逻辑回归 Logistic Regression
3. 逻辑回归
在谈论逻辑回归时,一般的设定是,我们有数据点 X ∈ R p X\in\mathbb{R}^{p} X∈Rp和输出变量 Y ∈ { − 1 , + 1 } Y\in\{-1,+1\} Y∈{ −1,+1}。这是一个所谓的二元分类问题。
其任务是在预定的函数类别 F \mathcal{F} F中找到函数 f f f,使 sign f ( X ) \operatorname{sign} f(X) signf(X)能够尽可能好地预测 Y Y Y。一个常用的损失函数用来衡量预测函数的 “准确性”,其动机是错误分类的数量,即如果 f ( X ) f(X) f(X)的符号与真实输出 Y Y Y的符号不一致。我们使用0.1损失函数
L 0 , 1 ( Y , f ( X ) ) = { 1 if Y sign f ( X ) ≤ 0 0 otherwise (3. 1) L_{0,1}(Y, f(X))= \begin{cases}1 & \text { if } Y \operatorname{sign} f(X) \leq 0 \\ 0 & \text { otherwise }\end{cases} \tag{3. 1} L0,1(Y,f(X))={ 10 if Ysignf(X)≤0 otherwise (3. 1)
来完成这项工作。
为了在给定的训练样本集 ( x i , y i ) i = 1 , … , n \left(x_{i}, y_{i}\right)_{i=1, \ldots, n} (xi,yi)i=1,…,n中找到最佳预测函数 f ∈ F f\in\mathcal{F} f∈F,目标是找到最小化经验预期损失的 f ∈ F f\in\mathcal{F} f∈F。
1 n ∑ i = 1 n L 0 , 1 ( y i , f ( x i ) ) (3.2) \frac{1}{n} \sum_{i=1}^{n} L_{0,1}\left(y_{i}, f\left(x_{i}\right)\right) \tag{3.2} n1i=1∑nL0,1(yi,f(xi))(3.2)
然而,要找到这个问题的最小值在数值上是不可行的。即使只是考虑到一类仿射函数 F aff \mathcal{F}_{\text{aff }} Faff ,这也很难用数值来解决,因为损失函数既不连续也不可分。为了使其更容易解决,我们用一个凸损失函数(convex loss function) 来近似(非连续、非凸的)函数 L 0 , 1 L_{0,1} L0,1。
补充: 凸性 Convexity
定义3.1
令 C ⊂ R n \mathcal{C} \subset \mathbb{R}^{n} C⊂Rn是一个凸集,即对于任何一对元素 x 1 , x 2 ∈ C x_{1}, x_{2} \in \mathcal{C} x1,x2∈C来说 ,点 t x 2 + ( 1 − t ) x 1 t \mathbf{x}_{2}+(1-t) \mathbf{x}_{1} tx2+(1−t)x1 也是 C \mathcal{C} C的一个元素,对于所有 t ∈ [ 0 , 1 ] t \in[0,1] t∈[0,1]。如果对于所有 x 1 , x 2 ∈ C , t ∈ [ 0 , 1 ] \mathbf{x}_{1}, \mathbf{x}_{2} \in \mathcal{C}, t \in[0,1] x1,x2∈C,t∈[0,1],有 t f ( x 2 ) + ( 1 − t ) f ( x 1 ) ≥ f ( t x 2 + ( 1 − t ) x 1 ) t f\left(\mathbf{x}_{2}\right)+(1-t) f\left(\mathbf{x}_{1}\right) \geq f\left(t \mathbf{x}_{2}+(1-t) \mathbf{x}_{1}\right) tf(x2)+(1−t)f(x1)≥f(tx2+(1−t)x1),一个函数 f : C → R f: \mathcal{C} \rightarrow \mathbb{R} f:C→R被称为凸的。如果不等式是严格的,它就被称为严格凸的。
例: f : R + → R , x ↦ 1 / x f: \mathbb{R}^{+} \rightarrow \mathbb{R}, x \mapsto 1 / x f:R+→R,x↦1/x是凸的。
定理3.2
如果 f , g f,g f,g是凸的,那么
- h = max ( f , g ) h=\max (f, g) h=max(f,g)
- h = f + g h=f+g h=f+g
- h = g ∘ f h=g \circ f h=g∘f if g g g is non-decreasing

图3.1: L 0 , 1 L_{0,1} L0,1和对数损失,横轴为 t : = y f ( x ) t:=y f(x) t:=yf(x)。
定理3.3
严格凸函数的局部最小值与它的全局最小值相吻合。如果它存在的话,它是唯一的。
对于目前的问题,这意味着如果我们选择 f f f是仿射的(即 f ( x ) = f(\mathbf{x})= f(x)= w ⊤ x + b \mathbf{w}^{\top} \mathbf{x}+b w⊤x+b,根据定义是凸的),作为损失函数,我们使用凸的对数损失函数 ℓ ( t ) = l o g ( 1 + e − t ) \ell(t)=log \left(1+e^{-t}\right) ℓ(t)=log(1+e−t)。两者的结合是凸的。为了看到这一点,计算二阶导数并研究其黑森矩阵。结果发现,它只有非负的特征值。选择对数损失的原因是,它可以被解释为 L 0 , 1 L_{0,1} L0,1损失的凸近似值,如图3.1所示。给定一些训练数据 { ( x i , y i ) } i = 1 , … , N \left\{\left(\mathbf{x}_{i}, y_{i}\right)\right\}_{i=1, \ldots, N} { (xi,yi)}i=1,…,N,我们可以通过解决优化问题找到最佳参数 w w w和 b b b。
min w ∈ R p , b ∈ R 1 n ∑ i = 1 n log ( 1 + exp ( − y i ( w ⊤ x i + b ) ) ) . (3. 3) \min _{\mathbf{w} \in \mathbb{R}^{p}, b \in \mathbb{R}} \frac{1}{n} \sum_{i=1}^{n} \log \left(1+\exp \left(-y_{i}\left(\mathbf{w}^{\top} \mathbf{x}_{i}+b\right)\right)\right) . \tag{3. 3} w∈Rp,b∈Rminn1i=1∑nlog(1+exp(−yi(w⊤xi+b))).(3. 3)
成本函数的凸性
为简单起见,我们只考虑线性 f f f的成本函数。对仿射 f f f的扩展是直截了当的。让我们用以下方式表示它
F ( w ) = ∑ i = 1 n log ( 1 + exp ( − y i ( w ⊤ x i ) ) ) . F(\mathbf{w})=\sum_{i=1}^{n} \log \left(1+\exp \left(-y_{i}\left(\mathbf{w}^{\top} \mathbf{x}_{i}\right)\right)\right) . F(w)=i=1∑nlog(1+exp(−yi(w⊤xi))).
