样可以去除大量无用的表面采样点,而只保留位于交点的局部块内的采样点。
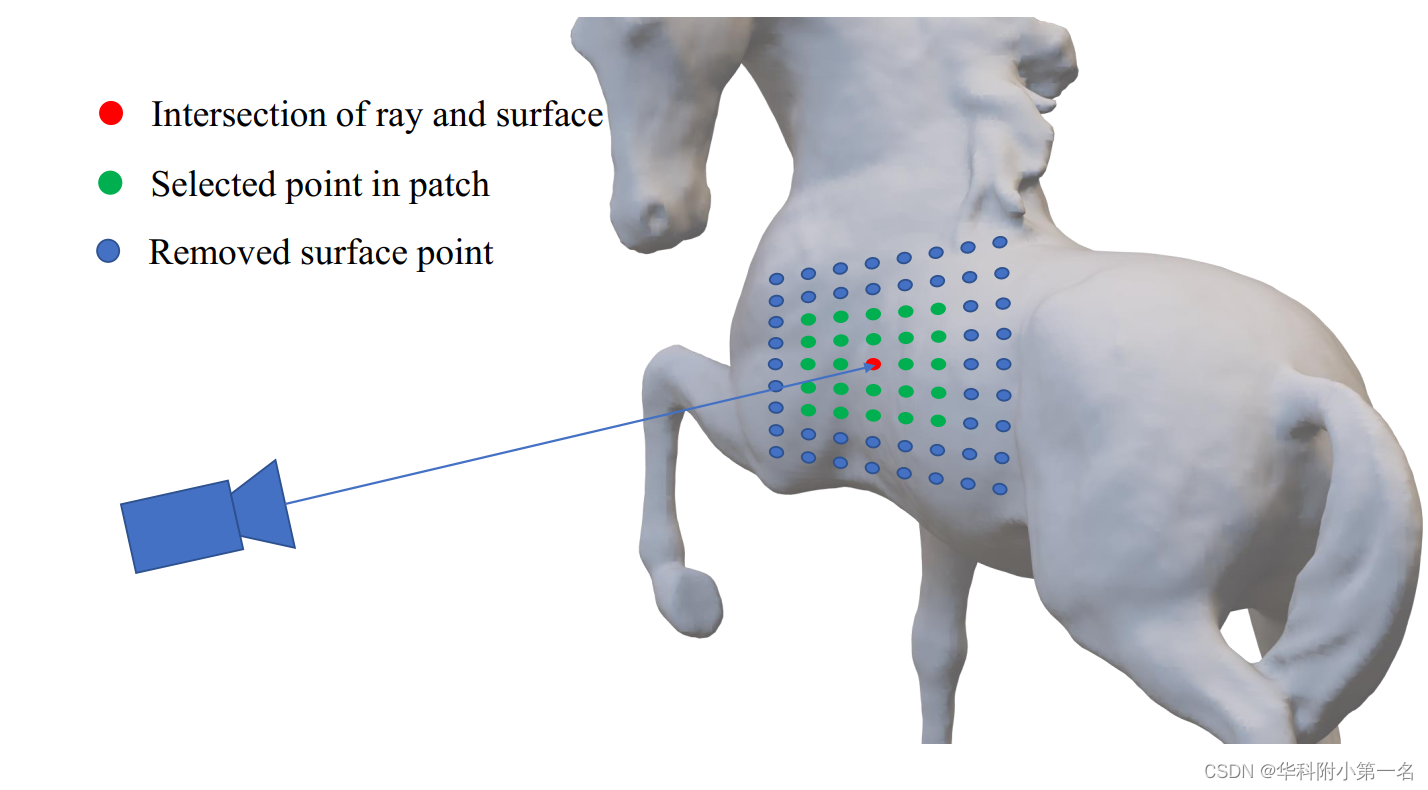
这种基于块的局部搜索方法使需要在合理的范围内尽可能少地计算点,从而降低了搜索的时间复杂度。假设深度图的分辨率为H×W,查询点个数为n,则朴素计算的时间复杂度为O(n×H×W),与深度图的分辨率成正比。而基于块的局部搜索的时间复杂度则简化为O(n×k×k),其中k为块大小,通常设为5。因此,基于patch的局部搜索的时间复杂度可以简化为O(n)。也就是说,它只与查询点的个数n成正比,并且每个查询点的搜索时间是常数。
4. 体融合
一旦得到概率体{P∈D×H'×W'}和距离体{S∈R×H'×W'},将这两个体融合得到最终的深度图D∈H' ×W'。通常,基于softmax的正则化网络通常用于从P预测深度图,P被视为不同深度的假设平面的权重。因此,深度图的计算方法如下:
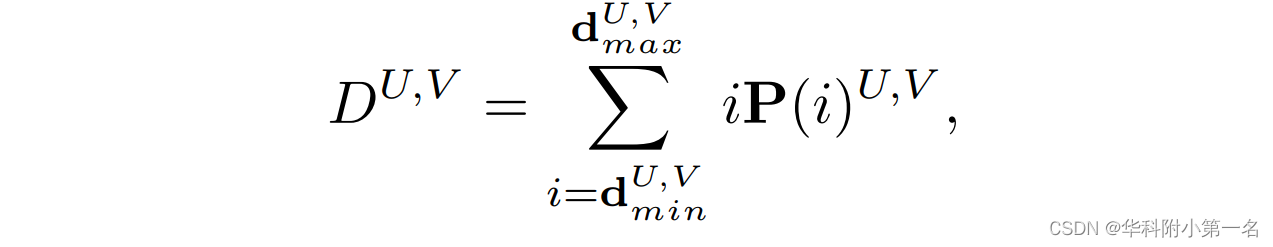
其中,dmin和dmax分别为最近和最远假设平面的距离。但该方法在计算中包含多个无效平面,存在精度问题。一个像素(U,V)的深度值只与该像素对应的几个假设平面相关,不能与表面上的其他采样点关联。 所以如图所示,融合概率体P和引入的距离体S来计算深度图,使得每个像素点都与周围的表面块相关。

