一、论文简述
1. 第一作者:Jingliang Li
2. 发表年份:2023
3. 发表期刊:TIP
4. 关键词:MVS、三维重建、法线、注意力
5. 探索动机:现有方法仍然存在明显的缺点,如从粗到细策略的累积误差和基于均匀采样策略的深度假设不准确。
6. 工作目标:解决上述问题。
7. 核心思想:In this paper, we propose the NR-MVSNet, a coarse-tofine structure with the depth hypotheses based on the normal consistency (DHNC) module, and the depth refinement with reliable attention (DRRA) module.
- We present a novel depth hypotheses module based on normal consistency which gathers the information from the neighbors and significantly improves the accuracy of depth hypotheses, especially in the texture-less and repetitive areas.
- We propose a depth refinement module that gathers the fusion of attentional reference features and cost volume features to improve the depth estimation accuracy in the coarse stage and solve the accumulative error problem.
8. 实验结果:
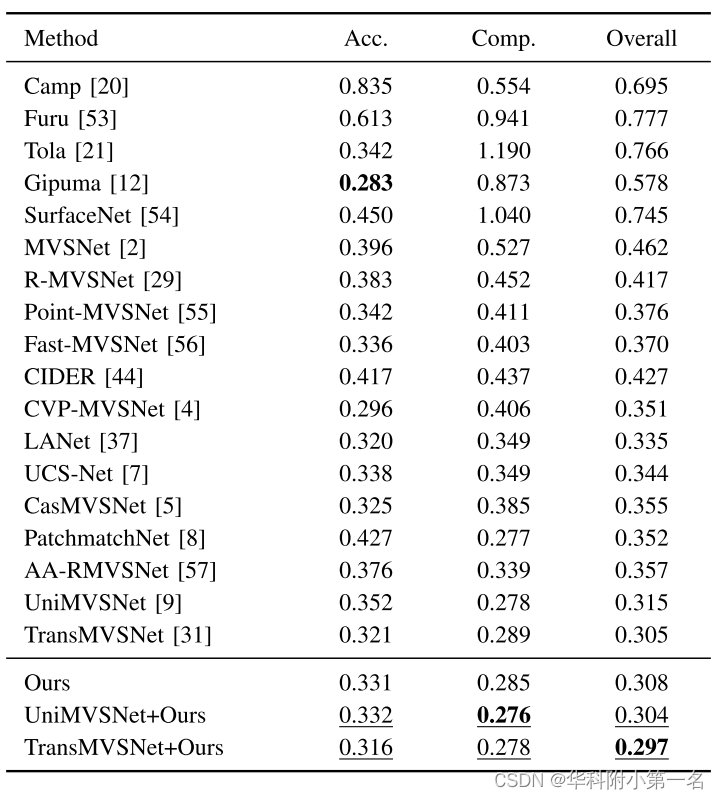
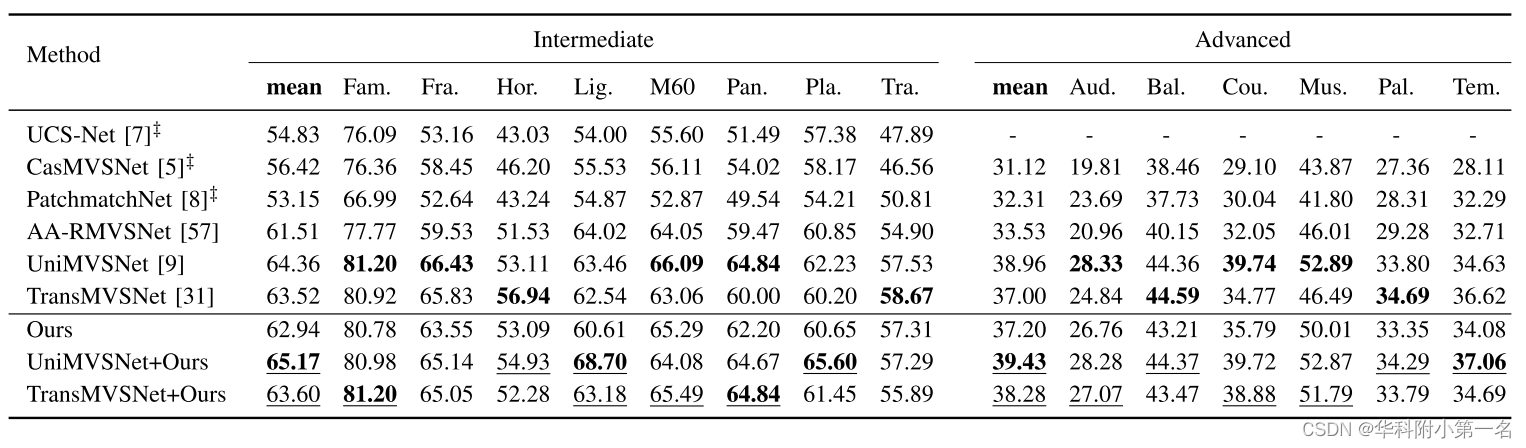
We perform the dense reconstruction experiments on MVS datasets including the DTU, Tanks & Temples, ETH3D, and BlendedMVS benchmark. Our method achieves competitive reconstruction results on these dataset.
9.论文下载:
https://ieeexplore.ieee.org/document/10120723
https://github.com/wdkyh/NR-MVSNet
二、实现过程
1. 网络概述
NR-MVSNet包含五个常见步骤,包括特征提取、深度假设生成、代价体构建、正则化和深度回归,采用从粗到精的策略,如下图所示。更具体地说,给定N个图像的输入,使用I1和{Ii}i分别表示参考图像和源图像。首先,利用小型FPN提取输入图像在三种分辨率下的多尺度特征{Fi,k}。输入图像尺寸为H×W×C,对应特征{Fi,k}的分辨率分别是H/4×W/4, H/2×W/2和H×W。
使用初始阶段获得初始深度图作为第一阶段正常计算的输入。同时,在初始阶段,学习到的参数与第一阶段共享,在整个深度范围内只使用均匀采样产生的深度范围假设。之后,利用DRRA模块通过收集注意力参考特征和代价体特征的融合来提高初始深度图的精度。
构造DHNC模块生成更有效的深度假设。将DHNC模块第k阶段的深度范围假设数设为Mr,深度发现假设数设为Mn。对于阶段{k= 1,2,3},使用之前预测的深度图Dk−1来计算法线并生成深度假设{Dk}。之后,通过将源特征变化到参考视图来创建3D代价体,然后使用3D CNN对其进行正则化。最后,利用可微soft argmin过程对深度图Dk进行回归,并在深度估计后重建点云。