我们还使用辅助函数 g ( z ) = 1 / ( 1 + e − z ) g(z)=1 /\left(1+e^{-z}\right) g(z)=1/(1+e−z),其中 g ′ ( z ) = g ( z ) ( 1 − g ( z ) ) g^{\prime}(z)=g(z)(1-g(z)) g′(z)=g(z)(1−g(z))。那么, F F F的一次和二次偏导是
∂ ∂ w ( j ) F ( w ) = − ∑ i y i x i ( j ) ( 1 − g ( y i w ⊤ x i ) ) \frac{\partial}{\partial w^{(j)}} F(\mathbf{w})=-\sum_{i} y_{i} x_{i}^{(j)}\left(1-g\left(y_{i} \mathbf{w}^{\top} \mathbf{x}_{i}\right)\right) ∂w(j)∂F(w)=−i∑yixi(j)(1−g(yiw⊤xi))
与
∂ ∂ w ( j ) ∂ w ( k ) F ( w ) = ∑ i y i 2 x i ( j ) x i ( k ) g ( y i w ⊤ x i ) ( 1 − g ( y i w ⊤ x i ) ) , \frac{\partial}{\partial w^{(j)} \partial w^{(k)}} F(\mathbf{w})=\sum_{i} y_{i}^{2} x_{i}^{(j)} x_{i}^{(k)} g\left(y_{i} \mathbf{w}^{\top} \mathbf{x}_{i}\right)\left(1-g\left(y_{i} \mathbf{w}^{\top} \mathbf{x}_{i}\right)\right), ∂w(j)∂w(k)∂F(w)=i∑yi2xi(j)xi(k)g(yiw⊤xi)(1−g(yiw⊤xi)),
其中 y i 2 = 1 y_{i}^{2}=1 yi2=1。为了证明该函数为非负定值,我们需要证明对所有 a a a而言 a ⊤ ∇ 2 F a ≥ 0 a^{\top} \nabla^{2} F a \geq 0 a⊤∇2Fa≥0。我们定义辅助变量 P i = g ( y i w ⊤ x i ) ( 1 − g ( y i w ⊤ x i ) ) P_{i}=g\left(y_{i} \mathbf{w}^{\top} \mathbf{x}_{i}\right)\left(1-g\left(y_{i} \mathbf{w}^{\top} \mathbf{x}_{i}\right)\right) Pi=g(yiw⊤xi)(1−g(yiw⊤xi))和 ρ i ( j ) = x i ( j ) P i \rho_{i}^{(j)}=x_{i}^{(j)} \sqrt{P_{i}} ρi(j)=xi(j)Pi。那么有
a ⊤ ∇ 2 F a = ∑ i ∑ j , k a i a j x i ( j ) x i ( k ) P i = ∑ i a ⊤ ρ i ρ i ⊤ a ≥ 0. a^{\top} \nabla^{2} F a=\sum_{i} \sum_{j, k} a_{i} a_{j} x_{i}^{(j)} x_{i}^{(k)} P_{i}=\sum_{i} a^{\top} \rho_{i} \rho_{i}^{\top} a \geq 0 . a⊤∇2Fa=i∑j,k∑aiajxi(j)xi(k)Pi=i∑a⊤ρiρi⊤a≥0.
这对任何凸函数和仿射函数的联合都是成立的。
在下文中,我们将对这个优化问题进行概率性解释。首先,请注意,鉴于观察到的 Y = y Y=y Y=y的条件概率 x \mathrm{x} x被定义为
Pr ( Y = y ∣ x ) = exp ( − ℓ ( y , f ( x ) ) ) = 1 1 + exp ( − y ( w ⊤ x + b ) ) . (3. 4) \operatorname{Pr}(Y=y \mid x)=\exp (-\ell(y, f(x)))=\frac{1}{1+\exp \left(-y\left(\mathbf{w}^{\top} \mathbf{x}+b\right)\right)} . \tag{3. 4} Pr(Y=y∣x)=exp(−ℓ(y,f(x)))=1+exp(−y(w⊤x+b))1.(3. 4)
为了找到(3.3)的解决方案,通常的做法是使用基于梯度的方法。最简单的形式是梯度下降法,在一个给定的迭代点,我们计算梯度,然后在该梯度的负方向迈出一步。函数 F ( w , b ) = ∑ i log ( 1 + exp ( − y i ( w ⊤ x i + b ) ) ) F(\mathbf{w}, b)=\sum_{i} \log \left(1+\exp \left(-y_{i}\left(\mathbf{w}^{\top} \mathbf{x}_{i}+b\right)\right)\right) F(w,b)=∑ilog(1+exp(−yi(w⊤xi+b)))可以通过计算偏导来确定
∂ ∂ w ( k ) F ( w , b ) = ∑ i = 1 n exp ( − y i ( w ⊤ x i + b ) ) 1 + exp ( − y i ( w ⊤ x i + b ) ) ( − y i x i ( k ) ) = ∑ i = 1 n 1 1 + exp ( y i ( w ⊤ x i + b ) ) ( − y i x i ( k ) ) = ∑ i ∣ y i = 1 1 1 + exp ( w ⊤ x i + b ) ( − x i ( k ) ) + ∑ i ∣ y i = − 1 1 1 + exp ( − w ⊤ x i + b ) ( x i ( k ) ) \begin{aligned} \frac{\partial}{\partial w^{(k)}} F(\mathbf{w}, b)&=\sum_{i=1}^{n} \frac{\exp \left(-y_{i}\left(\mathbf{w}^{\top} \mathbf{x}_{i}+b\right)\right)}{1+\exp \left(-y_{i}\left(\mathbf{w}^{\top} \mathbf{x}_{i}+b\right)\right)}\left(-y_{i} x_{i}^{(k)}\right) \\ &=\sum_{i=1}^{n} \frac{1}{1+\exp \left(y_{i}\left(\mathbf{w}^{\top} \mathbf{x}_{i}+b\right)\right)}\left(-y_{i} x_{i}^{(k)}\right) \\ &=\sum_{i \mid y_{i}=1} \frac{1}{1+\exp \left(\mathbf{w}^{\top} \mathbf{x}_{i}+b\right)}\left(-x_{i}^{(k)}\right)+\sum_{i \mid y_{i}=-1} \frac{1}{1+\exp \left(-\mathbf{w}^{\top} \mathbf{x}_{i}+b\right)}\left(x_{i}^{(k)}\right) \end{aligned} ∂w(k)∂F(w,b)=i=1∑n1+exp(−yi(w⊤xi+b))exp(−yi(w⊤xi+b))(−yixi(k))=i=1∑n1+exp(yi(w⊤xi+b))1(−yixi(k))=i∣yi=1∑1+exp(w⊤xi+b)1(−xi(k))+i∣yi=−1∑1+exp(−w⊤xi+b)1(xi(k))
系数 1 / ( 1 + exp ( w ⊤ x i + b ) ) 1 /\left(1+\exp \left(\mathbf{w}^{\top} \mathbf{x}_{i}+b\right)\right) 1/(1+exp(w⊤xi+b))和 1 / ( 1 + exp ( − w ⊤ x i + b ) ) 1 /\left(1+\exp \left(-\mathbf{w}^{\top} \mathbf{x}_{i}+b\right)\right) 1/(1+exp(−w⊤xi+b))是错误的预测概率。(参照(3.4))
因此,当我们朝着负梯度的方向迈出一步时,我们就会朝着这些错误的 "反方向 "前进。这就是为什么梯度下降方法也被称为错误驱动方法的原因。当前模型的错误(这里由一些权重 ( w , b ) ) (\mathbf{w}, b)) (w,b))被用来改进它。梯度指向的方向是使当前模型中的错误最小化。
总的来说:
逻辑回归是一种监督分类方法,决策函数是仿射的,损失用 L ( y , f ( x ) ) = log ( 1 + e − y f ( x ) ) ) \left.L(y, f(\mathbf{x}))=\log \left(1+e^{-y f(\mathbf{x})}\right)\right) L(y,f(x))=log(1+e−yf(x)))衡量。最佳参数 w ⋆ , b ⋆ \mathbf{w}^{\star}, b^{\star} w⋆,b⋆是通过最小化经验预期损失而找到的,即 min w , b 1 N ∑ log ( 1 + e − y i ( w ⊤ x i + b ) ) \min _{\mathbf{w}, b} \frac{1}{N} \sum \log \left(1+e^{-y_{i}\left(\mathbf{w}^{\top} \mathbf{x}_{i}+b\right)}\right) minw,bN1∑log(1+e−yi(w⊤xi+b))。一旦确定了最佳的 w ⋆ , b ⋆ \mathbf{w}^{\star}, b^{\star} w⋆,b⋆,我们就可以通过计算 sign ( w ⋆ ⊤ x new + b ⋆ ) \operatorname{sign}\left(\mathbf{w}^{\star \top} \mathbf{x}_{\text {new }}+b^{\star}\right) sign(w⋆⊤xnew +b⋆)对一个新数据点 w ⋆ , b ⋆ \mathbf{w}^{\star}, b^{\star} w⋆,b⋆进行分类。我们还可以通过公式(3.4)计算出这种分类正确的概率。
3.1逻辑回归的替代方法
首先,请注意,逻辑回归这个名字可能会产生误导,因为事实上逻辑回归并不是一种回归方法,而是一种分类方法。上一节更多的是以优化为目的,而在这里,我们提供了一种更多的统计方法来处理逻辑回归。
例:
我们试图预测在某些参数下的死亡概率。让 x 1 x_{1} x1为一个人的年龄, x 2 x_{2} x2为性别(0对应男性,1对应女性), x 3 x_{3} x3为胆固醇水平。我们假设可以将这些数值以线性方式组合起来,从而得到一个与死亡概率有某种关联的实际数值
w 0 + w 1 x 1 + w 2 x 2 + w 3 x 3 = w ⊤ x w_{0}+w_{1} x_{1}+w_{2} x_{2}+w_{3} x_{3}=\mathbf{w}^{\top} \mathbf{x} w0+w1x1+w2x2+w3x3=w⊤x
有 x = [ 1 , x 1 , x 2 , x 3 ] ⊤ , w = [ w 0 , w 1 , w 2 , w 3 ] ⊤ \mathbf{x}=\left[1, x_{1}, x_{2}, x_{3}\right]^{\top}, \mathbf{w}=\left[w_{0}, w_{1}, w_{2}, w_{3}\right]^{\top} x=[1,x1,x2,x3]⊤,w=[w0,w1,w2,w3]⊤。 w i w_{i} wi的值称为权重, w 0 w_{0} w0称为偏置。得到的值在 R \mathbb{R} R中。为了将其塑造成一个概率,我们需要一个函数 σ \sigma σ,将这个值压缩到 [ 0 , 1 ] [0,1] [0,1]的区间内。一个能实现这一目的的函数是逻辑回归函数
σ ( a ) = 1 1 + e − a (3.5) \sigma(a)=\frac{1}{1+e^{-a}} \tag{3.5} σ(a)=1+e−a1(3.5)
得到的模型是 P ( 死亡 ∣ x ) = σ ( w ⊤ x ) P(\text{死亡}\mid x)=\sigma\left(\mathbf{w}^{\top} \mathbf{x}\right) P(死亡∣x)=σ(w⊤x)。
更一般地说,我们考虑二元分类问题的训练数据 D = { ( x 1 , z 1 ) , … , ( x n , z n ) } , x i ∈ R d , z i ∈ { 0 , 1 } D=\left\{\left(\mathbf{x}_{1}, z_{1}\right), \ldots,\left(\mathbf{x}_{n}, z_{n}\right)\right\}, \mathbf{x}_{i} \in \mathbb{R}^{d}, z_{i} \in\{0,1\} D={ (x1,z1),…,(xn,zn)},xi∈Rd,zi∈{ 0,1} ,输入和输出变量的依赖性模型为 z i ∝ Bernoulli ( σ ( w ⊤ x ) ) z_{i} \propto \operatorname{Bernoulli}\left(\sigma\left(\mathbf{w}^{\top} \mathbf{x}\right)\right) zi∝Bernoulli(σ(w⊤x)),其中我们假定 z i z_{i} zi是独立的。
为了训练这个模型,我们要找到给定 D D D的 w w w的最大似然估计,即
w M L E = arg max w Pr ( D ∣ w ) \mathbf{w}_{\mathrm{MLE}}=\arg \max _{\mathbf{w}} \operatorname{Pr}(D \mid \mathbf{w}) wMLE=argwmaxPr(D∣w)
有
Pr ( D ∣ w ) = ∏ i = 1 n Pr ( z i ∣ x i , w ) = ∏ i = 1 n σ ( w ⊤ x i ) z i ( 1 − σ ( w ⊤ x i ) ) 1 − z i (3.6) \operatorname{Pr}(D \mid \mathbf{w})=\prod_{i=1}^{n} \operatorname{Pr}\left(z_{i} \mid \mathbf{x}_{i}, \mathbf{w}\right)=\prod_{i=1}^{n} \sigma\left(\mathbf{w}^{\top} \mathbf{x}_{i}\right)^{z_{i}}\left(1-\sigma\left(\mathbf{w}^{\top} \mathbf{x}_{i}\right)\right)^{1-z_{i}} \tag{3.6} Pr(D∣w)=i=1∏nPr(zi∣xi,w)=i=1∏nσ(w⊤xi)zi(1−σ(w⊤xi))1−zi(3.6)
出于优化目的,通常使用上述条件概率的负 log \log log,即
L ( w ) = − log Pr ( D ∣ w ) = − ∑ i = 1 n z i log ( σ ( w ⊤ x i ) ) + ( 1 − z i ) log ( 1 − σ ( w ⊤ x i ) ) . (3.7) L(\mathbf{w})=-\log \operatorname{Pr}(D \mid w)=-\sum_{i=1}^{n} z_{i} \log \left(\sigma\left(\mathbf{w}^{\top} \mathbf{x}_{i}\right)\right)+\left(1-z_{i}\right) \log \left(1-\sigma\left(\mathbf{w}^{\top} \mathbf{x}_{i}\right)\right) \text {. }\tag{3.7} L(w)=−logPr(D∣w)=−i=1∑nzilog(σ(w⊤xi))+(1−zi)log(1−σ(w⊤xi)). (3.7)
各自的梯度(相对于 w w w)由以下公式给出
g = ∇ w L ( w ) = ∑ i = 1 n ( σ ( w ⊤ x i ) − z i ) x i = X ( σ ( X ⊤ w ) − z ) (3.8) \mathbf{g}=\nabla_{\mathbf{w}} L(\mathbf{w})=\sum_{i=1}^{n}\left(\sigma\left(\mathbf{w}^{\top} \mathbf{x}_{i}\right)-z_{i}\right) \mathbf{x}_{i}=\mathbf{X}\left(\sigma\left(\mathbf{X}^{\top} \mathbf{w}\right)-\mathbf{z}\right)\tag{3.8} g=∇wL(w)=i=1∑n(σ(w⊤xi)−zi)xi=X(σ(X⊤w)−z)(3.8)
与 X = [ x 1 , … , x n ] ∈ R d × n \mathbf{X}=\left[\mathbf{x}_{1}, \ldots, \mathbf{x}_{n}\right] \in \mathbb{R}^{d \times n} X=[x1,…,xn]∈Rd×n。相应的 w w w的黑塞矩阵 H \mathbf{H} H给出为
