一、论文简述
1. 第一作者:Zhe Zhang
2. 发表年份:2023
3. 发表期刊:ICASSP
4. 关键词:MVS,三维重建,深度估计,深度学习,RGB引导深度改进
5. 探索动机:目前的方法使用固定大小核的卷积,在低纹理区域缺乏各向异性,并且在前景和背景的边缘产生虚假的深度混合。此外,在粗变细方案下,粗阶段的严重不匹配会导致误差在细阶段的积累和传播。
However, current works are limited to using fixed-size convolution kernels, leading to suboptimal features that lack anisotropy in low-textured regions and tend to produce invalid depth blending at the edge of the foreground and background.
AA-RMVSNet imports deformable convolution to extract image features, and PatchmatchNet augments the traditional propagation and cost evaluation steps of Patchmatch with learnable modules. However, these methods do not fully exploit the pixel-wise depth correlation between neighbors.
Besides, following the coarse-to-fine scheme, severe mismatchings in coarse stages will result in error accumulation and propagation in finer stages.
6. 工作目标:解决上述问题。
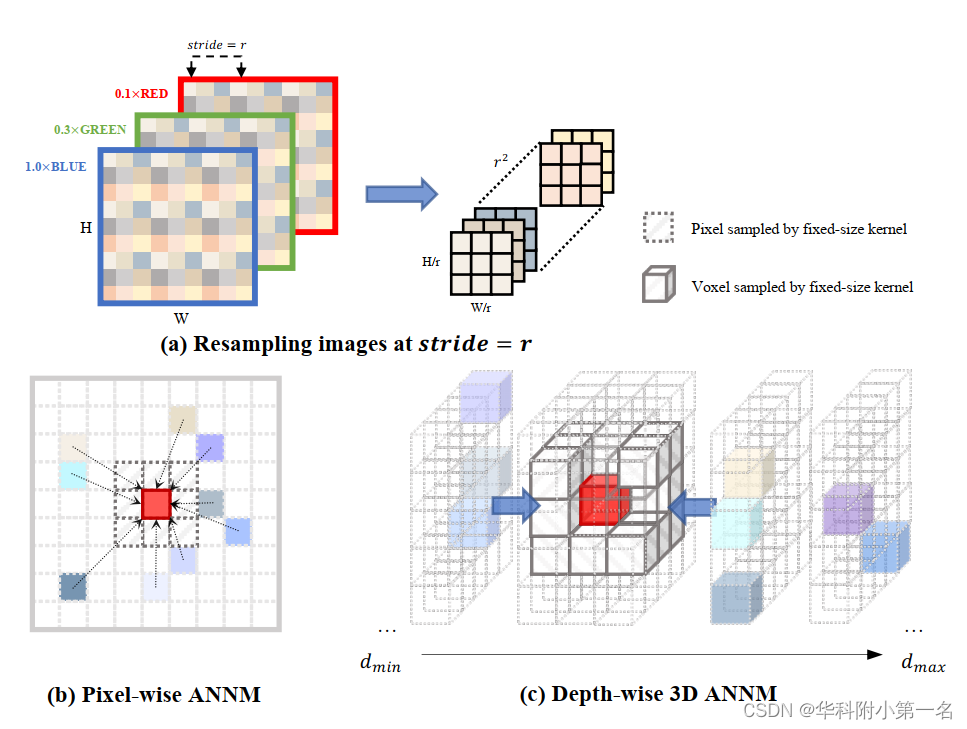
7. 核心思想:关键思想是基于这样的观察:像素的深度与它周围的邻居密切相关。例如,边缘内的领域对前景像素有积极的影响,而背景领域则有相反的影响(图1(a))。
- We propose the Adaptive Non-local Neighbors Matching (ANNM) strategy, which leverages the pixel-wise spatial correlation of neighbors and extends it as the voxel-wise 3D ANNM for preferable depth perception.
- We apply RGB guided depth refinement to repolish mispredictions in coarser stages by highlighting the value of contours and preventing the accumulation and propagation of errors for finer stages.
8. 实验结果:
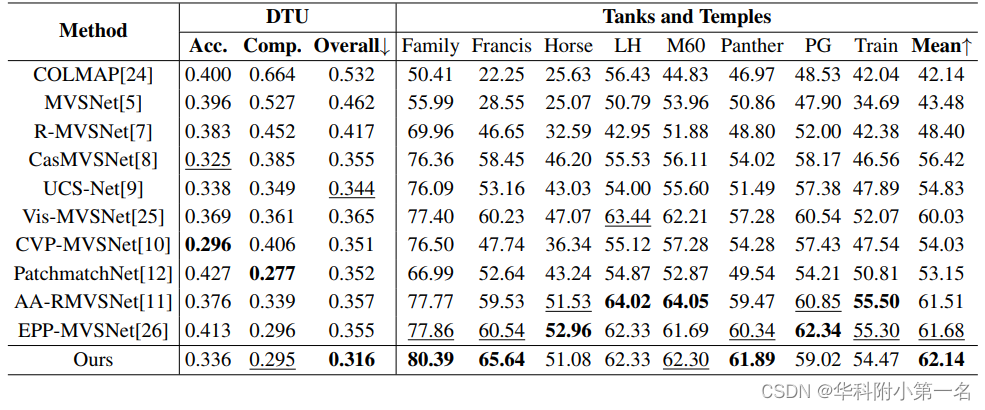
The proposed network is extensively evaluated on the DTU dataset and the Tanks and Temples dataset. The proposed method achieves state-of-the-art performance from extensive experimental results.
