


summarization 任务分两种:
- 一种是提取比较有代表性的句子
- 第二种是用更加抽象的语言总结段落内容
summarization 的目标:


Extractive summarisation
“Extractive Summarization” 是一种自动文本摘要的方法,它的目标是从原始文档中选择一些关键的句子或者段落,组成一个摘要。这个摘要应该尽可能地保留原始文档的主要信息和意思。当我们讨论 “Single-document Extractive Summarization” 时,我们是指从单一文档中提取关键信息生成摘要的过程。
Single-document
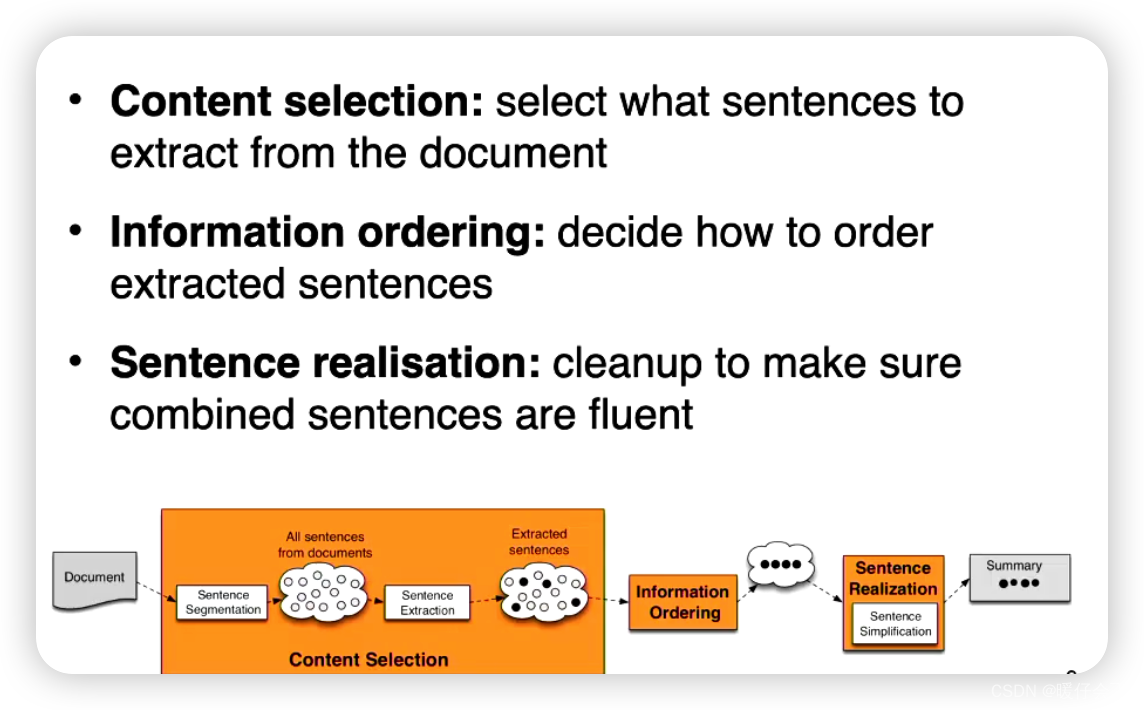
以下是进行单文档抽取式摘要(Single-document Extractive Summarization)的一般步骤:
-
预处理:这通常包括清洗文本(去除不必要的符号、空格等)、分词、删除停用词(例如“the”,“is”等常见但不含有太多信息的词)等。
-
特征计算:根据特定的特征对文档中的每个句子进行评分。这些特征可能包括句子的长度、句子中的关键词频率、句子在文档中的位置(例如,通常来说,摘要可能会更倾向于选择文章的开头和结尾的句子,因为这些位置的句子更可能包含主要信息)、句子与整个文档的相似性等。
-
句子选择:基于前面步骤的评分,选择得分最高的句子包含在摘要中。通常,我们会设置一个阈值或者限制摘要的长度。
-
摘要生成:将选出的句子按照它们在原始文档中出现的顺序组织起来,形成最终的摘要。
值得注意的是,这种方法虽然简单有效,但也存在一些局限性。例如,它可能会忽视句子之间的逻辑关系和连贯性,因为它只是简单地从原始文档中抽取句子,而没有进行任何的重新组织或者生成新的句子。此外,由于它依赖于原始文档中的句子,所以如果原始文档的质量不高,摘要的质量也可能受到影响。
content selection
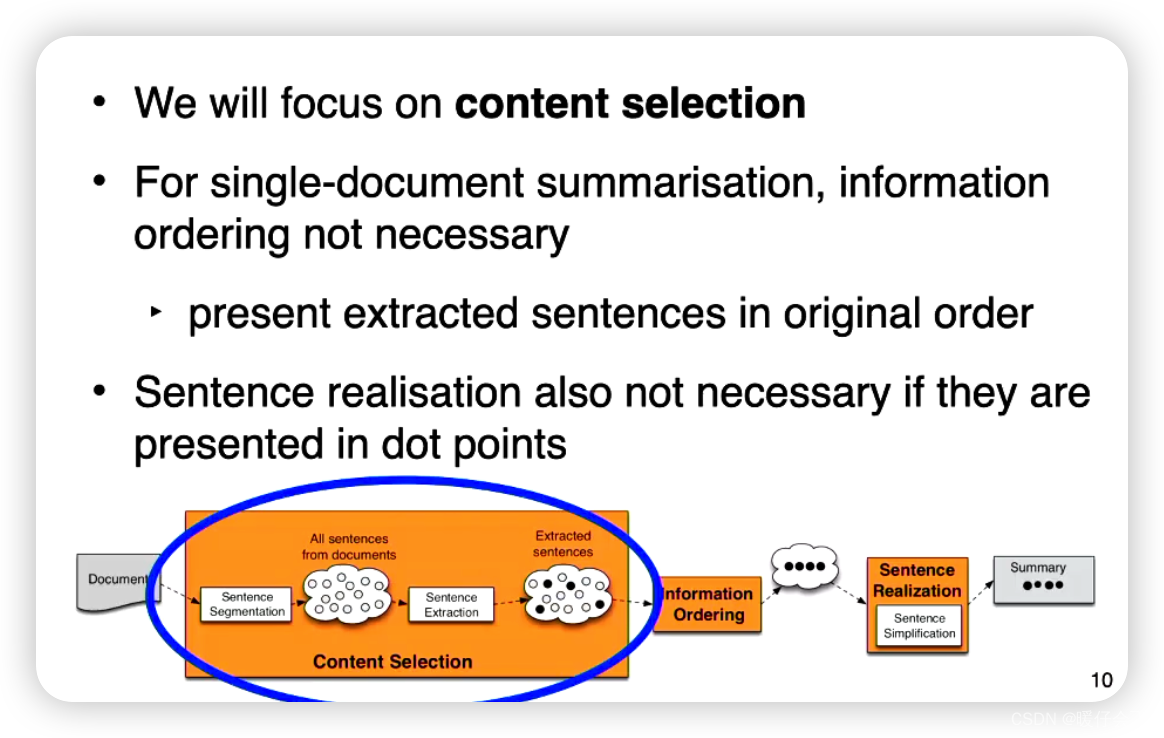