2. 基于法线一致性的深度假设
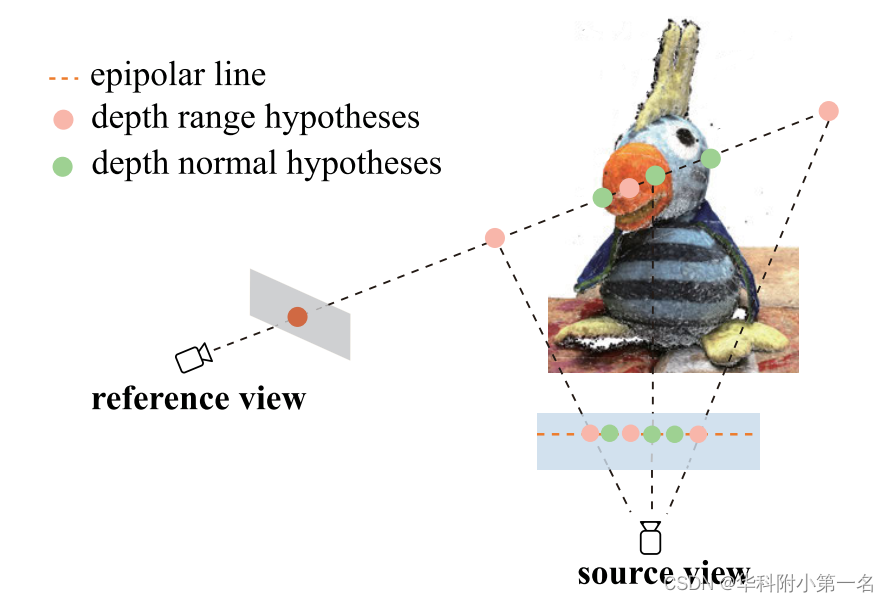
基于学习的方法通常使用均匀采样生成深度假设。然而,最终预测的深度图可能不太平滑,因为以这种方式没有考虑相邻像素的相关性。为了克服这些限制,必须通过深度假设生成模块提供更有效的深度假设。之前的一些工作通过假设位于同一表面上的像素的深度是一致的来传播深度信息。然而,来自同一物理平面的像素并不都具有相同的深度值。相反,这些像素的法线在3D空间是一致的。因此,提出了DHNC模块,以利用自适应邻域的法线进行更准确的深度假设。DHNC的详细情况见下图。

