一、论文简述
1. 第一作者:Yikang Ding
2. 发表年份:2022
3. 发表期刊:CVPR
4. 关键词:MVS、3D重建、Transformer、上下文
5. 探索动机:最近的一些研究证明了长距离全局上下文在特征匹配任务中的重要性,但目前的方法没有充分利用。
MVS定义:The nature of MVS is a one-to-many feature matching task, in which each pixel of the reference image is supposed to search along the epipolar line in all warped source images and find an optimal depth with the lowest matching cost.
现有方法的问题:However, given the aforementioned MVS pipeline, there are two main problems. (a) Local features are well captured by convolutions. The locality of convolved features prevents the perception of global context information, which is essential for robust depth estimation at challenging regions in MVS, e.g. poor texture, repetitive patterns, and non-Lambertian surfaces. (b) Besides, when computing matching costs, the features to be compared are simply extracted respectively from each image itself, which is to say, potential inter-image correspondences are not taken into consideration.
6. 工作目标:利用Transformer,真正意义上感知全局和位置相关的上下文信息。
Transformer, which is initially proposed for natural language processing, has drawn considerable attention from the computer vision community for their great performance on vision tasks. Since Transformer utilizes the mechanism of attention and positional encoding for context aggregation, rather than convolutions, it is capable of perceiving global and positionally relevant context information in the true sense.