- 通常使用
unsupervised learning的方法 - 目标是:找出重要或突出的句子
TFIDF Method

Log Likelihood Ratio Method对数似然比

这种方法试图通过统计分析来确定哪些句子或短语最有可能包含原始文档的关键内容。
对数似然比是一种衡量两种概率模型之间相对优劣的方法,更具体地说,它比较了一个更复杂的模型(通常包含更多参数)与一个更简单的模型(通常包含更少参数)对于观察到的数据的拟合程度。 在这个情况下,对数似然比可以被用于衡量一个句子或者短语是否包含了与整个文档相关的关键信息。
这种方法的基本思想是,对于一个给定的句子或者短语,如果它在原始文档中的出现频率远高于在一个更大的背景语料库中的出现频率,那么这个句子或者短语就更有可能包含了原始文档的关键信息。 因此,我们可以通过计算对数似然比来评价每个句子或者短语的重要性,然后选择得分最高的句子或者短语作为摘要的一部分。
这种方法的优点是,它可以自动地挑选出那些包含关键信息的句子或者短语,而不需要人工设定一组关键词。然而,它也有一些局限性,比如,它可能会过于依赖于频率信息,而忽视了句子或者短语的语义信息和上下文信息。此外,对于一些较短或者非常特殊的文档,这种方法可能无法提供很好的结果。

Sentence Centrality Method 句子中心法

句子的中心性(Sentence Centrality)是指一种评估句子在文档中重要性的度量方法。 对句子中心性的评估常用于自动文本摘要生成、信息抽取等任务。
RST Parsing

