一、论文简述
1. 第一作者:Matteo Poggi,Andrea Conti
2. 发表年份:2022
3. 发表期刊:IROS
4. 关键词:深度估计、三维重建、深度学习、深度提示
5. 探索动机:尽管2D cnn提取了更鲁棒的特征表示,并且通过3D卷积实现了强正则化,但高要求的计算需求仍然限制了此类解决方案的全面部署,通常需要在精度和复杂性之间进行权衡。例如,以低于输入图像之一的分辨率推断深度或实施从粗到精的策略。此外,上面提到的一些挑战,如处理无纹理区域、薄物体或遮挡,仍然是开放的。
However, despite the more robust features representation extracted by 2D CNNs and the strong regularization achieved through 3D convolutions, the high-demanding computational requirements still limit the full deployment of such solutions, often requiring some trade-off between accuracy and complexity. For instance, inferring depth at resolution lower than the one of the input images or implementing coarse-to-fine strategies. Moreover, several challenges mentioned above, such as dealing with untextured regions, thin objects or occlusions, remain open.
6. 工作目标:到目前为止提到的大多数挑战都是图像域本身固有的。因此,如果可以获得不同方式的额外信息,例如,可以获得由主动传感器感知的一组稀疏的深度测量值,则可以大大减轻它们的影响。
We argue that most of the challenges mentioned so far are inherent to the image domain itself. Thus, their impact could be significantly softened given the availability of additional information with different modalities, for instance, by having access to a sparse set of depth measurements perceived by an active sensor. Nowadays, such sensors are at hand and readily available as standalone off-the-shelf devices. Moreover, they are always more frequently integrated into consumer products like mobile phones and tablets (e.g., Apple iPhones and iPads). However, despite their ever-increasing diffusion, they often provide only sparse depth data (i.e., at a much lower resolution compared to standard cameras).
7. 核心思想:提出了一种多视角立体深度估计框架。假设可以获得一组稀疏的深度测量数据和图像,调整由任何最先进的MVS网络构建的代价体,为架构提供更强的指导,以推断更准确的深度图。
- multi-view stereo depth estimation. Assuming the availabilityof a sparse set of depth measurements acquired together with images, we modulate the cost volume built by any stateof-the-art MVS network to provide stronger guidance to the architecture towards inferring more accurate depth maps.
- We introduce coarse-to-fine guidance by applying cost volume modulation multiple times during the forward pass, compliantly to the coarse-to-fine strategy followed by recent MVS networks.
- We implement the proposed mvgMVS framework within five state-of-the-art deep architectures, each one characterized by different regularization and optimization strategies.
8. 实验结果:
To validate this claim, we run an exhaustive set of experiments by training a variety of state-of-the-art MVS architectures and their guided counterparts on the BlendedMVG and DTU datasets and assessing their accuracy on them. This proves that our framework consistently boosts the accuracy achievable with any considered deep networks in terms of depth map estimation and overall 3D reconstruction when guidance is available.
9.论文及代码下载:
Multi-View Guided Multi-View Stereo
https://github.com/andreaconti/multi-view-guided-multi-view-stereo
二、实现过程
1. Deep Multi-View Stereo background
大多数基于学习的MVS pipeline都遵循相同的模式。给定一组N幅图像,其中1幅作为参考图像,另外N−1幅作为源图像,深度MVS网络对它们进行处理,以预测与参考图像对齐的全局密集深度图。大多数为此目的而设计的深度网络都是定义一个代价体,编码参考图像中像素和源图像中潜在匹配候选像素之间的特征相似性。给定每个图像的内在和外在参数 K,E,后者沿着源视图中的极线检索。具体来说,对于一个特定的深度假设z [zmin,zmax],从给定源视图i中提取的特征Fi通过基于单应性的变形操作π进行投影。
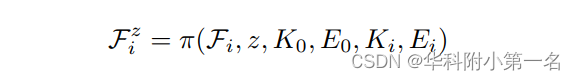
然后,为了对参考特征F0和Fz i之间的相似度进行编码,定义基于方差的体如下