H = ∇ w 2 L ( w ) = X B X ⊤ (3.9) \mathbf{H}=\nabla_{\mathbf{w}}^{2} L(\mathbf{w})=\mathbf{X B X}^{\top}\tag{3.9} H=∇w2L(w)=XBX⊤(3.9)
有 B = diag ( σ ( w ⊤ x i ) ( 1 − σ ( w ⊤ x i ) ) ) ∈ R n × n \mathbf{B}=\operatorname{diag}\left(\sigma\left(\mathbf{w}^{\top} \mathbf{x}_{i}\right)\left(1-\sigma\left(\mathbf{w}^{\top} \mathbf{x}_{i}\right)\right)\right) \in \mathbb{R}^{n \times n} B=diag(σ(w⊤xi)(1−σ(w⊤xi)))∈Rn×n 。黑塞矩阵 H \mathbf{H} H是半正定的,因此 L L L是凸的。
假设Hessian是可逆的。那么牛顿方法的迭代形式为
w t + 1 = w t − H − 1 g = w t − ( X B X ⊤ ) − 1 X ( σ ( X ⊤ w ) − Z ) = ( X B X ⊤ ) − 1 X B r t (3.10) \begin{aligned} \mathbf{w}_{t+1} &=\mathbf{w}_{t}-\mathbf{H}^{-1} \mathbf{g} \\ &=\mathbf{w}_{t}-\left(\mathbf{X B X}^{\top}\right)^{-1} \mathbf{X}\left(\sigma\left(\mathbf{X}^{\top} \mathbf{w}\right)-\mathbf{Z}\right) \\ &=\left(\mathbf{X B X}^{\top}\right)^{-1} \mathbf{X B r}_{t} \end{aligned}\tag{3.10} wt+1=wt−H−1g=wt−(XBX⊤)−1X(σ(X⊤w)−Z)=(XBX⊤)−1XBrt(3.10)
有 r t = X ⊤ w t − B − 1 ( σ ( X ⊤ w t ) − z ) \mathbf{r}_{t}=\mathbf{X}^{\top} \mathbf{w}_{t}-\mathbf{B}^{-1}\left(\sigma\left(\mathbf{X}^{\top} \mathbf{w}_{t}\right)-\mathbf{z}\right) rt=X⊤wt−B−1(σ(X⊤wt)−z). 这就是加权最小二乘法问题的解决方案 arg min w . ∑ i b i ( r i − w ⊤ x i ) 2 \arg\min _{\mathbf{w}}. \sum_{i} b_{i}\left(r_{i}-\mathbf{w}^{\top} \mathbf{x}_{i}\right)^{2} argminw.∑ibi(ri−w⊤xi)2.
练习:证明方程(3.7)与方程(3.3)在标量因子 1 / n 1 / n 1/n以内是等价的。
proof
首先,注意 log ( σ ( w ⊤ x ) ) = − log ( 1 + exp ( − w ⊤ x ) ) \log \left(\sigma\left(\mathbf{w}^{\top} \mathbf{x}\right)\right)=-\log \left(1+\exp \left(-\mathbf{w}^{\top} \mathbf{x}\right)\right) log(σ(w⊤x))=−log(1+exp(−w⊤x)) 和 log ( 1 − σ ( w ⊤ x ) ) = − log ( 1 + exp ( w ⊤ x ) ) \log \left(1-\sigma\left(\mathbf{w}^{\top} \mathbf{x}\right)\right)=-\log \left(1+\exp \left(\mathbf{w}^{\top} \mathbf{x}\right)\right) log(1−σ(w⊤x))=−log(1+exp(w⊤x))。因此,公式(3.7)等价于
L ( w ) = ∑ i = 1 n z i log ( 1 + exp ( − w ⊤ x i ) ) + ( 1 − z i ) log ( 1 + exp ( w ⊤ x i ) ) (3.11) L(\mathbf{w})=\sum_{i=1}^{n} z_{i} \log \left(1+\exp \left(-\mathbf{w}^{\top} \mathbf{x}_{i}\right)\right)+\left(1-z_{i}\right) \log \left(1+\exp \left(\mathbf{w}^{\top} \mathbf{x}_{i}\right)\right) \tag{3.11} L(w)=i=1∑nzilog(1+exp(−w⊤xi))+(1−zi)log(1+exp(w⊤xi))(3.11)
由于 z i z_{i} zi不是0就是1,我们可以将和改写为
L ( w ) = ∑ z i = 1 log ( 1 + exp ( − w ⊤ x i ) ) + ∑ z i = 0 log ( 1 + exp ( w ⊤ x i ) ) . (3.12) L(\mathbf{w})=\sum_{z_{i}=1} \log \left(1+\exp \left(-\mathbf{w}^{\top} \mathbf{x}_{i}\right)\right)+\sum_{z_{i}=0} \log \left(1+\exp \left(\mathbf{w}^{\top} \mathbf{x}_{i}\right)\right) \tag{3.12}. L(w)=zi=1∑log(1+exp(−w⊤xi))+zi=0∑log(1+exp(w⊤xi)).(3.12)
现在,将标签 z i z_{i} zi与(3.3)中的标签 y i y_{i} yi相比较,我们看到 z i = 1 ⇔ y i = 1 z_{i}=1\Leftrightarrow y_{i}=1 zi=1⇔yi=1, z i = 0 ⇔ y i = − 1 z_{i}=0\Leftrightarrow y_{i}=-1 zi=0⇔yi=−1,所以
L ( w ) = ∑ y i = 1 log ( 1 + exp ( − y i w ⊤ x i ) ) + ∑ y i = − 1 log ( 1 + exp ( − y i w ⊤ x i ) ) = ∑ i = 1 n log ( 1 + exp ( − y i w ⊤ x i ) ) , (3.13) \begin{aligned} L(\mathbf{w}) &=\sum_{y_{i}=1} \log \left(1+\exp \left(-y_{i} \mathbf{w}^{\top} \mathbf{x}_{i}\right)\right)+\sum_{y_{i}=-1} \log \left(1+\exp \left(-y_{i} \mathbf{w}^{\top} \mathbf{x}_{i}\right)\right) \\ &=\sum_{i=1}^{n} \log \left(1+\exp \left(-y_{i} \mathbf{w}^{\top} \mathbf{x}_{i}\right)\right), \end{aligned}\tag{3.13} L(w)=yi=1∑log(1+exp(−yiw⊤xi))+yi=−1∑log(1+exp(−yiw⊤xi))=i=1∑nlog(1+exp(−yiw⊤xi)),(3.13)
与方程(3.3)相吻合,其系数为 1 / n 1/n 1/n。
3.2 线性可分性和逻辑回归
需要注意的是,逻辑回归在线性可分离的训练集上可以过度拟合。当两个类1和 − 1 -1 −1是线性可分离的,我们可以找到一个超平面 ( w s , b s ) \left(\mathbf{w}_{s}, b_{s}\right) (ws,bs),使得以下不等式成立。
y i ( w s ⊤ x i + b s ) > 0 ∀ i . (3.14) y_{i}\left(\mathbf{w}_{s}^{\top} \mathbf{x}_{i}+b_{s}\right)>0 \quad \forall i .\tag{3.14} yi(ws⊤xi+bs)>0∀i.(3.14)
考虑以下定理。
定理3.4
对于线性可分离的、非空的训练集,损失函数