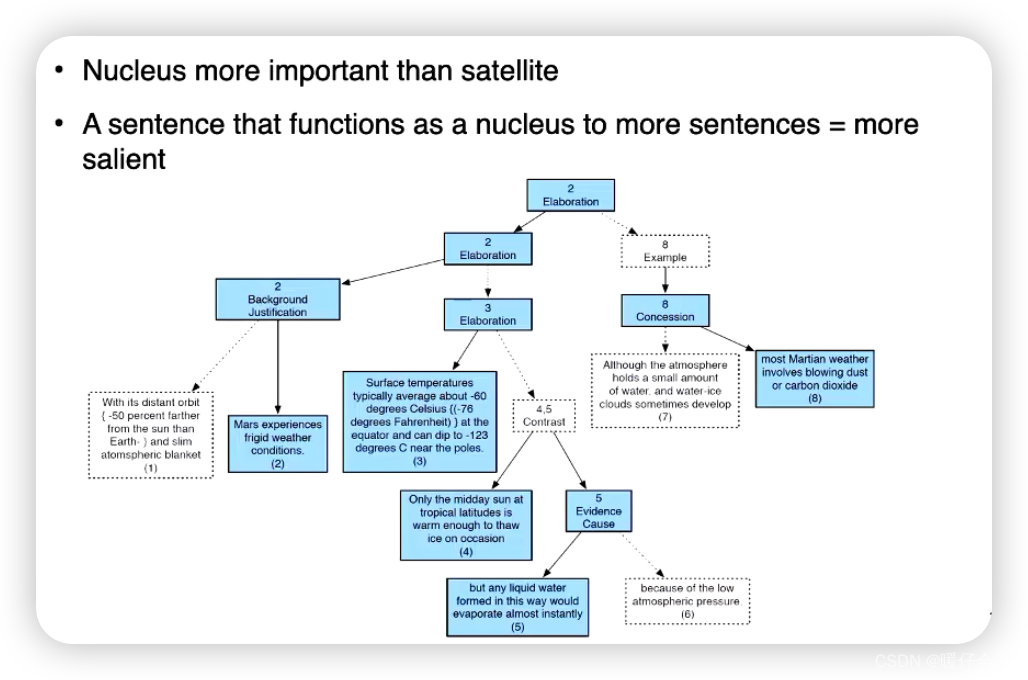
Rhetorical Structure Theory(RST,修辞结构理论)是一种描述文本结构的理论框架。在这个框架中,文本不仅仅是一系列的句子,而是由一系列的修辞关系(Rhetorical Relations)连接起来的。这些修辞关系包括因果关系、对比关系、解释关系等等,它们描述了文本中的句子或者句子组是如何相互关联,以形成一个统一、连贯的信息结构的。
RST解析(RST Parsing)是指对一个文本进行RST分析,以识别出文本中的修辞关系并生成一种称为RST树(RST Tree)的结构表示。
在文本摘要(Summarization)中,RST解析可以帮助我们理解文本的深层结构和逻辑关系,从而生成更高质量的摘要。例如,我们可以优先选择那些在RST树中位于更高层次(也就是更重要位置)的句子,或者那些参与了重要修辞关系的句子。 此外,我们还可以根据RST树来保证摘要的连贯性和逻辑性,例如,如果我们选择了一个结果(Result)句子,那么我们可能也需要选择与之相关的原因(Reason)句子。