具体来说,S可以看作是一个概率值的阈值过滤器。这两体的融合过程在算法中说明。

最后,使用深度图真值和生成的符号距离真值来监督两个体P和S,使用L1损失如下:

其中D*i和Si*分别为第i阶段的真实深度图和点到面的距离。Di和Si为两个分支的预测值。因此,总损失是两个分支的加权和:
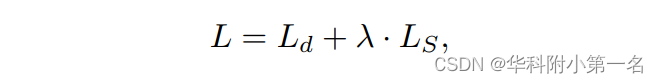
λ是平衡两项的权重,在所有实验中都设置为0.1。
5. SDF分支监督
由于是从相应的深度图中生成点到面的距离真值,因此必须进行误差边界分析。一个合理的假设是使用三角网格来表示表面。有三种不同的情况,如图所示。

在(a)中,以查询点p为中心的最大球面与点o处物体表面相切,则p处符号距离的真值为d(p,o)。从查询点p到采样点集{p'}的边距是d(p, p'j)。由于p'j与切点o重合,因此(a)的误差为e2a,如下所示

其中d(p,o)和(dp,p′j)分别表示符号距离的真值和近似值。
在(b)和(c)中,使用类似的分析方法。 假定O′和O′′是中心在P的表面和球面的切点。 在(b)中,符号距离的真值是D(p,o′),在(C)中,真值是D(p,o′′)。因此,情形(b)和(c)的误差范围可以用下式表示:

其中e2 b和e2 c分别是(b)、(c)的误差平方。将这三种情况结合起来,涵盖所有可能的情况,得到查询点p的最终误差边界如下所示:
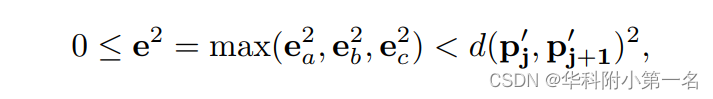
其中e为查询点p的一般误差,p'j和p'j+1为相邻的两个表面点。这个不等式表明,误差e2的平方不超过从两个相邻像素重投影的两点之间距离的平方。
6. 实验
6.1. 实现细节
通过PyTorch实现,批大小为2,DTU数据集用两个NVIDIA RTX 2080Ti,BlendedMVS数据集用在单个NVIDIA Tesla P40。使用更精细的DTU真值如AA-RMVSnet。对DTU数据集和Tanks and Temples数据集进行评估,使用了NVIDIA Tesla P40 GPU, 24G RAM。
6.2. 与先进技术的比较