DHNC模块的管道由两个分支组成,如图(a)所示。

在第一个分支中,在整个深度范围内生成深度范围假设。给定像素p在前一阶段的深度预测Dk−1,基于不确定性估计置信度动态调整深度范围Rk。在像素p和阶段k处的范围Rk计算为:

其中λ为标量区间参数,Uk−1为上一阶段预测深度Dk−1的不确定性值,根据UCSNet从概率体中学习。然后,在深度范围Rkr内均匀采样,计算深度范围假设D~rk ={D~kr, j}Mkr。
在第二个分支中,根据相邻像素的法线找到深度法线假设。在参考图像中对于像素p收集Mnk个深度法向假设,首先使用深度值和相机参数计算其相邻像素的法线。然而,静态的采样邻域集会导致深度假设无效,因为预先预测的深度在某些区域可能是不准确的,特别是对于无纹理的区域,并且一些邻域可能会越过边界。因此,与PatchmatchNet类似,基于可变形卷积自适应传播相邻采样位置,能够有效地收集更合适的假设,其中也包括无纹理区域。
对于每个像素p,首先定义一个静态邻域{pj}Mkn,然后通过学习偏移量△pj自适应更新领域的位置,其中pj=pj+△pj。其次,给定参考图像的深度图,根据参考相机的内参矩阵从参考像素的二维位置计算出参考像素的三维坐标。在此基础上,给出了图像中像素在三维空间法线的推断。像素pj的法向n可以用封闭形式估计为:

式中,A为像素pj的领域坐标,1为元素都为1的向量。注意,给定深度图的表面法线计算是一种固定权重的方法,不需要可学习的参数。

此外,根据像素p的自适应邻居pj的表面法线计算像素p的深度法线假设,如上图所示。黄点表示待估计的像素位置。(a)参考图像,(b)自适应采样位置(绿色),(c)点(黄色)投影到邻近点的切平面上
(绿色),得到投影点(橙色),计算深度正态假设。分别用相邻像素p j的三维坐标及其法线构成切平面,将像素p的三维点投影到这些切平面上,得到新的三维点p'j如下:
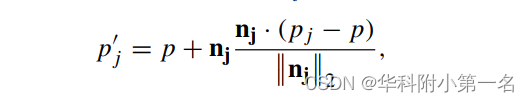
最后,利用投影点{p'j}和参考相机内参来计算深度法向假设D~nk={D~kn,j}Mkn。总深度假设D~可计算如下:

深度假设的总数为Mk=Mkr+Mkn。
3. 从粗到细的深度传播
与MVSNet类似,NR-MVSNet的每个阶段也有三个步骤来评估深度图,包括代价体构建、代价体正则化和深度回归。
首先,通过计算参考特征和源特征之间的相关性来度量它们的相似度,通过组相关构建代价体,并使用像素级视图权重对视图进行聚合,以估计可见性信息。
此外,噪声可能会污代染价体,应结合平滑性约束。因此,还使用了最近常用的3D U-Net来处理每个阶段的代价体,并推断概率体P,它聚集了关于相似性的极线信息。最后,为了解决反向传播训练的问题,使用基于学习的方法中的通用方法进行加权求和P:

4. 具有可靠注意力的深度改进
在粗阶段,粗层特征不能很好地捕捉相邻视图中的微小平移和变形,其代价体不可靠,预测深度图不准确,导致后续阶段的累积误差。此外,预测深度图的精度对法线计算至关重要,在粗阶段还有待提高。因此,提出初始阶段后的DRRA模块,如图(b)所示,可以收集注意力参考特征和代价体特征的融合。DRRA的详细情况见下图。