Multi-document
- 多文件的情况和单文件的很相似,只是可能有信息冗余,因为可能有多个句子是重复的或者非常相似的
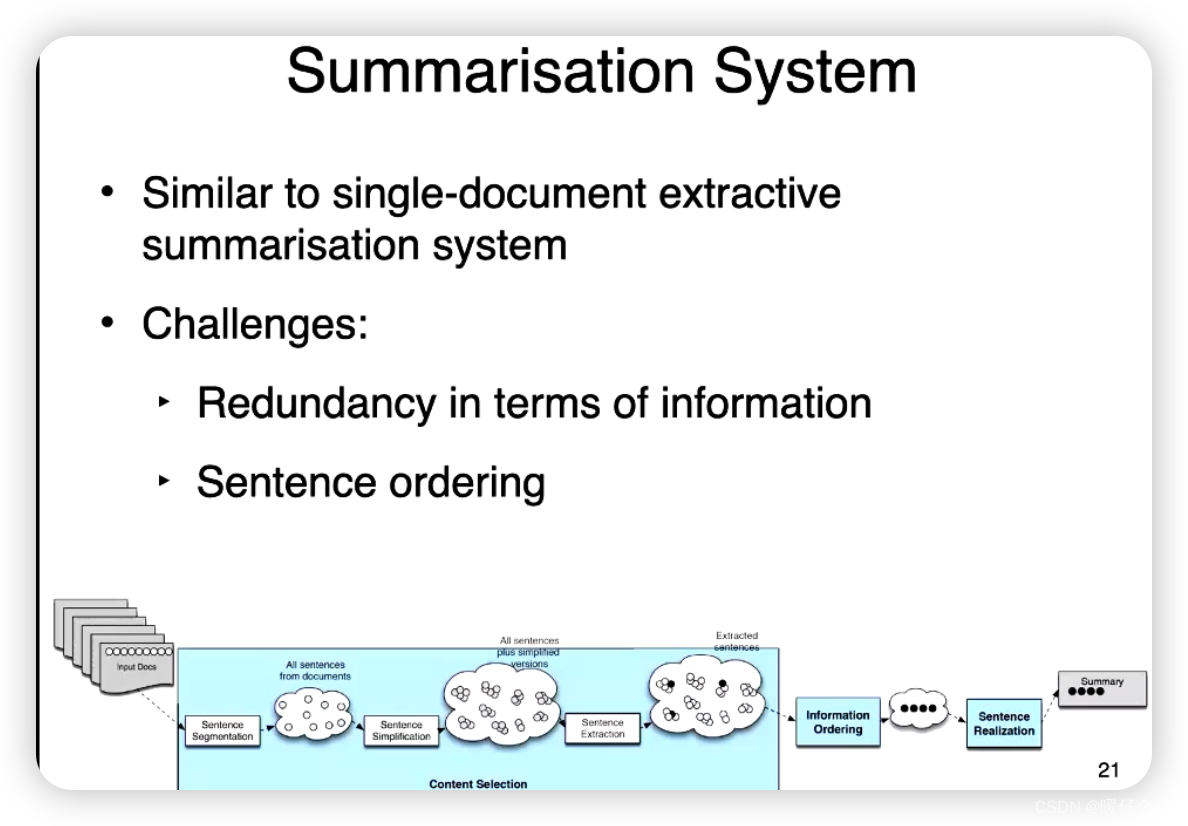
Content selection
- 还是可以采用 tfidf 以及对数似然比
- 但是要选择忽略那些冗余的句子
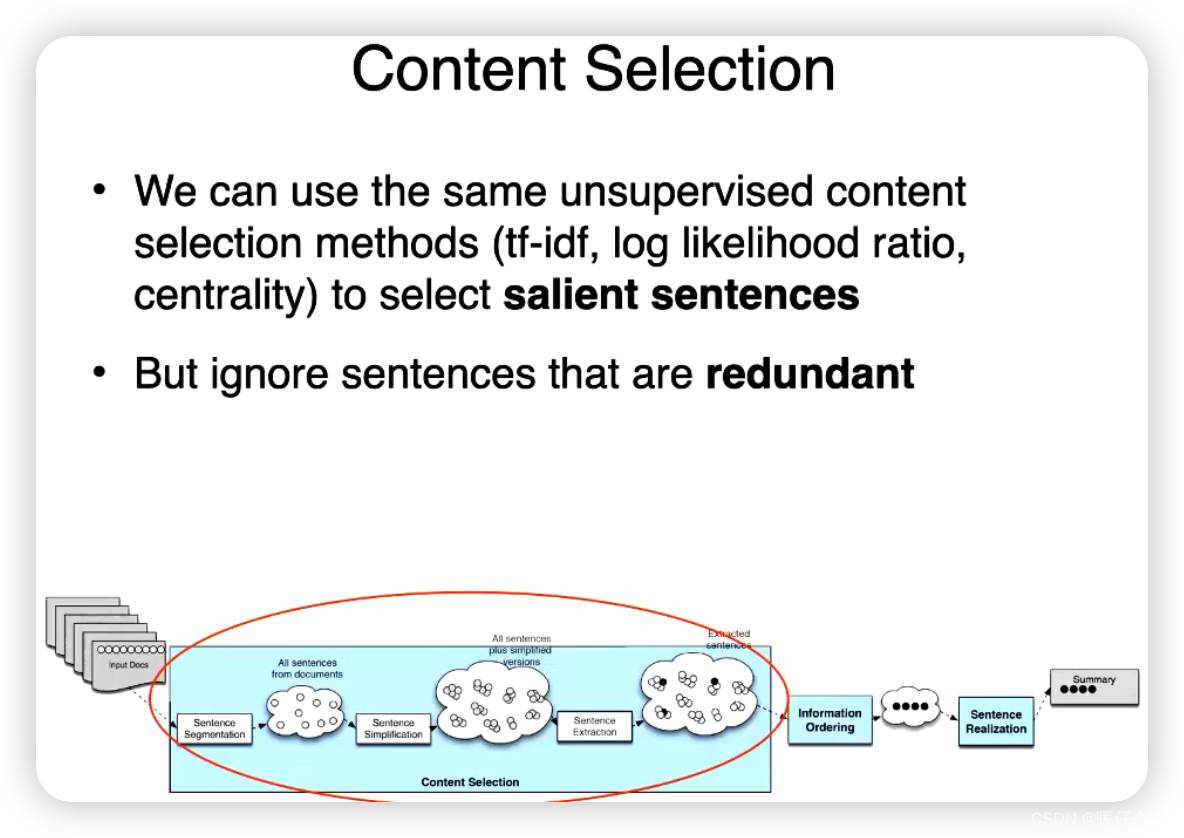
Maximum Marginal Relevance 最大边际相关性