F ( w , b ) = ∑ i = 1 n log ( 1 + exp ( − y i ( w ⊤ x i + b ) ) ) (3.15) F(\mathbf{w}, b)=\sum_{i=1}^{n} \log \left(1+\exp \left(-y_{i}\left(\mathbf{w}^{\top} \mathbf{x}_{i}+b\right)\right)\right)\tag{3.15} F(w,b)=i=1∑nlog(1+exp(−yi(w⊤xi+b)))(3.15)
在 R p + 1 \mathbb{R}^{p+1} Rp+1中没有全局最小值。
证明
首先让我们来描述 F F F的全局最小值。它是 ( w ∗ , b ∗ ) ∈ R p + 1 \left(\mathbf{w}^{*}, b^{*}\right) \in \mathbb{R}^{p+1} (w∗,b∗)∈Rp+1 中的一个点,即
F ( w , b ) ≥ F ( w ∗ , b ∗ ) ∀ ( w , b ) ∈ R p + 1 (3.16) F(\mathbf{w}, b) \geq F\left(\mathbf{w}^{*}, b^{*}\right) \quad \forall(\mathbf{w}, b) \in \mathbb{R}^{p+1}\tag{3.16} F(w,b)≥F(w∗,b∗)∀(w,b)∈Rp+1(3.16)
存在。如果训练集是非空的,那么损失函数就是严格的正定的。因此, F F F的最小值是某个正数 ε \varepsilon ε,即
F ( w ∗ , b ∗ ) = ε > 0. (3.17) F\left(\mathbf{w}^{*}, b^{*}\right)=\varepsilon>0 .\tag{3.17} F(w∗,b∗)=ε>0.(3.17)
现在我们将通过矛盾法来证明全局最小值的缺失。假设有一个点 ( w s , b s ) \left(\mathbf{w}_{s}, b_{s}\right) (ws,bs)和一个实数 ε > 0 \varepsilon>0 ε>0,使得以下条件成立。
y i ( w s ⊤ x i + b s ) > 0 ∀ i and F ( w , b ) ≥ ε ∀ ( w , b ) ∈ R p + 1 . (3.18) y_{i}\left(\mathbf{w}_{s}^{\top} \mathbf{x}_{i}+b_{s}\right)>0 \forall i \text { and } F(\mathbf{w}, b) \geq \varepsilon \forall(\mathbf{w}, b) \in \mathbb{R}^{p+1} .\tag{3.18} yi(ws⊤xi+bs)>0∀i and F(w,b)≥ε∀(w,b)∈Rp+1.(3.18)
对于每个 i i i,定义以下标量值
ξ i = y i ( w s ⊤ x i + b s ) (3.19) \xi_{i}=y_{i}\left(\mathbf{w}_{s}^{\top} \mathbf{x}_{i}+b_{s}\right)\tag{3.19} ξi=yi(ws⊤xi+bs)(3.19)
考虑以下方程
f i ( h ) = log ( 1 + exp ( − h ξ i ) ) (3.20) f_{i}(h)=\log \left(1+\exp \left(-h \xi_{i}\right)\right)\tag{3.20} fi(h)=log(1+exp(−hξi))(3.20)
很容易看出, x i i xi_{i} xii对于任何 i i i都是严格的正数,因此 f i ( h ) f_{i}(h) fi(h)随着 h h h接近 ∞ \infty ∞而接近0。如果我们考虑 i i i的总和,即
lim h → ∞ ∑ i = 1 n f i ( h ) = F ( h w s , h b s ) = 0. (3.21) \lim _{h \rightarrow \infty} \sum_{i=1}^{n} f_{i}(h)=F\left(h \mathbf{w}_{s}, h b_{s}\right)=0 .\tag{3.21} h→∞limi=1∑nfi(h)=F(hws,hbs)=0.(3.21)
换句话说,对于任何 ε > 0 \varepsilon>0 ε>0,我们可以找到一个实数 η > 0 \eta>0 η>0,这样,对于任何 h ≥ η h\geq\eta h≥η,下面的不等式都成立。
F ( h w s , h b s ) < ε (3.22) F\left(h \mathbf{w}_{s}, h b_{s}\right)<\varepsilon\tag{3.22} F(hws,hbs)<ε(3.22)
这直接与假设(3.18)相矛盾,因为我们可以选择 w = h w s \mathrm{w} = h \mathrm{w}_{s} w=hws和 b = h b s b = h b_{s} b=hbs,且有 h ≥ η h \geq \eta h≥η。
证明表明,一旦找到一个分离超平面,损失函数的值总是可以通过增加超平面参数的大小而进一步降低。请注意,这对任何分离类的超平面都是真实的。在实践中,一个优化算法可以选择一个具有 "坏 "位置和方向的超平面,并增加参数的大小,直到达到最大迭代次数。
为了防止这种情况,通常通过引入正则器来惩罚 ( w , b ) (\mathbf{w}, b) (w,b)的大小,例如通过固定一个实数常数 λ > 0 \lambda>0 λ>0并将原始成本函数调整为
F ~ ( w , b ) = F ( w , b ) + λ ( ∥ w ∥ 2 + b 2 ) (3.23) \tilde{F}(\mathbf{w}, b) = F(\mathbf{w}, b)+\lambda\left(\|\mathbf{w}\|^{2}+b^{2}\right)\tag{3.23} F~(w,b)=F(w,b)+λ(∥w∥2+b2)(3.23)
3.3 逻辑回归的额外内容
任务1. 考虑为数据样本 y ∈ { − 1 , 1 } y\in\{-1,1\} y∈{ −1,1}分配一个标签的二元分类问题。通过逻辑回归的方式对数据样本 y ∈ { − 1 , 1 } y \in\{-1,1\} y∈{ −1,1}进行二元分类。给定一个训练集 { ( x 1 , y 1 ) , … , ( x N , y N ) } \left\{\left(\mathbf{x}_{1}, y_{1}\right), \ldots,\left(\mathbf{x}_{N}, y_{N}\right)\right\} { (x1,y1),…,(xN,yN)}的标记数据。回顾一下,损失函数是由
L ( w , b ) = ∑ i = 1 N log ( 1 + exp ( − y i ( w ⊤ x i + b ) ) ) L(\mathbf{w}, b)=\sum_{i=1}^{N} \log \left(1+\exp \left(-y_{i}\left(\mathbf{w}^{\top} \mathbf{x}_{i}+b\right)\right)\right) L(w,b)=i=1∑Nlog(1+exp(−yi(w⊤xi+b)))
3.3.1 梯度 ∇ w , b L \nabla_{\mathbf{w}, b} L ∇w,bL
解决方法: 根据链式法则,我们有
∇ b L = ∑ i = 1 N ∇ b ( 1 + exp ( − y i ( w ⊤ x i + b ) ) ) 1 + exp ( − y i ( w ⊤ x i + b ) ) = − ∑ i = 1 N y i exp ( − y i ( w ⊤ x i + b ) ) 1 + exp ( − y i ( w ⊤ x i + b ) ) = − ∑ i = 1 N y i 1 + exp ( y i ( w ⊤ x i + b ) ) \begin{aligned} \nabla_{b} L &=\sum_{i=1}^{N} \frac{\nabla_{b}\left(1+\exp \left(-y_{i}\left(\mathbf{w}^{\top} \mathbf{x}_{i}+b\right)\right)\right)}{1+\exp \left(-y_{i}\left(\mathbf{w}^{\top} \mathbf{x}_{i}+b\right)\right)} \\ &=-\sum_{i=1}^{N} y_{i} \frac{\exp \left(-y_{i}\left(\mathbf{w}^{\top} \mathbf{x}_{i}+b\right)\right)}{1+\exp \left(-y_{i}\left(\mathbf{w}^{\top} \mathbf{x}_{i}+b\right)\right)} \\ &=-\sum_{i=1}^{N} \frac{y_{i}}{1+\exp \left(y_{i}\left(\mathbf{w}^{\top} \mathbf{x}_{i}+b\right)\right)} \end{aligned} ∇bL=i=1∑N1+exp(−yi(w⊤xi+b))∇b(1+exp(−yi(w⊤xi+b)))=−i=1∑Nyi1+exp(−yi(w⊤xi+b))exp(−yi(w⊤xi+b))=−i=1∑N1+exp(yi(w⊤xi+b))yi