在MVSNet中,全局图像结构对于检索更硬的采样(如无纹理和重复纹理表面中的像素)非常重要。因此,首先计算注意力参考特征,在空间域中聚合一个大的感受野。另一方面,概率体代表了不同假设中相似性的概率,也代表了代价体在不同深度假设中的重要性。在此基础上,通过计算注意力代价体特征来聚合源特征和参考特征的相似度信息。
为了得到注意力参考特征Fattn,使用一个较小的transformers模块Mini-ViT来提取全局注意力特征,如下图所示。与CNN相比,transformers可以更有效地提取全局关系特征。然而,transformers注意力在内存和计算复杂性方面都是昂贵的,特别是在高分辨率下。因此,利用较小的transformers模块来获得参考特征的全局分布信息。
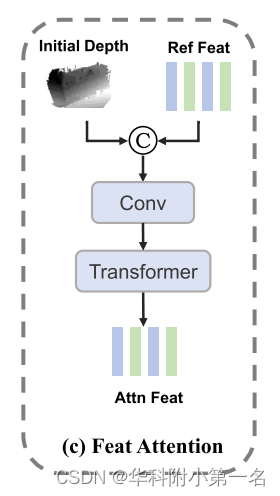
设F为参考特征,D~为初始深度图。首先将F和D连接起来,然后使用卷积层来减少融合特征Fcoon的通道并将其编码为transformer的输入,由

在[·,·]表示连接操作。F(·)是卷积运算。如下图所示,transformer以固定大小的向量序列作为输入,首先使用核大小为k×k,步幅为k,输出通道数为E的卷积块,将融合的特征编码到transformer块中的序列中。这个卷积的结果是一个大小为H/k×W/k×E的张量,然后将其重塑为一个空间平坦张量Fe∈S×E,其中S=(H×W)/k2作为Transformer的有效输入序列长度。还将学习到的位置编码添加到块嵌入中,然后将它们输入到transformer中。然后,transformer块输出一系列嵌入特征Fe∈S×E,有效地包含了更多的全局信息。同时,融合特征代表高分辨率和局部像素级信息。因此,最终通过在通道维度上对融合特征和transformer的输出进行点积计算了Fattn的注意力参考特征。

另一方面,引入代价体注意力方法,该方法可以更深入地挖掘参考视图和源视图之间的相似性,如下图所示。

P∈M×H×W为概率,V∈C×M×H×W为代价体,其中M为深度假设个数,C表示相似特征的通道数。首先使用V和P之间的元素求和得到注意力代价体特征V′∈C×H×W,可以通过:

其中⊙表示逐元素乘法。此外,一些可见像素被遮挡或处在背景、无纹理和重复纹理区域,它们在代价体上的相似特征对深度改进无用。因此,为了测量相似性的置信度,计算熵图E∈H×W:
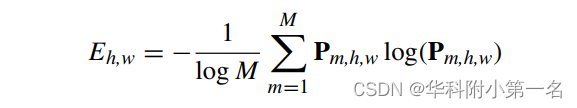
之后,使用log M将熵归一化为(0,1),置信图U=1-E。请注意,具有较低置信度分数的相似特征可能是错误的,然后合并置信度阈值来忽略注意力代价体:
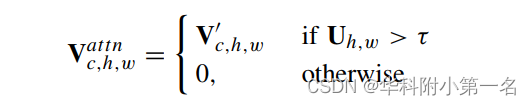
其中τ表示置信阈值。在获得注意力参考特征和代价体特征后,通过融合两个输出构造高维特征,然后使用卷积层学习残差深度值。残差D′由下式计算:

5. 损失函数
采用监督学习策略,并构造真实深度的金字塔作为监督信号。与现有的MVSNet框架类似,使用L1范数测量所有阶段,并使用不同的权重进行融合。总损失可定义为:
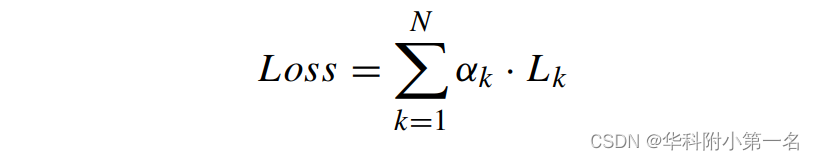
式中,Lk为第k阶段的损失,αk为其相应的损失权重。
6. 实验
6.1. 实现细节
所有实验都在一台配备Intel(R) Xeon(R) Gold 6130 CPU处理器、256GB内存、8张NVIDIA TITAN RTX 24GB显卡的服务器计算机上进行。
6.2. 与先进技术的比较

7. 未来
由于深度和点云的获取困难,我们将在未来的工作中更加关注MVS任务的自监督学习。