一、论文简述
1. 第一作者:Xinyi Ye
3. 发表期刊:ICCV
4. 关键词:深度感知、MVS、深度几何
5. 探索动机:作者观察到一个有趣的现象:估计误差较小的深度图在融合渲染后可能无法获得更好的三维重建质量。还有其他因素限制了3d重建的准确性吗?经过对融合过程的深入研究,发现深度几何是MVS中被忽视的一个重要因素。即使在相同的深度估计误差情况下,不同的深度几何形状也存在显著的性能差距。因此,值得考虑的是什么构成了一个好的深度几何。
6. 工作目标:为了解决这个问题,如下图所示,引入了两种代表两种极端情况的理想深度几何形状:由单面单元组成的几何形状与由鞍形单元组成的几何形状。前者与真值面在同一侧有深度面,后者在真值面两侧来回振荡。为了评估这些深度几何对3D重建的影响,在确保相同的绝对误差情况下,人为控制预测深度平面的单元。有趣的是,发现与单侧单元相比,鞍形单元显著提高了3D重建性能。将这种性能改进归因于融合渲染阶段的深度插值操作,该操作对深度单元高度敏感。鞍形单元可以最小化预期的插值深度误差,从而提高三维重建性能。提出了一种获取鞍形深度单元的新方法。

7. 核心思想:为了解决上述问题,提出了一种新的方法,融合了单目和多视角线索的各自优势,从而显著改善了动态场景中的每个单独源。
We introduced a new perspective for considering depth geometry in MVS. We proposed the depth geometry with saddle-shaped cells for the first time and demonstrated its importance for the MVS reconstruction task.
We proposed the dual-depth method to achieve saddle-shaped cells and designed the corresponding network framework DMVSNet.
our approach offers a new direction for future research, where the depth geometry can be exploited to enhance the reconstruction performance.
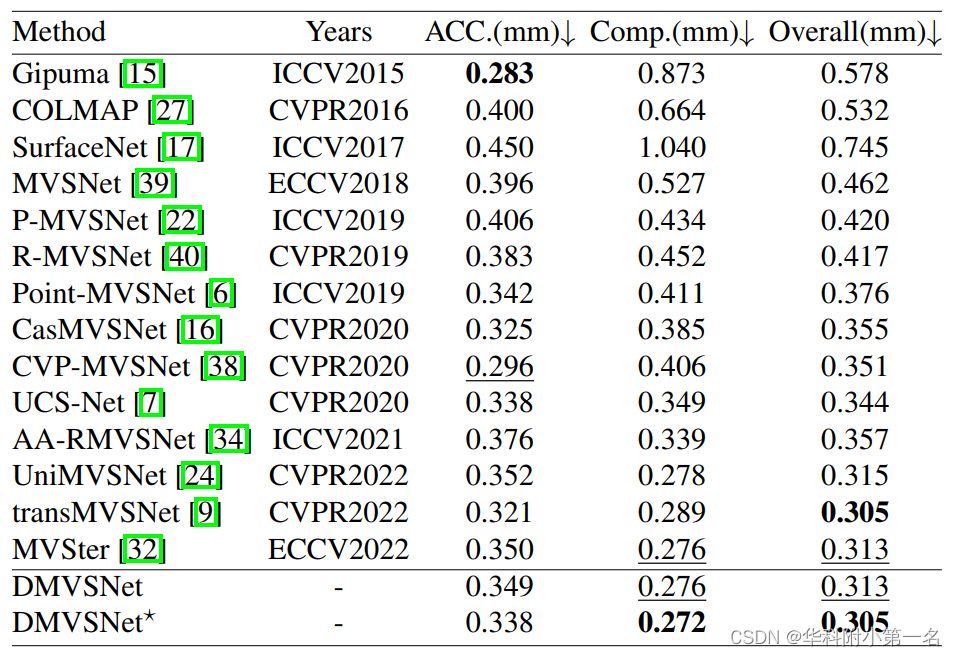
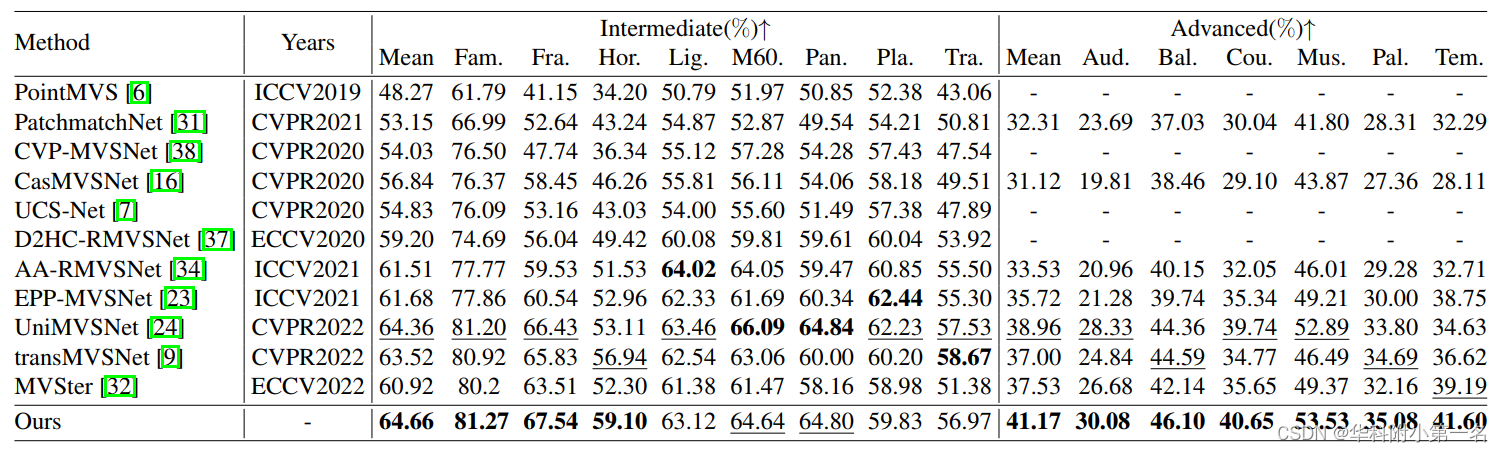
8. 实验结果:
Due to the Dual-Depth method, DMVSNet outperforms most methods in the indoor data set DTU and the outdoor data set (Intermediate Tanks and Temple). On the more challenging dataset (Advanced Tanks and Temple), DMVSNet achieved state-of-the-art performance, improving by 5.6%.
9.论文下载:
https://arxiv.org/pdf/2307.09160.pdf
二、实现过程
1. 估计偏差和插值偏差
下图所示的融合过程,参考视图中的像素使用估计的深度图投影到空间中的3D点。然后使用各自的相机参数将该3D点重新投影到其他视图中的子像素上,并使用相应的深度图来获得新的3D点。最终的3D重建结果由参考视图中像素的深度差和其他视图中子像素的估计深度确定(例如,通过平均)。因此,三维重建结果的精度不仅受到深度图估计精度的影响,还受到子像素插值深度精度的影响。通过线性插值相邻像素的深度来估计亚像素深度,其精度受估计偏差和深度单元的影响。