据此,我们得到
∇ w L = ∑ i = 1 N 1 1 + exp ( − y i ( w ⊤ x i + b ) ) ∇ w ( 1 + exp ( − y i ( w ⊤ x i + b ) ) ) = − ∑ i = 1 N y i exp ( − y i ( w ⊤ x i + b ) ) 1 + exp ( − y i ( w ⊤ x i + b ) ) x i = − ∑ i = 1 N y i 1 + exp ( y i ( w ⊤ x i + b ) ) x i \begin{aligned} \nabla_{\mathbf{w}} L &=\sum_{i=1}^{N} \frac{1}{1+\exp \left(-y_{i}\left(\mathbf{w}^{\top} \mathbf{x}_{i}+b\right)\right)} \nabla_{\mathbf{w}}\left(1+\exp \left(-y_{i}\left(\mathbf{w}^{\top} \mathbf{x}_{i}+b\right)\right)\right) \\ &=-\sum_{i=1}^{N} y_{i} \frac{\exp \left(-y_{i}\left(\mathbf{w}^{\top} \mathbf{x}_{i}+b\right)\right)}{1+\exp \left(-y_{i}\left(\mathbf{w}^{\top} \mathbf{x}_{i}+b\right)\right)} \mathbf{x}_{i} \\ &=-\sum_{i=1}^{N} \frac{y_{i}}{1+\exp \left(y_{i}\left(\mathbf{w}^{\top} \mathbf{x}_{i}+b\right)\right)} \mathbf{x}_{i} \end{aligned} ∇wL=i=1∑N1+exp(−yi(w⊤xi+b))1∇w(1+exp(−yi(w⊤xi+b)))=−i=1∑Nyi1+exp(−yi(w⊤xi+b))exp(−yi(w⊤xi+b))xi=−i=1∑N1+exp(yi(w⊤xi+b))yixi
3.3.2 损失函数的全局最小值
假设训练集的两个类是线性可分离的,即有一个权重向量 w s ∈ R p \mathbf{w}_{s} \in \mathbb{R}^{p} ws∈Rp,并且存在一个偏置 b s b_{s} bs,从而
y i ( w s ⊤ x i + b s ) > 0 ∀ i y_{i}\left(\mathbf{w}_{s}^{\top} \mathbf{x}_{i}+b_{s}\right)>0 \quad \forall i yi(ws⊤xi+bs)>0∀i
成立. 证明在此假设下,损失函数在 ( w ∗ , b ∗ ) ∈ R p + 1 \left(\mathbf{w}^{*}, b^{*}\right) \in \mathbb{R}^{p+1} (w∗,b∗)∈Rp+1中没有全局最小值。
解决方法:
L L L的全局最小值是指 ( w ∗ , b ∗ ) ∈ R p + 1 \left(w^{*}, b^{*}\right) \in \mathbb{R}^{p+1} (w∗,b∗)∈Rp+1中的一对,这样
L ( w , b ) ≥ L ( w ∗ , b ∗ ) ∀ ( w , b ) ∈ R p + 1 L(\mathbf{w}, b) \geq L\left(\mathbf{w}^{*}, b^{*}\right) \quad \forall(\mathbf{w}, b) \in \mathbb{R}^{p+1} L(w,b)≥L(w∗,b∗)∀(w,b)∈Rp+1
成立。此外,对于非空的训练集, L L L是严格的正数,因此我们可以得出结论
L ( w ∗ , b ∗ ) = ε > 0 L\left(\mathrm{w}^{*}, b^{*}\right)=\varepsilon>0 L(w∗,b∗)=ε>0
假设有这样一个点存在。让我们定义
z i = y i ( w s ⊤ x i + b s ) z_{i}=y_{i}\left(\mathbf{w}_{s}^{\top} \mathbf{x}_{i}+b_{s}\right) zi=yi(ws⊤xi+bs)
请注意, z i z_{i} zi对于每一个 i i i都是严格的正数。考虑函数
f ( h ) = ∑ i = 1 N log ( 1 + exp ( − h z i ) ) f(h)=\sum_{i=1}^{N} \log \left(1+\exp \left(-h z_{i}\right)\right) f(h)=i=1∑Nlog(1+exp(−hzi))
由于每个和都随着 h h h接近 ∞ \infty ∞而接近0, f ( h ) f(h) f(h)也是如此,即
lim h → ∞ f ( h ) = 0 \lim _{h \rightarrow \infty} f(h)=0 h→∞limf(h)=0
观察平等的情况
f ( h ) = L ( h w s , h b s ) f(h)=L\left(h \mathbf{w}_{\mathbf{s}}, h b_{s}\right) f(h)=L(hws,hbs)
这意味着对于任何 ε > 0 \varepsilon>0 ε>0,我们可以在 R \mathbb{R} R中找到一个 h h h,并设定 ( w , b ) = ( h w s , h b s ) (\mathbf{w}, b)= \left(h\mathrm{w}_{\mathrm{s}}, h b_{s}\right) (w,b)=(hws,hbs) ,这样
L ( w , b ) < ε L(\mathbf{w}, b)<\varepsilon L(w,b)<ε
成立,这与 ( w ∗ , b ∗ ) \left(\mathbf{w}^{*}, b^{*}\right) (w∗,b∗)的假设相矛盾, L ( w ∗ , b ∗ ) = ε L\left(\mathbf{w}^{*}, b^{*}\right)=\varepsilon L(w∗,b∗)=ε是一个全局最小。
请注意, ( w s , b s ) \left(\mathbf{w}_{s}, b_{s}\right) (ws,bs)所描述的超平面不一定是任何意义上的最优。根据算法的不同,这可能会导致 "非理想 "的超平面描述符的常数不断增加。
3.3.3 过拟合
为了避免3.3.2中的情况,可以通过增加一个平方范数控制器来惩罚 ( w , b ) (w,b) (w,b)的范数。考虑修改后的损失函数
L ~ ( w , b ) = L ( w , b ) + λ ( ∥ w ∥ 2 + b 2 ) \tilde{L}(\mathbf{w}, b)=L(\mathbf{w}, b)+\lambda\left(\|\mathbf{w}\|^{2}+b^{2}\right) L~(w,b)=L(w,b)+λ(∥w∥2+b2)
其中 λ > 0 \lambda>0 λ>0是一个实值常数。计算梯度 ∇ w , b L ~ \nabla_{\mathbf{w}, b} \tilde{L} ∇w,bL~ 。
解决方法:
由于导数的线性特性,我们有
∇ b L ~ = ∇ b L + 2 λ b \nabla_{b} \tilde{L}=\nabla_{b} L+2 \lambda b ∇bL~=∇bL+2λb
和
∇ w L ~ = ∇ w L + 2 λ w \nabla_{\mathrm{w}} \tilde{L}=\nabla_{\mathrm{w}} L+2 \lambda_{\mathrm{w}} ∇wL~=∇wL+2λw
3.4 逻辑回归实例
下面的练习是建立在提取的特征表示之上的,但我们要用手动实现逻辑回归,即通过最小化讲义中第三章的 F ( w ) F(\mathbf{w}) F(w)来代替预先建立的分类器。为此,确保变量train、test、train_data_features和test_data_features(来自于提取的特征)被加载到你的IPython shell。
a) 编写一个PYTHON函数logistic_gradient,期望将训练集矩阵X_train、地面真实标签向量 y train y_{\text {train}} ytrain和当前权重向量 w w w作为其输入,并返回logistic回归的负对数似然函数的梯度 g g g。关于数学定义,请参考讲义。