9.论文下载:
https://ieeexplore.ieee.org/document/10095299/authors#authors
二、实现过程
1. 网络结构
采用从粗到细的方案,并给出了两个阶段进行论证,自适应非局部邻居匹配(ANNM)策略及其三维扩展,RGB引导下的深度改进,能量聚合损失。

2. 自适应非局部领域匹配
在图像I上的一个像素p(x, y),本文提出的自适应非局部邻居匹配(ANNM)策略的目的是通过在一个较大的区域内自适应地寻找一组采样像素及其空间相关性来构建p的非局部领域感知特征。首先,如图(a)所示,对I进行通道统一和重采样操作。受[17]的启发,蓝色通道对特征识别具有更强的鲁棒性,将RGB通道(IR,G,B)合并为统一表示:
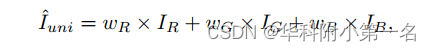
其中wR = 0.1, wG = 0.3, wB = 1.0。然后对I´进行步长 = r的下采样,重复叠加得到形状为r2 × H/r × W/r的重采样图像I´。重新采样后,感受野变得更加有效,并且权重在不同通道之间共享。
在图像变换后,提出了两个ANNM子模块K和G,用于产生对于p(x, y)的非局部空间相似权值wp (k2 × 1 × 1)和采样偏移量Op (2k2 × 1 × 1),其中k是加权核的大小。具体表达式如下:
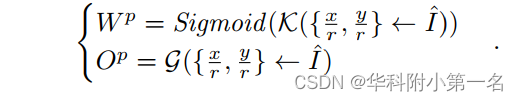
如图(b)所示,通过对学习到的权值和偏移量进行加权平均计算,得到领域感知特征中的每个像素。以经典FPN (local fixed-size kernel)提取的特征为基础,最终的非局部邻居感知特征F可计算为:
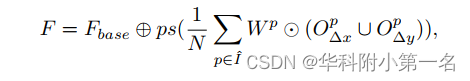
其中O∆x表示水平偏移量,O∆y表示垂直偏移量,⊕和⊙分别表示逐元素的加法和乘法,N = k2是中心像素周围采样像素的数量。我们使用pixel-shuffle(ps)将非局部相似度从特征域转换到空间域,形成I0的形状。
二维特征被编码到3D相机截锥体。然后,一个直观的想法是,进一步将2D ANNM扩展到3D空间,以更好地探索显式的非局部深度感知代价匹配。3D ANNM单独应用于参考特征体,原因很简单,最终目标是估计深度图。如图(c)所示,表示从参考特征F0直接warp的特征体Vbase,两个三维子模块学习非局部深度相似权值Wq为k3 × 1 × 1和三维采样偏移量Oq为3k3 × 1 × 1。最终的深度感知特征体V整合了来自周围体素的深度感知,计算如下:

其中q是Vbase中的体素,采样体素的个数N' = k3, O∆d表示深度偏移量。学习到的深度感知特征体表示更鲁棒的领域匹配,然后将所有视点的{Vi}组成单个代价体来估计深度图。
3. RGB引导深度改进
从较粗的阶段生成的深度图用于指导较细的层。然而,在较粗阶段的严重错误预测将在较细阶段积累起来。为此,在最粗层参考了最近的SOTA RGB引导深度改进网络DCTNet,以更好地突出有深度改进价值的轮廓。特别地,将粗深度上采样到符合高分辨率RGB轮廓信息辅助的I0形状。ΦD和ΦI0是特征提取模块生成的D和I0的特征,而从I0学习到的边缘注意力权值WI0用于防止RGB/深度图像之间的纹理过度传递。改进后的深度D可得:
![]()
DCT(·,·,·)的计算公式如下:
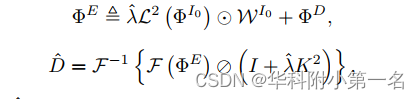
其中λ为可学习参数,L为拉普拉斯滤波器,F为DCT运算,F−1为逆运算,I为单位矩阵,⊘为逐元除法,K为I0的2D基本图像。对粗阶段预测的离群值进行精化校正,对细阶段提供严格的深度假设指导。
4. 损失函数
用一种分类的方式来表述MVS问题,在有效像素集Ω下监督真值分布PGT。预测深度表示P和PGT之间的交叉熵损失LossCE,首先用于约束。此外,利用具有去相关和能量集中特性的DCT变换[22],提出了创新的能量聚合约束LossEA为:
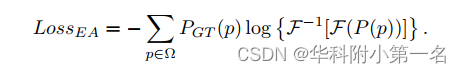
模型的总损失表示为:
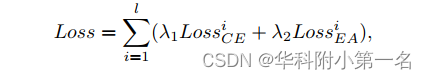
其中λ1 = λ2 = 0.5。
5. 实验
使用PyTorch实现,在NVIDIA Tesla V100 GPU上训练了16个epoch,初始学习率为0.001。消耗0.6s和4.7G GPU内存来实现全分辨率。
5.1. 与先进技术的比较