7. 核心思想:提出了TransMVSNet。
- We propose a novel end-to-end deep neural network based on a Feature Matching Transformer (FMT), namely TransMVSNet, for robust long-range global context aggregation within and across images.
- To better adapt FMT into an end-to-end MVS pipeline, we introduce an ARF module to adaptively adjust the receptive fields of convolved features and apply ambiguity-aware focal loss for training
8. 实验结果:SOTA,第一个用Transformer的MVS。

TransMVSNet achieves significant improvement in reconstruction accuracy and completeness simultaneously on DTU dataset. Moreover, the overwhelming performance of TransMVSNet can be generalized to more complex scenes, e.g. the intermediate and advanced set of Tanks and Temples benchmark. To the best of our knowledge, it is the first attempt that takes advantage of Transformer in the task of MVS. Consequently, extensive experiments indicate that our method achieves state-of-the-art performance.
9.论文&代码下载:
https: //github.com/MegviiRobot/TransMVSNet
二、实现过程
1. 网络概述
- TransMVSNet首先应用特征金字塔网络(FPN),提取三个分辨率(从粗到细)的多尺度深度图像特征。
- 特征传入transformer前预处理,使用自适应感受场(ARF)模块,以完善局部特征提取,并确保特征顺利转移到Transformer。
- 为了利用参考图像和源图像自身和互相的全局上下文信息,采用特征匹配变换器(FMT)来进行内部和之间的注意力。
- 为了有效地将转换后的特征从低分辨率传播到更高的分辨率(低分辨率:金字塔塔尖),并使FMT接受来自所有尺度的梯度训练,用特征路径连接所有分辨率。
- 对于经FMT处理的N×H’×W’×F的特征图(Cost Volume),建立了一个H’×W’×D’×1的相关体,以便通过3D CNN进行以下正则化处理(形成的是概率空间,然后再进行softmax处理)。
- 在得到正则化的概率体后,采取赢家通吃的策略来确定最终的预测结果。
- 在模糊区域采用了加强惩罚的focal loss,对TransMVSNet进行端到端训练。

