(一)逻辑回归
逻辑回归算法是一种广义的线性回归分析模型, 可用于二分类和多分类问题, 常用于数据挖掘、疾病自动诊断、经济预测等领域。通俗来说, 逻辑回归算法通过将数据进行拟合成一个逻辑函数来预估一个事件出现的概率,因此被称为逻辑回归。因为算法输出的为事件发生概率, 所以其输出值应该在0至1之间。
逻辑回归的优点:是速度快,特别是对于二分类;可以适用于连续性和类别性自变量;输出的是几率,更容易解释和使用。不足:容易发生过拟合问题,最终导致算法无法对未知数据进行很好的预测。
具体过程:
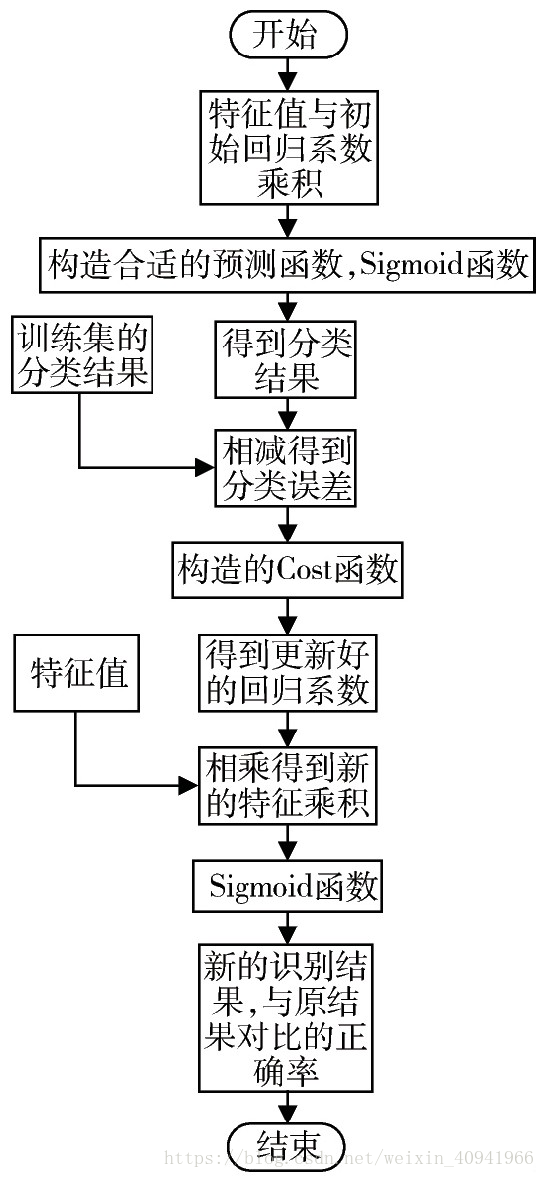
(二)Python实现
1 导入数据
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
np.random.seed(12)
num_observations = 5000
x1 = np.random.multivariate_normal([0, 0], [[1, .75],[.75, 1]], num_observations)
x2 = np.random.multivariate_normal([1, 4], [[1, .75],[.75, 1]], num_observations)
simulated_separableish_features = np.vstack((x1, x2)).astype(np.float32)
simulated_labels = np.hstack((np.zeros(num_observations),
np.ones(num_observations)))2 定义Sigmoid函数
def sigmoid(scores):
return 1 / (1 + np.exp(-scores))3 定义最大似然估计函数
def log_likelihood(features, target, weights):
scores = np.dot(features, weights)
ll = np.sum( target*scores - np.log(1 + np.exp(scores)) )
return ll4 构建逻辑回归函数
def logistic_regression(features, target, num_steps, learning_rate, add_intercept = False):
if add_intercept:
intercept = np.ones((features.shape[0], 1))
features = np.hstack((intercept, features))
weights = np.zeros(features.shape[1])
for step in xrange(num_steps):
scores = np.dot(features, weights)
predictions = sigmoid(scores)
# Update weights with gradient
output_error_signal = target - predictions
gradient = np.dot(features.T, output_error_signal)
weights += learning_rate * gradient
# Print log-likelihood every so often
if step % 10000 == 0:
print log_likelihood(features, target, weights)
return weights5 与sklearn的Logistic回归进行比较、评估模型
clf = LogisticRegression(fit_intercept=True, C = 1e15)
clf.fit(simulated_separableish_features, simulated_labels)
weights = logistic_regression(simulated_separableish_features, simulated_labels,
num_steps = 300000, learning_rate = 5e-5, add_intercept=True)
data_with_intercept = np.hstack((np.ones((simulated_separableish_features.shape[0], 1)),
simulated_separableish_features))
final_scores = np.dot(data_with_intercept, weights)
preds = np.round(sigmoid(final_scores))
print ('Accuracy from scratch: {0}'.format((preds == simulated_labels).sum().astype(float) / len(preds)))
print ('Accuracy from sk-learn: {0}'.format(clf.score(simulated_separableish_features, simulated_labels)))
plt.figure(figsize = (12, 8))
plt.scatter(simulated_separableish_features[:, 0], simulated_separableish_features[:, 1],
c = preds == simulated_labels - 1, alpha = .8, s = 50)需要在程序开始引入sklearn中的回归模块
from sklearn.linear_model import LogisticRegression逻辑回归算法推导详见:http://ufldl.stanford.edu/tutorial/supervised/LogisticRegression/
本项目参见:https://beckernick.github.io/logistic-regression-from-scratch/