因此,对于给定的像素,方差得分越低,从源视图中检索到的特征越相似,因此,假设z越可能是它的正确深度。但是,实施此解决方案需要大量内存,并且计算复杂。 因此,几个最先进的网络实现了从粗到精的解决方案。 具体来说,一组基于方差的代价体被构建为:
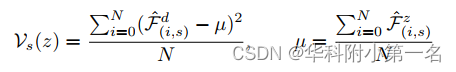
s是计算代价体的特定分辨率或比例,对应地,来自图像i的特征在分辨率s被采样为:
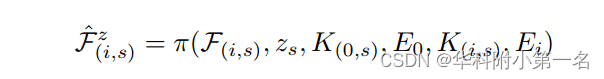
2. Guided Multi-View Stereo
通过假设由标准相机和低分辨率深度传感器(例如 LiDAR)组成的设置,我们利用后者的输出来塑造深度网络从一组彩色图像估计深度的行为。 当这个集合仅限于单帧时,通常会训练一个神经网络来完成由彩色图像引导的稀疏深度点。 当有多个图像可用时,该机制通常会反转,深度测量被用作提示来指导基于图像的估计过程。 例如,通过应用于双目立体的Guided Stereo框架,通过对特征体应用高斯调制以使其与深度提示z对应达到峰值来实现该策略。
类似地,这种机制也可以应用于MVS,实现引导的Guided Multi-View Stereo(gMVS)。 事实上,方差量也可以方便地调制。 在这种情况下,由于低方差编码了相应深度假设z正确的高可能性,翻转高斯曲线以强制基于方差的代价体具有最小近深度提示z* 。

对于具有有效提示的像素,v是等于1的二进制掩码(否则为0),并且k、c 是高斯本身的幅度和宽度。 到目前为止概述的 gMVS 公式将 Guided Stereo 框架扩展到 MVS。
3. Multi-View Guided Multi-View Stereo
MVS 依赖于从不同视点获取的多幅图像的可用性。 此外,假设在设置中注册了彩色图像的稀疏深度测量的可用性。 因此,一组不同的提示可用于每个源图像。 在这种情况下,认为从每个视点聚合多组深度提示可以为网络提供更强的指导并进一步改进基线 gMVS 框架的结果。 为此,执行两个主要步骤。
Depth hints aggregation。给定具有来自任何源图像i属于[1,N]的单应2D坐标qi的像素,其深度值 d*qi可用,参考图像视点中的3D坐标p0为:
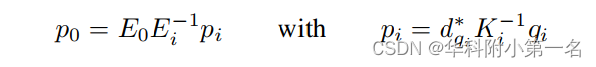
从p0可以得到参考图像视点表示的新的深度提示d*q0,并根据坐标q0处的K0投影到图像平面上。

这允许在参考图像上聚合深度提示,如图所示,来自许多视图(左)的深度提示可以聚合到参考图像视点(右)上,从而获得更密集的深度提示图,以更强的指导来调制网络中的体。 将gMVS框架的这种扩展称为多视图引导多视图立体 (mvgMVS)。
Depth hints filtering。由于视点不同,在其中一个源视图中获取的一些深度测量值可能属于参考视图中的遮挡区域。 然而,考虑到提示的稀疏性,如果限制在不考虑它们的可见性的情况下天真地将它们投影到视图中,这将导致几个错误值的聚合,如图b所示。

如果这样的话,会用错误的深度提示来引导深度网络,从而降低其准确性。为了检测和删除这些异常值,部署了过滤策略,将任何像素 q0定义为离群值,其邻域S(q0)中至少存在一个像素s,使得:
q0改变了相对于s的相对位置,因为被遮挡了。如果q0和s像素坐标和角度(在球坐标中)之间的差具有不同的符号,即(xq0−xs)(θq0−θs)或(yq0−ys)(φq0−φs)为负,则会发生这种情况;
q0与相机的距离比s高得多,即dq0 > ds +ε,其中ε根据使用的特定数据集设置。
虽然简单,但该策略允许以较小的计算成本去除大多数异常值。
4. Coarse-to-Fine Guidance
与通常构建通过堆叠 3D 卷积处理的单个体的深度立体网络不同,MVS 网络通常被设计为体现从粗到精的估计以减少计算负担。 我们认为,网络构建的多个代价体中的任何一个都代表了引导网络的可能切入点。 因此,在正向传播期间调制所有的Vs:

vs和z*分别是下采样到分辨率s的二进制掩码v和深度提示映射z,使用最近邻插值。
5. 实验
5.1. 数据集
由于现有的 MVS 数据集合均未提供稀疏深度点,因此通过从 groundtruth 深度图中随机采样来模拟稀疏提示的可用性。 因此,对于实验,只能选择提供此类信息的数据集,即无法对 Tank & Temples 进行评估。 关于gMVS,我们通过从真实深度图中随机抽取3%的像素来模拟稀疏深度提示的可用性。
5.2. 实现细节
PyTorch,我们设置 k = 10 和 c = 0.01。 关于过滤,我们设置为 3。使用5个最先进的网络进行了实现 gMVS 和变体的实验(MVSNet、D2HC-RMVSNet、CAS-MVSNet、UCSNet、PatchMatchNet)。
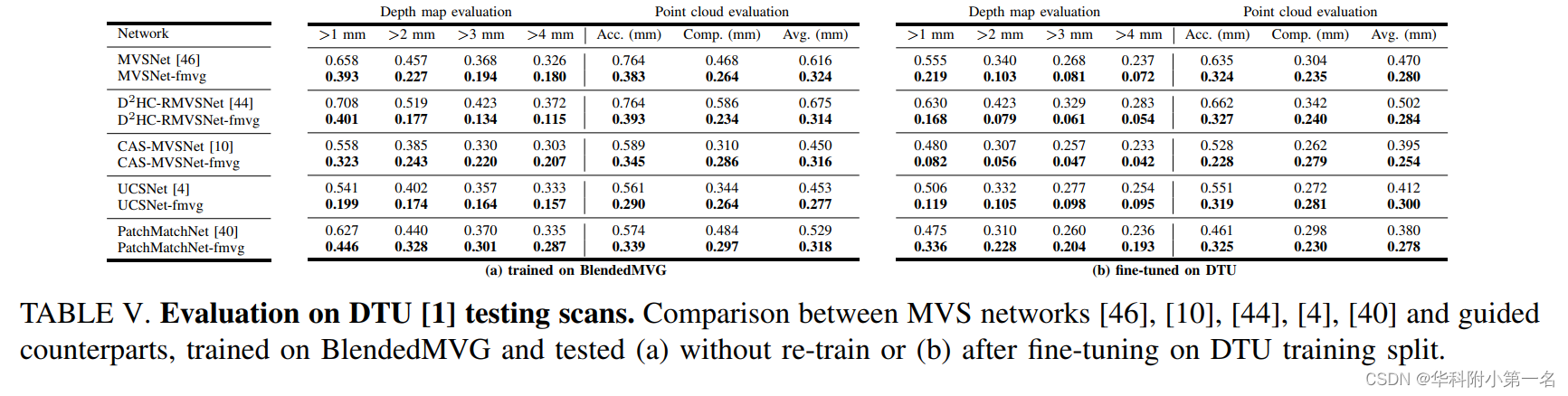
在训练和测试期间,我们将网络处理的图像数量设置为 5。 因此,我们为 mvgMVS 积累了来自 5 个视图的深度提示。先是在BlendedMVG上训练,然后在DTU上finetune,测试则是在BlendedMVG和DTU的测试集上评估。
5.3. 与先进技术的比较

6. 限制
尽管实验突出了多视图引导多视图立体框架的潜力,它对合成数据集和真实数据集均有效,但存在一个在某些环境中可能很重要的限制:使用特定提示密度训练的网络无法泛化到不太密集的提示输入。 具体来说,一旦用固定密度的输入深度点训练了一个引导网络,如果在测试时不能保证这样的密度,性能就会下降。 通过使用 MVSNet 进行的进一步实验研究了这种行为,该实验在训练期间在视图上聚合了 3% 的提示,并以不同的密度进行了测试。可以注意到,通过减少提示的数量,网络性能也会降低,但仍然比没有指导训练的原始 MVSNet 更好。 但是,通过完全忽略提示,性能会大大低于原始 MVSNet。 这种行为突出表明,网络本身在与它们一起训练时几乎盲目地利用提示,当提示在部署期间不可用时会失去很多准确性。 未来的研究将探索更好的训练协议,以在这种情况下使准确性出现最轻微的下降。 此外,当前的评估是通过模拟来自传感器的深度提示的可用性来进行的。 对真实传感设备的进一步实验将允许评估框架对深度稀疏点噪声的鲁棒性。