2. 特征匹配变压器(FMT)
之前基于学习的MVS网络直接从卷积神经网络提取的特征构建代价体,忽略了上下文信息和图像间的特征交互。前面提到的基于Transformer的匹配方法处理两个视图之间的特征匹配问题。因此提出一个专门用在MVS上的Transformer。
2.1. 预备知识
缩放点积注意力。特征被分组为查询Q,键K和值V。Q根据每个V对应的Q和K的点积得到的注意力权重,从V中检索相关信息。注意力层形式化表示为
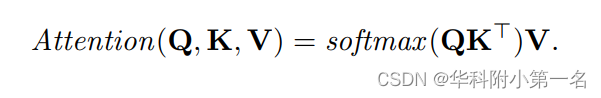
注意机制测量Q和K之间的特征相似性,并根据计算的权重从V中检索信息。具体采用多头注意力,将特征通道分成Nh组(头数)。
线性注意力。多头注意力从Q和K的点积中计算注意力,导致计算成本随着输入序列的长度呈二次增长。为了降低计算成本,使用线性Transformer计算注意力。线性Transformer将原来的核心函数替换为:
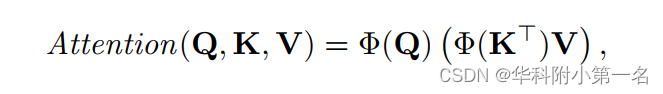
其中Φ(·)= elu(·)+1,elu(·)表示指数线性单元的激活函数。由于通道的数量远远小于输入序列的长度,计算复杂度降低到线性,使得对高分辨率图像的注意力计算成为可能。
2.2. 图像内注意力与图像间注意力
当Q和K向量是来自同一图像的特征时,注意力层检索给定视图中的相关信息,即图像内的远距离全局上下文聚合。在另一种情况下,Q和K向量来自不同的视图,然后注意力层捕获这两个视图之间的交叉关系,图像之间的图像间特征交互就是这样完成的。在FMT中,对参考图像I0和源图像{Ii}N进行图像内注意力,在计算I0和每个Ii之间的图像间注意时,只更新Ii的特征(参考特征应保持不变,因为要测相似性)。
2.3. FMT结构
FMT来获得图像内和跨图像的远距离上下文信息,结构如下图。添加位置编码,隐式地增强了位置一致性,使FMT对不同分辨率的特征图具有鲁棒性。每个视图对应的展平的特征图F∈H'W'×F由Na个注意力块依次处理注意力块的数量Na被设置为4。。在每个注意力块中,参考特征F0和每个源特征Fi首先计算具有共享权重的图像内注意力,其中所有特征都使用各自嵌入的全局上下文信息进行更新。然后进行单向的图像间注意力,根据从F0中检索到的信息更新Fi。
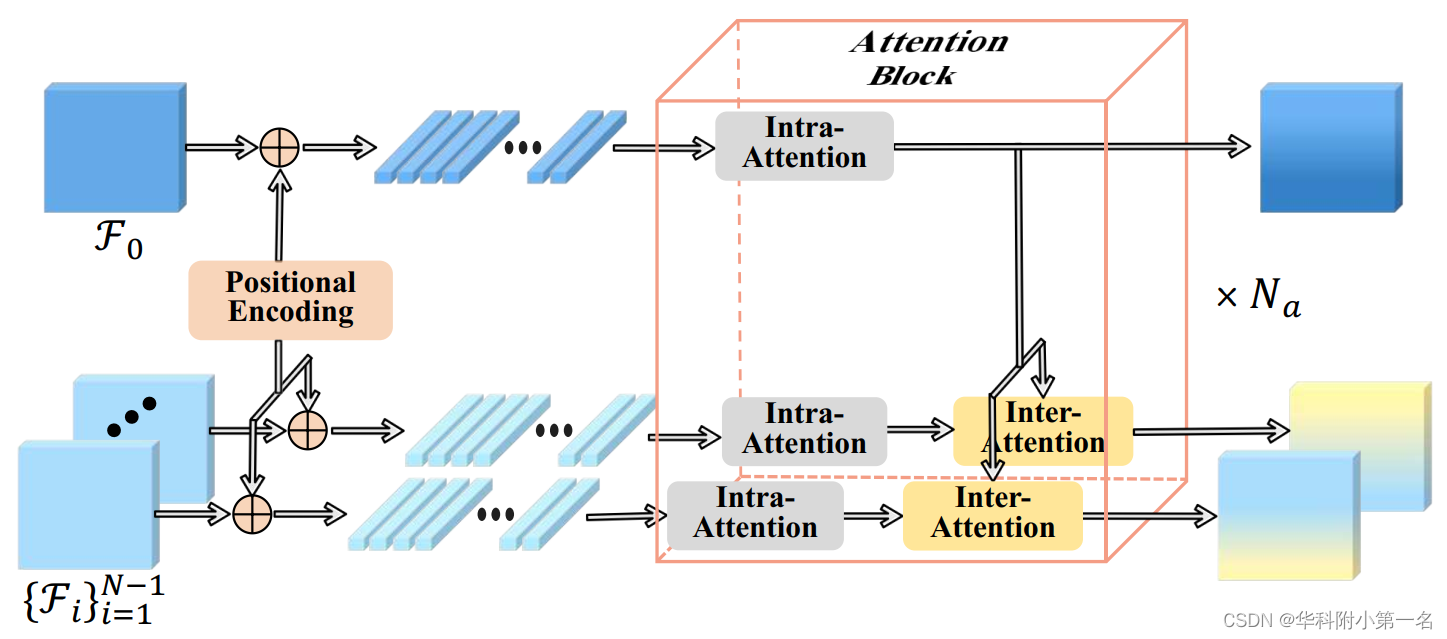
2.4. 转换的特征路径
使用Transformer只在特征图上以相当低的分辨率执行,因为基于学习的MVS和Transformer都需要大量的内存和计算量。如何有效地将转换后的特征从低分辨率传递到高分辨率仍然是一个问题。此外,希望FMT在所有图像尺度的监督下进行训练。因此,设计了一个转换的特征路径来完成这项工作。如图2所示,FMT处理后的特征图被插值到更高分辨率,并在下一个图像尺度添加到相应的原始特征图中。
2.5. 自适应感受野模块
Transformer通过位置编码将全局上下文信息隐式编码为特征图,可以大致理解为具有全局感受野的卷积层。相反,FPN作为网络的基本特征提取器,主要关注相对局部邻域内的上下文。这两个模块在上下文范围上存在明显的差距,不利于特征传递和端到端训练。为此,在FPN和FMT之间插入了一个自适应感受野模块,以自适应地调整提取的特征范围。ARF模块通过可变形卷积实现,学习额外的偏移量作为采样位置,并能根据局部上下文自适应地扩大感受野。