从下图可以看出,由于深度单元不同,在相同的估计偏差和插值位置下,插值深度的精度会发生变化。因此,考虑不同单元的深度几何对MVS的影响是很重要的。

2. 单面vs鞍形
为了简单地说明深度单元的差异,在下图中给出了两个假设的深度单元:a)单侧单元;b)鞍形单元。假设插值位置是具有相同的绝对估计偏差为'1'的均匀分布。深度平面(黄色)和真值平面(蓝色)之间的空间体积可以被认为是期望的绝对插值误差。在数学上,“单面单元”的期望绝对插值误差比“鞍形单元”高4倍。

为了定量证明不同单元的深度几何对三维点重建性能的影响,进行了一个小验证实验。在假设每个像素的绝对估计偏差相同的情况下,使用真实深度翻转估计深度值,使其按照两个单元分布。实验结果显示了具有不同单元的深度几何对三维点重建质量的影响很大,包括精度和完整性,甚至精度差异超过60%(下表第二行和第三行)。这表明鞍形单元的深度几何是提高MVS性能的可行方法。

现有的大多数MVS方法没有对深度单元进行约束,因此其深度图分布在单面单元和鞍形单元组成的几何形状之间,这就决定了三维点重建的精度介于两种由奇异单元组成的理想几何形状之间(如上表第一行所示)。此外,如果没有对深度单元的约束,尽管深度预测性能更好,但可能会得到较差的3D指标(下表),一个反直觉的现象。尽管深度预测性能较好,但获得的3D指标较差。如何约束网络生成更多鞍形单元的深度图?在上面的玩具实验中,利用真值翻转估计深度的方法是一个先有鸡还是先有蛋的问题,在实际推理中是不可行的。

3. 双深度预测
在常用的MVS方法中,使用L1损失来监督估计的深度图D:

其中Dg为真实深度图。目的是最小化估计深度图与真实深度图之间的差异,从而减少估计偏差。然而,它缺乏执行估计深度的几何形状的能力,更不用说预测鞍形深度图了。此外,鞍形单元深度图的目标与Lest的目标不一致,这促使估计的深度图更接近真实的平滑深度图。
针对具有更多鞍形单元的振荡深度几何,选择为每个像素预测两个深度值。如果对偶深度分布在真实深度的两侧,则采用启发式选择策略可以获得目标几何形状。具体来说,为每个像素生成两个概率分布,并使用它们生成两个相应的深度图D∈2×H×W。为了保证独立预测的双深度的准确性,像以前的工作一样,使用L1损失来监督它们的预测值。直观地说,如果不对双深度的联合分布添加约束,得到的预测分布是无序的。因此,提出了另一种新的损失来约束两个深度在真值周围对称分布。

其中|·|表示绝对距离,max(·)和min(·)取第一个维度上的最大值和最小值,例如max(D) = max(D[1,:,:], D[2,:,:])。Lint激励估计偏置不大于|max(D)−min(D)|,使得区间随着估计偏置的增大而增大,从而保证了双深度分布在真实深度的两侧。如果max(D) = min(D) = Dg,则Lint达到最小值,表明深度估计无偏,与Lest的目标一致。
当真实深度值介于预测的双深度之间时,提出了棋盘选择策略,为每个像素选择合适的深度预测值。具体来说,交替选择最大和最小预测深度值,创建一个类似于棋盘的分布。如下图所示,棋盘选择策略和深度假设采样。(a)交替选择每个像素的两个预测的最小或最大深度。

像素(x, y)的深度由:

产生振荡深度图Dc。如下图所示,双深度法得到的深度图实现了由鞍形单元组成的几何形状。将估计深度值超出/低于真实像素用橙色/蓝色着色。方框内的深度图是平滑的,表明预测值接近真实值。 同时,其相应的深度几何呈现出鞍形,符合预期。

当(x, y)处的真实深度值不在min(D)(x, y)和max(D)(x, y)的范围内时,上述方法可能会带来增加深度预测误差的潜在风险。为了解决这个问题,建议使用级联双深度。
4. 级联双深度
尽管在双深度中,令人鼓舞的估计偏差不大于|max(D)−min(D)|,但当估计偏差过大,超出了|max(D)−min(D)|的范围时,就会出现未发现的问题。原因是深度假设α2 ~ α1的范围固定,导致深度估计偏差较大。直观地说,当一个像素的估计深度不可靠时,应该增加深度假设的范围,以确保在搜索空间中包含真值。相反,这个范围可以适当缩小,以获得更可靠的估计。例如,UCS-Net利用概率分布的方差来反映不确定性,并动态调整相应采样深度的深度假设范围,从而产生较小的估计偏差。受此启发,尝试利用不确定性估计自适应调整深度假设的搜索范围。
首先采用概率分布的方差得到置信图,类似于UCS-Net(如下图(a)所示)。然而,通过方差获得的置信度图倾向于预测大多数区域的相似置信度水平,使得它在弱纹理区域或边缘预测置信度不可靠。此外,由于每个像素预测双深度,两个对应的置信值之间存在推理冲突。因此,需要找到一种合适的方式来表示双深度的不确定性,而不是仅仅依靠概率分布。

上图为置信图的比较。通过双深度得到的置信度图为遮挡区域或无效背景提供更准确的置信度。越淡的区域表示置信度越高。
在日常生活中,人们在用尺子测量一个物体时,通常会进行两次测量并比较结果。如果两个测量值之间存在较大差异,则认为测量精度较低。类似地,在双深度估计中,如果一个像素预测的最大和最小深度值之间的差异很大,我们认为估计偏差很大。因此,在下一次迭代中,该像素的深度搜索空间将被扩大。为了自适应调整深度假设的范围,使用max(D)(x, y)和min(D)(x, y)之间的绝对距离作为深度假设的边界,如下图所示。将一个像素对应的两个估计深度之间的欧氏距离定义为其不确定性,作为下一轮深度采样的间隔。给定深度假设的范围,可以构建特征体、代价体和概率分布,计算了改进后的对偶深度D',然后得到最终深度Dr。

