写在前面
生活中,常常存在一些分类问题,比如:
- 垃圾邮件分类
- 网上交易是否为敲诈
- 西瓜是好是坏(西瓜书中的例子)等
上述的问题都可以抽象为输出为变量y的问题,前段时间,我通过博客给大家分享了如何使用线性模型进行回归学习,但是若要做的任务是分类问题呢?这里可以考虑广义线性模型:只要找到一个单调可微函数将分类任务的真实标记y与线性回归模型的预测值联系起来。
考虑二分类任务,其输出标记
,而线性回归模型参数的预测值z是实值,于是,我们需要将实值z转换为0/1值。当然最理想的是单位阶跃函数,但是单位阶跃函数不连续,因此不能作为广义线性回归模型。于是我们希望能够找到一个程度上类似单位阶跃函数的“替代函数”,并希望它单调可微。
模型
sigmoid 函数
sigmoid函数真是这样一个常用的替代函数。表达式如下:
即:
函数如下图:
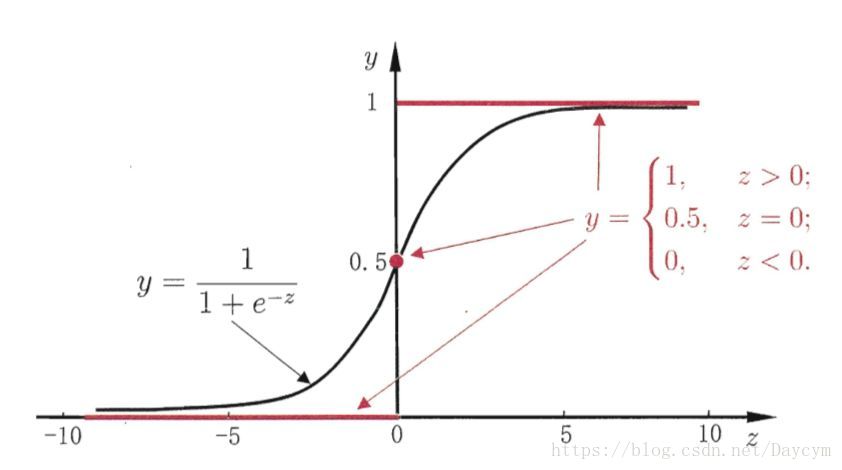
从上图可以看到sigmoid函数是一个s形的曲线,它的取值在[0, 1]之间,在远离0的地方函数值回很快接近0/1。
这个性质使我们能够以概率的方式来解释:
z是一个矩阵,θ是参数列向量(要求解的),x是样本列向量(给定的数据集)。θ^T表示θ的转置。g(z)函数实现了任意实数到[0,1]的映射,这样我们的数据集([x0,x1,…,xn]),不管是大于1或者小于0,都可以映射到[0,1]区间进行分类。hθ(x)给出了输出为1的概率。比如当hθ(x)=0.7,那么说明有70%的概率输出为1。输出为0的概率是输出为1的补集,也就是30%。
如果我们有合适的参数列向量θ([θ0,θ1,…θn]^T),以及样本列向量x([x0,x1,…,xn]),那么我们对样本x分类就可以通过上述公式计算出一个概率,如果这个概率大于0.5,我们就可以说样本是正样本,否则样本是负样本。
那么如何得到合适的参数向量
根据sigmoid函数的特性,假设:
上式即为在已知样本x和参数 的情况下,样本x属性正样本(y = 1)和负样本(y = 0)的条件概率。理想状态下,根据上述公式,求出各个点的概率均为1,也就是完全分类都是正例。但是考虑到实际情况,样本点的概率越接近于1,其分类效果越好。比如一个样本属于正样本的概率为0.51,那么我们就可以说明这个样本属于正样本。另一个样本属于正样本的概率为0.99,那么我们也可以说明这个样本属于正样本。但是显然,第二个样本概率更高,更具说服力。我们可以把上述两个概率公式合二为一:
合并后的我们称之为代价函数(Cost Function)。
这个代价函数,是对于一个样本而言的。给定一个样本,我们就可以通过这个代价函数求出,样本所属类别的概率,而这个概率越大越好,所以也就是求解这个代价函数的最大值。既然概率出来了,那么最大似然估计也该出场了。假定样本与样本之间相互独立,那么整个样本集生成的概率即为所有样本生成概率的乘积,再将公式对数化,过程如下:
似然函数:
对数似然函数:
其中,m为样本的总数,y(i)表示第i个样本的类别,x(i)表示第i个样本,需要注意的是θ是多维向量,x(i)也是多维向量。
综上所述,满足上式值最大的
值就是我们需要求解的模型。
怎么求解使J(θ)最大的θ值呢?因为是求最大值,所以我们需要使用梯度上升算法。另外一种方法就是牛顿法 。
这篇博客中有讲解