2.6. 相关体构造
通过单应性变化得到代价体,深度空间离散为D个值。位置p处的成特征相关为:

其中F(d)i表示在深度d处经过变化的第i个源特征图。这样,通道数减为1,减轻了正则化时的后续内存消耗。为了聚合所有N−1对相关体,作者认为三维相关体的高维和宽维上的每个像素都有不同的显著性,但在深度维上是一致的。因此,分配了一个像素级的权重图,其在深度维度上的相关性最大。然后将聚合相关体定义为:

2.7. 损失函数
采用聚焦损失,将深度估计作为分类任务,加强模糊区域的one-hot监督。每个深度估计阶段的焦点损失为
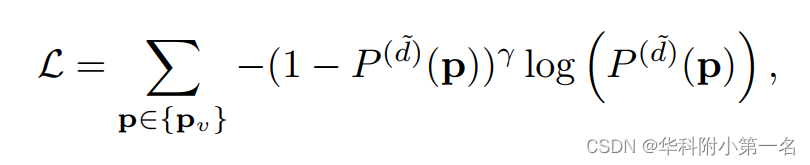
其中P(d)(P)表示深度假设d在像素P处的预测概率,d~表示所有假设中最接近真实值的深度值。{pv}表示具有有效真值的像素子集。特别是当聚焦参数γ=0时,聚焦损失退化为交叉熵损失。根据经验,γ=2适合更复杂的场景,γ=0可以为相对简单的场景产生足够好的结果。
3. 实验
3.1. 数据集和评估指标
DTU是在控制良好的实验室环境下用固定的相机轨迹拍摄的,包含7种不同照明条件下49个视图的128次扫。按照MVSNet的设置,我们将数据集分成79次训练扫描、18次验证扫描和22次评估扫描。BlendedMVS数据集是一个用于多视图立体训练的大规模合成数据集,包含各种物体和场景。该数据集被分成106个训练扫描和7个验证扫描。Tanks and Temples是现实采集的一个数据集,是公开benchmark。它包含一个由8个场景组成的中间子集和一个由6个场景组成的高级子集。 不同的场景有不同的尺度、表面反射和曝光条件。
3.2. 实现细节
用PyTorch实现,并在DTU训练集上进行训练。在训练阶段,设定输入图像的数量为N=5,图像分辨率为512×640。对于从粗到细的正则化,深度假设的采样范围为425mm到935mm;每个阶段的深度假设的数量分别为48、32和8。从最粗阶段到最细阶段,相应的深度间隔分别衰减0.25和0.5。该模型用Adam训练了10个历时,初始学习率为0.001,在6、8、12个历时后分别衰减了0.5倍。在DTU上训练时,设定γ=0。在8个NVIDIA RTX 2080Ti GPU上,批次大小为1,训练阶段总共需要约16小时,占用每个GPU的10GB内存。对于深度过滤和融合,遵循动态检查策略,其中同时应用了置信度阈值和几何一致性。
3.3. 与先进技术的比较
DTU:SOTA
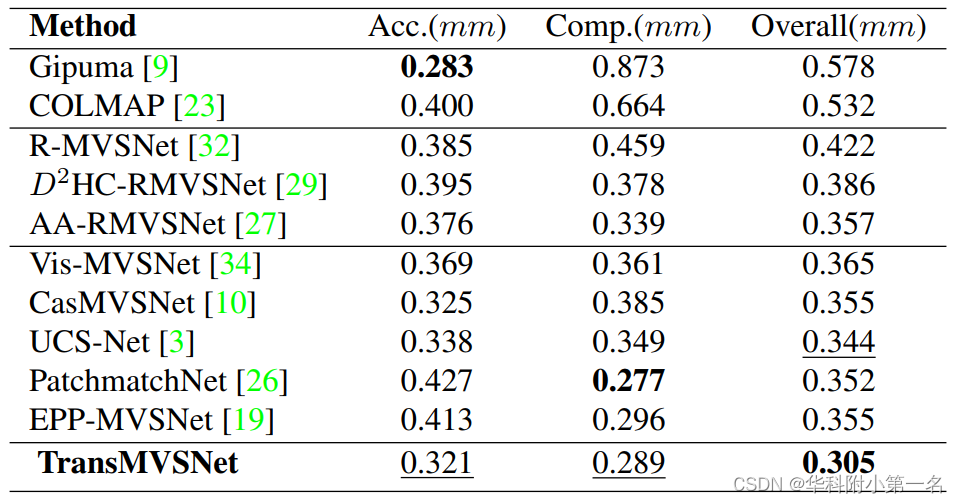
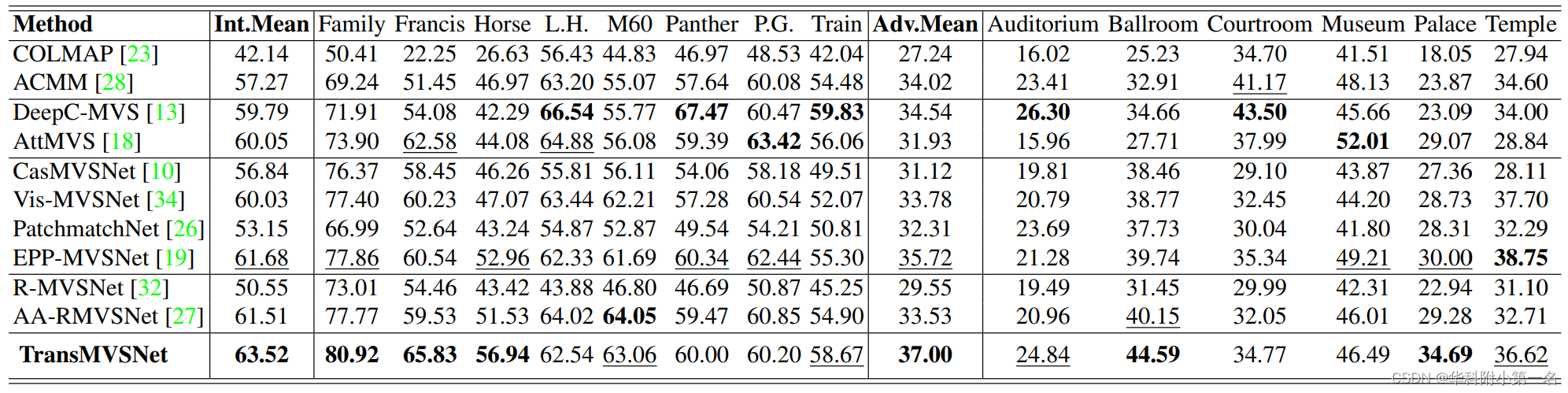
Tanks and Temples:SOTA
BlendedMVS:深度图误差,SOTA

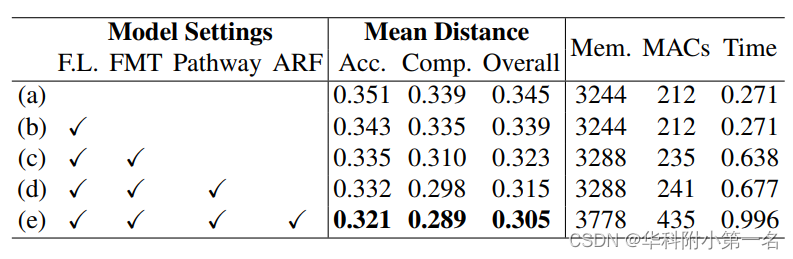
3.4. 消融实验
the inference time is still within one second, which is acceptable compared to RNN-based methods.
4. 限制
1. Transformer降低了推理的速度。
2. 与其他从粗到细的MVS网络相似,该方法对推理超参数敏感,例如:深度假设数、深度区间、深度区间衰减因子。