置信度图。在融合过程中,使用置信度图以及阈值掩盖深度严重偏差的像素,从而防止它们投影到3D空间中。本文的置信度由
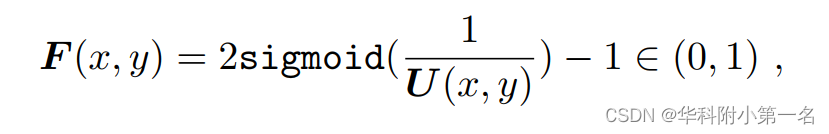
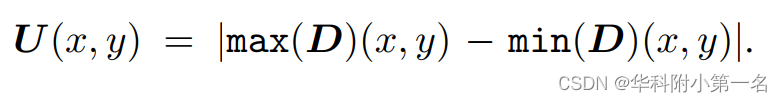
5. DMVSNet
为了将双深度方法嵌入到多视图立体(MVS)任务中,提出了一个从粗到细的MVS框架,命名为DMVSNet。如下图所示,双深度结构通过单应性变化被纳入深度回归阶段。
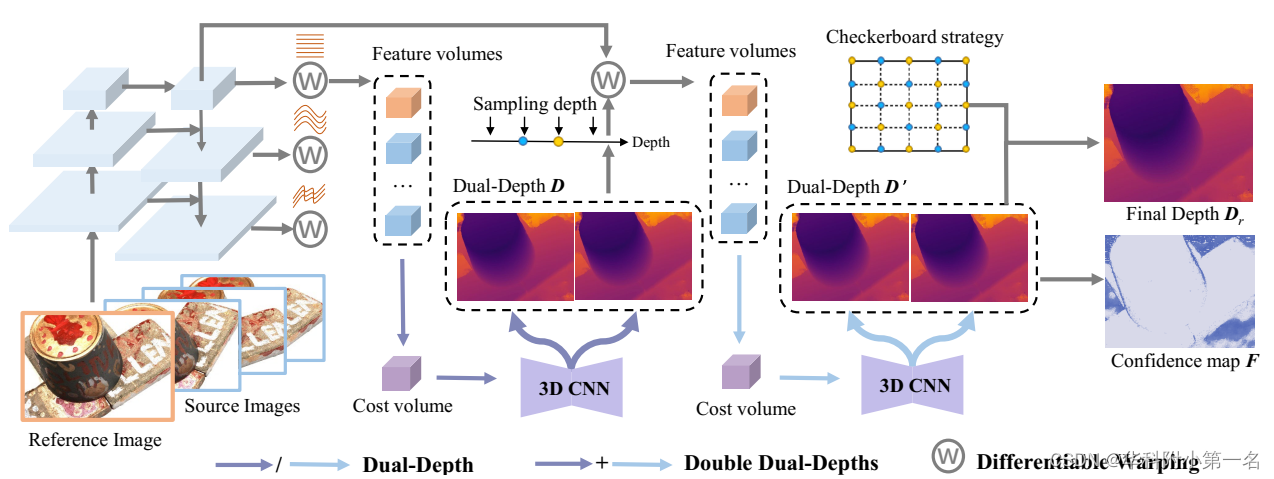
具体来说,采用特征金字塔网络(Feature Pyramid Network, FPN)来提取多尺度特征,如
CasMVSNet,并将输出通道加倍以获得级联双深度的特征图。然后,通过均匀采样深度假设对特征图进行变化,构造特征体。然后使用相似度度量将特征体聚合为代价体。利用三维CNN将代价体积转化为概率分布。为了获得双深度D,将3-D加倍来获得两个概率分布并生成深度图。使用自适应采样的深度假设重复此过程,以生成改进的双深度D',并利用该D'用棋盘选择策略来构造最终深度Dr。
训练损失。分别采用Lest和Lint来减少估计偏差和插值偏差。由于插值偏差是由子像素的深度误差引起的,因此在坐标(x+0.5, y+0.5)处额外监督子像素的深度。最终的损失函数是:
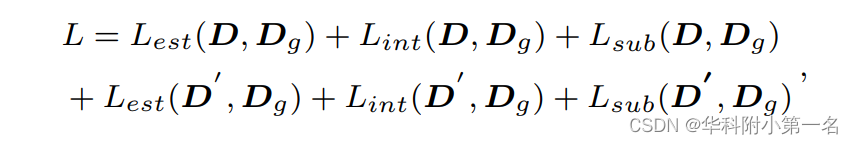
其中Lsub(D), Dg) = L1(sub.(con.(D),Dg)), con.(x)建议使用棋盘选择策略构建深度图,sub.表示在坐标(x+0.5, y+0.5)处取子像素。
6. 实验
6.1. 实现细节
为保证与DTU标准的一致性,将输入图像的大小调整为1152×864,输入图像的数量设置为5。为了训练和评估,输入图像的数量设置为9和11。
6.2. 与先进技术的比较