b) 编写一个PYTHON函数find_w,期望有一个训练集矩阵X_train,一个地面真实标签向量y_train,一个步长α和一个最大迭代数max_it,通过执行梯度下降确定最佳逻辑回归权重向量w_star,即在每个迭代中调用logistic_gradient。确保将仿射偏移量 w 0 = b w_{0}=b w0=b纳入你的模型。
c) 手头的数据集相当大。应用标准梯度下降可能会导致Python抛出一个MemoryError异常。为了避免这种情况,我们将采用随机梯度下降法的一种变体,这种变体在训练深度神经网络方面已经被证明是成功的。在minibatch学习中,算法的每一次迭代都被一个所谓的epoch所取代。在每个历时中,训练集被随机划分为大小相等的子集,即迷你批。对于每个minibatch,梯度被计算出来,并只应用于minibatch中的样本。当每个minibatch的梯度步骤被执行时,一个epoch就结束了。修改find_w,使其能够进行小批量学习。你需要用 n − n_{-} n−epochs替换max_it,并在函数定义中添加参数n_minibatch。注意:要注意梯度和损失函数的归一化。
d) 编写一个函数classify_log,有一个权重向量w和一个测试集矩阵X_test,通过逻辑回归对X_test中的样本进行分类,返回一个标签向量 y test. y_{\text {test. }} ytest. 在train_data_features和test_data_features上测试find_w和classify_log的实现,10个epochs,minibatches大小为100,步长为alpha=1。
e) Logistic回归很容易出现过拟合。为了防止这种情况,可以使用正则器。调整实现方式,使其不是最小化 F ( w ) F(\mathbf{w}) F(w),而是最小化项
F ( w ) + λ ∥ w ∥ 2 F(\mathbf{w})+\lambda\|\mathbf{w}\|^{2} F(w)+λ∥w∥2
其中 λ \lambda λ是一个非负的正则化参数。用 λ = 1 0 − 3 \lambda=10^{-3} λ=10−3测试实现方式。
3.4.1 使用python实现
相关python代码如下
import numpy as np
import pandas as pd
from bs4 import BeautifulSoup
import re
import nltk
import matplotlib.pyplot as plt
nltk.download('stopwords') # Download text data sets, including stop words
from nltk.corpus import stopwords # Import the stop word list
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import LogisticRegression as LR
from sklearn.metrics import roc_auc_score as AUC
# function for preprocessing the data
def review_prepro(data, remove_stopwords=False):
stops = stopwords.words('english')
# remove HTML tags
review_text = BeautifulSoup(data, 'lxml').get_text()
# remove non-letters and numbers
letters_only = re.sub('[^a-zA-Z]',
' ',
review_text)
# make all characters lower case and split the documents into single words
words = letters_only.lower().split()
if remove_stopwords:
# remove stop words
meaningful_words = [w for w in words if not w in stops]
# return concatenated single string
return ' '.join(meaningful_words)
else:
# or don't and concatenate to single string
return ' '.join(words)
def classify_log(w, X_test):
w0 = w[0]
y_test = sigmoid(w0 + np.dot(X_test.T, w[1:]))
return y_test
def train_data_prep(train, vectorizer):
"""
preprocess the training data using the bag of words in Sklearn
:param train:
:return: processed training data
"""
# load train data
num_reviews = train['review'].size
clean_train_reviews = []
for i in range(num_reviews):
if (i + 1) % 1000 == 0:
print('\r Review {} of {} - Training'.format(i + 1, num_reviews), end="")
clean_train_reviews.append(review_prepro(train['review'][i], remove_stopwords=True))
# fit the vectorizer to the data
train_data_features = vectorizer.fit_transform(clean_train_reviews)
# convert to numpy array
train_data_features = train_data_features.toarray()
return train_data_features
def test_data_prep(test, vectorizer):
"""
preprocess the testing data from the raw input
:param test:
:return: processed testing data
"""
num_test_reviews = test['review'].size
clean_test_reviews = []
for i in range(num_test_reviews):
if (i + 1) % 1000 == 0:
print('\r Review {} of {}'.format(i + 1, num_test_reviews), end='')
clean_test_reviews.append(review_prepro(test['review'][i], remove_stopwords=True))
test_data_features = (vectorizer.transform(clean_test_reviews)).toarray()
return test_data_features
def sigmoid(x):
# https://timvieira.github.io/blog/post/2014/02/11/exp-normalize-trick/
z = np.exp(-np.abs(x))
return np.where(x >= 0.0, 1.0 / (1.0 + z), z / (1.0 + z))
def logistic_gradient(x_train, y_train, w, reg=0.0):
g = -np.dot(x_train * y_train, sigmoid(-np.dot(w, x_train) * y_train)) / x_train.shape[1] + reg * np.sum(w ** 2)
return g
def find_w(x_train, y_train, alpha, n_epochs, n_minibatch, reg=0.0):
"""
Using this function to find the best w.
