一、论文简述
1. 第一作者:Rui Peng
2. 发表年份:2022
3. 发表期刊:CVPR
4. 关键词:MVS、3D重建、分类、回归、统一监督
5. 探索动机:在不失完整性的前提下,现有的基于学习的方法可以分为两类:回归和分类。尽管这两种方法表现出了优异的性能,但都存在明显的缺点。回归:通过soft argmin从概率体回归深度。理论上,通过对离散深度假设加权求和,可以实现深度的亚像素估计。然而,模型需要在对加权深度执行的间接约束下学习复杂的权重组合,往往会过度拟合。一组深度假设有许多权重组合,可以加权并求和到相同的深度,这种模糊性也隐含着增加了模型收敛的难度。分类:以概率最大的深度假设作为最终估计,用交叉熵直接约束概率体,但由于其离散预测而无法直接推断出准确的深度。(原文写的真好)
Regression is the most primitive and straightforward implementation of the learning-based MVS method. It’s a group of approaches to regress the depth from the 3D cost volume through Soft-argmin, which softly weighting each depth hypothesis. More specifically, the model expects to regress greater weight for the depth hypothesis with a small cost. Theoretically, it can achieve the sub-pixel estimation of depth by weighted summation of discrete depth hypotheses. Nevertheless, the model needs to learn a complex combination of weights under indirect constraints performed on the weighted depth but not on the weight combination, which is non-trivial and tends to overfit. You can imagine that there are many weight combinations for a set of depth hypotheses that can be weighted and summed to the same depth, and this ambiguity also implicitly increases the difficulty of the model convergence.
Classification is proposed in R-MVSNet to infer the optimal depth hypothesis. Different from the weight estimation in regression, classification methods predict the probability of each depth hypothesis from the 3D cost volume and take the depth hypothesis with the maximum probability as the final estimation. Obviously, these methods cannot infer the exact depth directly from the model like regression methods. However, classification methods directly constrain the cost volume through the cross-entropy loss executed on the regularized probability volume, which is the essence of ensuring the robustness of MVS. Moreover, the estimated probability distribution can directly reflect the confidence, which is difficult to derive from the weight combination intuitively.
6. 工作目标:结合回归和分类的优点,使模型能够在保持鲁棒性的同时准确预测深度。
There is a fact that the depth hypothesis close to the groundtruth has more potential knowledge, while that of other remaining hypotheses is limited or even harmful due to the wrong induction of multimodal. Motivated by this, we present that estimating the weights for all depth hypotheses is redundant, and the model only needs to do regression on the optimal depth hypothesis that the representative depth interval (referring to the upper area until the next larger depth hypothesis) contains the ground truth depth.
7. 核心思想:
- 提出了一种新的表示方法,称为Unity,以统一回归和分类的优点。
- 设计了一种新的损失函数,称为统一焦点损失(unified Focal Loss, UFL)。
- 提出了一个从粗到精的框架,称之为UniMVSNet。

某像素点不同表示的比较。紫色曲线分别表示通过回归、分类和统一得到的每个深度假设的不同权重、概率和统一。回归表示需要每个假设的确切权重来回归深度,而分类表示只关心哪个假设的概率最大,统一只需要知道与最大统一的接近程度。CE表示交叉熵,UFL表示统一焦点损失。
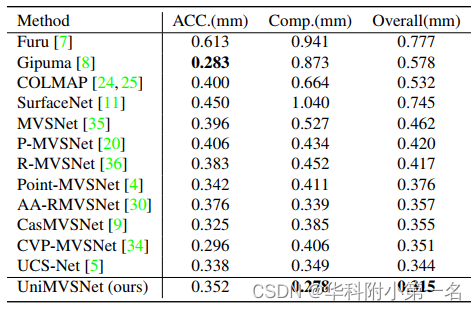
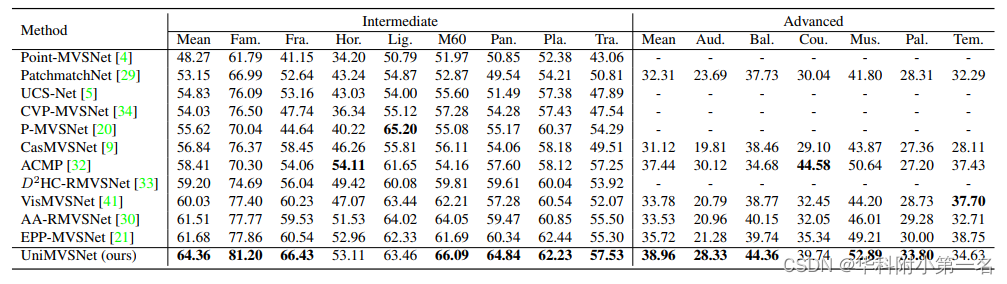
8. 实验结果:SOTA
Extensive experiments show that our model surpasses all previous MVS methods and achieves state-of-the-art performance on both DTU and Tanks and Temples benchmarks.
9.论文&代码下载:
https://github.com/prstrive/UniMVSNet
二、实现过程
1. 基于学习的MVS综述
大多数基于端到端学习的MVS方法都继承MVSNet,首先通过共享权重的2D网络提取特征,构建特征体。为了处理任意数量的输入视图,需要将多个特征体聚合为一个。聚合策略包括两大类:统计的和自适应的。基于方差的映射是典型的统计聚合:

自适应聚合来重新加权不同像素的贡献,可以建模为:

其中W是由辅助网络生成的可学习权重,并表示元素相乘。
在每个深度假设下,参考视图与所有源视图之间的匹配代价被编码到代价体中,需要进一步改进,通过基于softmax的正则化网络生成概率体。具体而言,将概率体视为回归方法中深度假设的权重,深度通过深度假设加权和计算,如下所示:
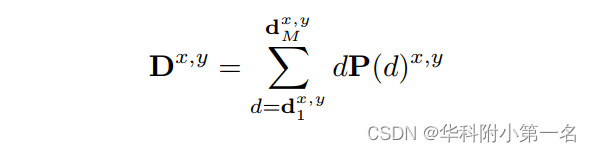
模型通过D与真实深度之间L1损失进行约束。在分类中,P为深度假设的概率,深度估计为概率最大的假设:
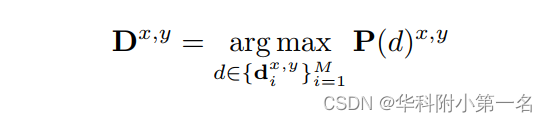
模型通过P和GT one-hot概率体之间的交叉熵损失进行训练。
2. 统一深度表示
如图所示,将深度估计重新定义为一个多标签分类任务,在该任务中,模型需要对哪个假设是最优的进行分类,并回归其接近度。换句话说,网络首先采用分类来缩小最终回归的深度范围,在实现中他们同时执行。因此,统一表示中的模型能够像回归方法一样估计一个准确的深度,也可以像分类方法一样直接优化代价体。下图第(m−1)个假设是红点的最优假设。

统一生成:在最佳深度假设处达到峰值的一个one-hot形式,其深度间隔包含真实深度。最多一个非零值是一个连续数,表示最佳假设与深度GT的接近程度。Unity生成算法如下所示,这比分类方法中的one-hot生成多了一个邻近计算步骤:

输入为深度图GT(Dgt)及深度假设;输出为Unity(类似于one-hot,但非0值表示偏移程度,形状与概率体相同)。
从最小的深度开始迭代,首先计算当前与下一个深度假设的深度间隔r(差值),如果深度GT在当前与下一个深度假设之间,one-hot编码值为:1-(Dgt-当前深度假设)/当前深度间隔,否则为0.
参考:https://blog.csdn.net/qq_43027065/article/details/125338968
统一回归:与传统的方法通过softmax算子预测概率体的方法不同,统一表示通过sigmoid算子估计概率体。首先将估计的概率体P沿M维分解为估计的单位U。为了回归深度,首先在每个像素处选择具有最大统一的最优假设,然后计算与真实深度的偏移,最后融合估计的深度。

输入Unity及深度假设;输出为回归深度。
取U在深度维度最大值Uo对应索引o,根据索引在深度假设找到对应的深度值do。计算当前与下一个深度假设的间隔r(若索引对应最后一个深度,取当前与前一个的间隔),计算偏移offset=(1-Uo)xr,最终的深度值为D=do+offset。
3. 统一焦损
通常情况下,MVS模型的深度假设将进行非常密集的采样,以确保估计深度的准确性,这将导致数百个假设中只有一个正样本(最多一个非零目标),会造成明显的样本不平衡。同时,模型需要更多地关注硬样本(hard samples),以防止过拟合。针对这两个问题,提出了焦损FL(Focal Loss):通过估计的unity值u∈ [0,1]自动区分硬样本,并通过可调参数α和γ重新平衡。为了方便起见,讨论某个像素。FL的典型定义是:

然而,FL(q∈{0,1})是离散目标,传统的FL不适合连续的情况。为了能够优化连续值目标,使用GFL(Generalized Focal Loss):将交叉熵扩展为BCE(-q log(u)-(1-q) log(1-u)),相应地适当调整比例因子。广义FL形式(GFL)通过这两步得到的结果为:

此时,q∈[0,1]为连续目标,目前已有的一些方法采用了这个高级版本。但这种实现在缩放硬样本和简单样本方面并不完美,因为它们忽略了GT值的重要性(需要用来算偏移offset)。
如下图所示,四种典型样本具有不同的真实值q和不同估计u。在绝对误差|q-u|测量(GFL)下,前两个样本将被视为最难的样本。然而,绝对误差不能区分具有不同目标的样本,即图中的前两个样本具有相同的绝对误差,由于其较大的GT,该误差显然对第一个样本的影响较小。

为了解决这种模糊性,通过相对误差优化GFL中的比例因子,并提出了UFL(Unified Focal Loss):
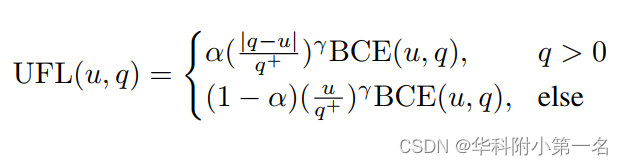
其中q+∈ (0,1]是正样本。当正样本为常数1时,FL是UFL的特例。
此外,注意到比例因子| q - u | / q+ ∈ [0+∞), 这可能导致特殊情况,如上图最后一个示例(值太大)。即使是少量这样的样本,由于其巨大的比例因子,也会淹没损失和梯度计算。通过引入一个专用函数来控制比例因子的范围来解决这个问题。同时,为了保留宝贵的积极学习信号,采用了非对称缩放策略(改变1-α)。完整的UFL可建模为:
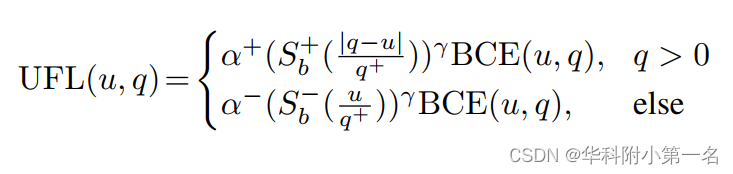
函数Sb(x)=(1/(1+b**(-x)))为以b为基的类sigmoid函数。
4. UniMVSNet
- 应用CasMVSNe结构,基于从粗到细的策略,采用类FPN网络提取多尺度特征,对深度假设进行间隔递减、数量递减的统一采样。
- 为了更好地处理非lambertian区域的不可靠匹配,采用PVA-MVSNet的视角权重方式,增加自适应聚合方法来聚合各视图的特征体。
- 应用了多尺度对3D cnn的代价体进行正则化,每一阶段生成的概率体P作为估计的Unity U,进一步回归精确的深度。
- UniMVSNet通过UFL直接优化代价体,可以有效避免回归方法中间接学习策略的过拟合。
- 粉色部分继承了现有的方法,绿色部分是新模块,深度假设用红色曲线表示。

训练损失。将UFL应用于所有阶段,并以不同的权重进行融合。全损定义为:

其中UFLi为第i阶段所有有效像素UFL的平均值,λi为第i阶段UFL的权重。
5. 实验
5.1. 实现细节
在DTU训练评估;在BlendedMVS上微调,在tanks and temples验证泛化性。与MVANet相同的视图选择和数据预处理策略。三阶段,分辨率为:1/4,1/2,1。在DTU,使用与CasMVSNet相同的网络设置。训练时:N=5,分辨率640×512。为了增加正样本的贡献,设置α+ = 1,将S+5的范围缩放到[1,3),将S5缩放到[0,1)。UFL中的其他可调参数按从粗到细的阶段进行设置,例如,α设置为0.75、0.5和0.25,γ设置为2、1和0。在评估DTU的过程中,将输入图像的大小调整为1152×864,并将输入图像的数量设置为5。在对Tanks and Temples进行测试之前,在BlendedMVS上对模型进行了10个epoch的微调。以7幅图像作为输入,原始尺寸为768×576。对于Tanks and Temples测试,最粗阶段的深度假设数量从48个更改为64个,相应的深度间隔设置为MVSNet间隔的3倍,将输入图像的数量设置为11。
6.1. 与先进技术的比较
SOTA