:param x_train: the training data, which has the shapes [samples, features]
:param y_train: the training label, which has the shapes [outputs,]
:param alpha: step constant
:param n_epochs: training epochs
:param n_minibatch: we divided the training data into some small training set to accelerate the training speed.
:param reg: the factor of the regularizer
:return: the best weight w_star
"""
x_train = x_train.T
x_pre = np.ones((x_train.shape[0] + 1, x_train.shape[1]))
x_pre[1:, :] = x_train
w = np.ones((x_pre.shape[0],))
print('x_pre shape ={}, w shape = {}'.format(x_pre.shape, w.shape))
loss_ = []
for k in range(n_epochs):
loss = np.sum(-np.log(sigmoid(y_train * np.dot(w, x_pre)))) / x_pre.shape[1] + reg * np.sum(w ** 2)
loss_.append(loss)
rp = np.random.permutation(x_pre.shape[1])
print('In {} iteration, the loss = {}'.format(k, loss))
for it in range(x_pre.shape[1] // n_minibatch):
delta_w = logistic_gradient(x_pre[:, rp[it * n_minibatch: (it + 1) * n_minibatch]],
y_train[rp[it * n_minibatch:(it + 1) * n_minibatch]], w)
w = w - alpha * delta_w
return w,loss_
if __name__ == "__main__":
# load the data
train = pd.read_csv('labeledTrainData.tsv', header=0, delimiter='\t', quoting=3)
test = pd.read_csv('labeledTestData.tsv', header=0, delimiter="\t", quoting=3)
# download the stopwords
stops = set(stopwords.words('english'))
vectorizer = CountVectorizer(analyzer='word',
tokenizer=None,
preprocessor=None,
stop_words=stops,
max_features=5000)
# process the data
train_data_features = train_data_prep(train, vectorizer)
test_data_features = test_data_prep(test, vectorizer)
y_train = (np.array(train['sentiment'].values) - 0.5) * 2
# (1) Testing implementation without regularizers
W, W_loss = find_w(train_data_features, y_train, 0.8, 20, 100)
y_pred = classify_log(W, test_data_features.T)
y_test = test['sentiment'].values
auc = AUC(y_test, y_pred)
print('AUC score after 20 epochs:', auc)
# (2) Testing implementation with regularizers to overdue mitigate the overfitting
w, w_loss = find_w(train_data_features, y_train, 1, 20, 100, 1e-3)
y_pred = classify_log(w, test_data_features.T)
auc = AUC(y_test, y_pred)
print('AUC score after 20 epochs:', auc)
# plot
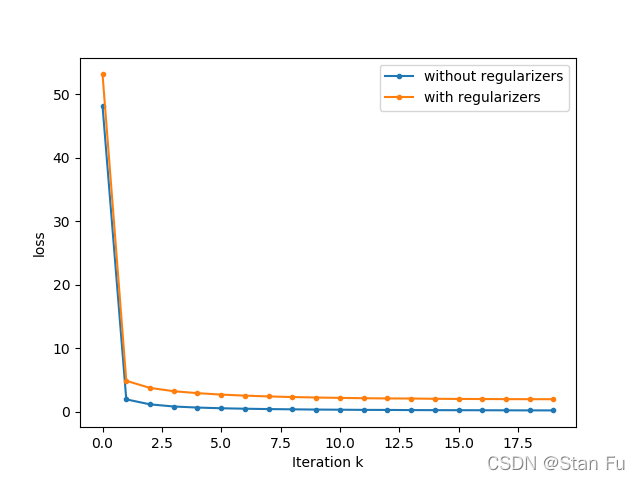
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.set_xlabel('Iteration k')
ax.set_ylabel('loss')
ax.plot(W_loss, marker='.', label='without regularizers')
ax.plot(w_loss, marker='.', label='with regularizers')
ax.legend()
plt.show()
输出为,
x_pre shape =(5001, 20000), w shape = (5001,)
In 0 iteration, the loss = 48.15060140614601
In 1 iteration, the loss = 1.9271375244901945
In 2 iteration, the loss = 1.1439895026827396
In 3 iteration, the loss = 0.8040511998178164
In 4 iteration, the loss = 0.637276530141581
In 5 iteration, the loss = 0.5275615696559821
In 6 iteration, the loss = 0.4531238182560532
In 7 iteration, the loss = 0.39835683526227206
In 8 iteration, the loss = 0.3585725270966355
In 9 iteration, the loss = 0.3208458216978429
In 10 iteration, the loss = 0.2989468342660105
In 11 iteration, the loss = 0.27127014988315357
In 12 iteration, the loss = 0.26380395477375235
In 13 iteration, the loss = 0.23870379629686295
In 14 iteration, the loss = 0.22874535039441457
In 15 iteration, the loss = 0.22097269464251518
In 16 iteration, the loss = 0.21411424494393824
In 17 iteration, the loss = 0.20234804193010983
In 18 iteration, the loss = 0.19146457065053046
In 19 iteration, the loss = 0.18977771952092898
AUC score after 20 epochs: 0.9201902430149848
x_pre shape =(5001, 20000), w shape = (5001,)
In 0 iteration, the loss = 53.15160140614601
In 1 iteration, the loss = 4.850572401123086
In 2 iteration, the loss = 3.7359586329298007
In 3 iteration, the loss = 3.2139682944306305
In 4 iteration, the loss = 2.907177612020046
In 5 iteration, the loss = 2.681058512521938
In 6 iteration, the loss = 2.5166307885635284
In 7 iteration, the loss = 2.392833861337298
In 8 iteration, the loss = 2.294087922661967
In 9 iteration, the loss = 2.2217974363161987
In 10 iteration, the loss = 2.161302804041983
In 11 iteration, the loss = 2.113409966477404
In 12 iteration, the loss = 2.0736801266948683
In 13 iteration, the loss = 2.061541837823529
In 14 iteration, the loss = 2.016740023535874
In 15 iteration, the loss = 1.9973296285347977
In 16 iteration, the loss = 1.9823663669782907
In 17 iteration, the loss = 1.967645885882539
In 18 iteration, the loss = 1.9572636195387196
In 19 iteration, the loss = 1.9538835403945283
AUC score after 20 epochs: 0.921975893241498