最大边际相关性(Maximum Marginal Relevance, MMR)是一种在信息检索和文本摘要等任务中使用的策略,用于权衡信息的相关性和多样性。其基本思想是选择那些与查询或者主题最相关,但与已选择内容最不相似的项。
在文本摘要的场景中,MMR可以帮助我们生成更好的摘要。比如在抽取式摘要中,我们可以使用MMR来选择句子,以确保选出的句子既与文档主题相关,又尽可能地包含不同的信息。这样可以避免摘要中包含重复或者冗余的内容,从而提高摘要的信息密度和阅读体验。
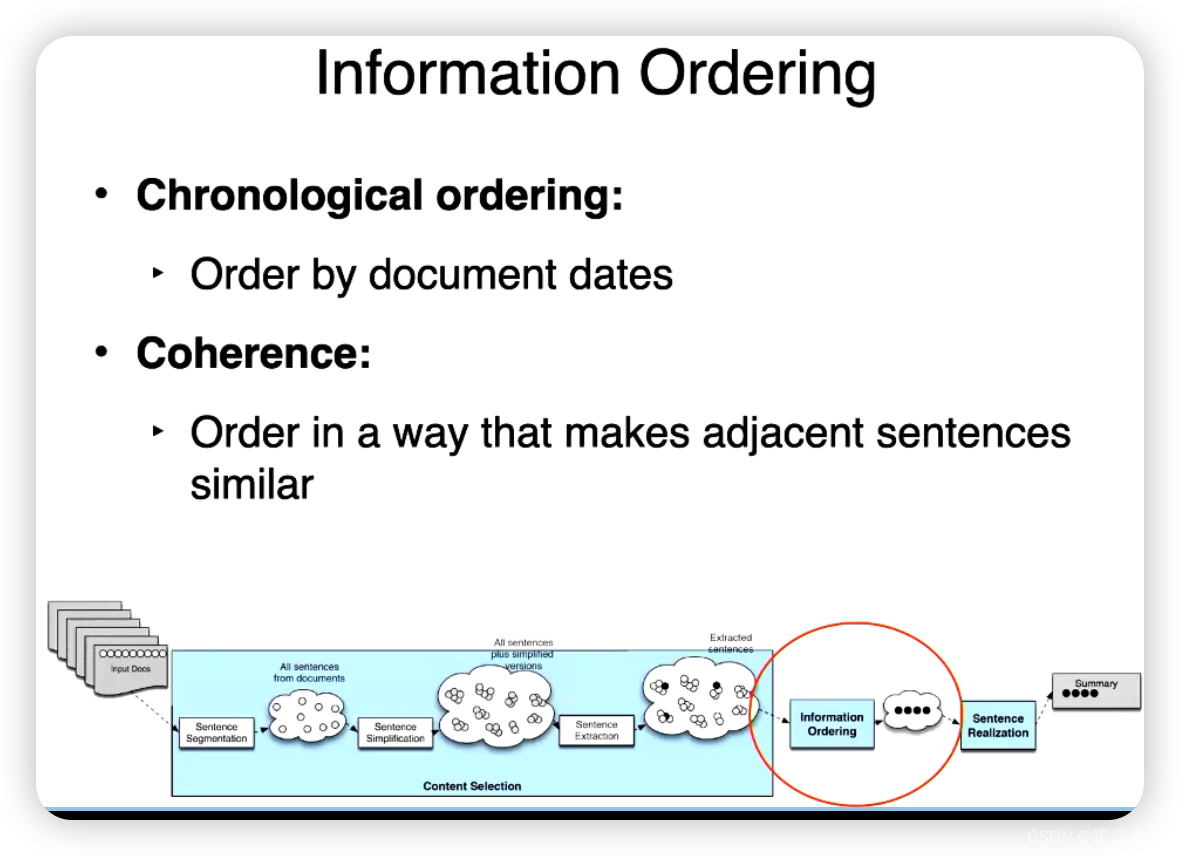
Information Ordering 信息有序化
- 按照时间排序
- 按照内聚性排序
Sentence Realization
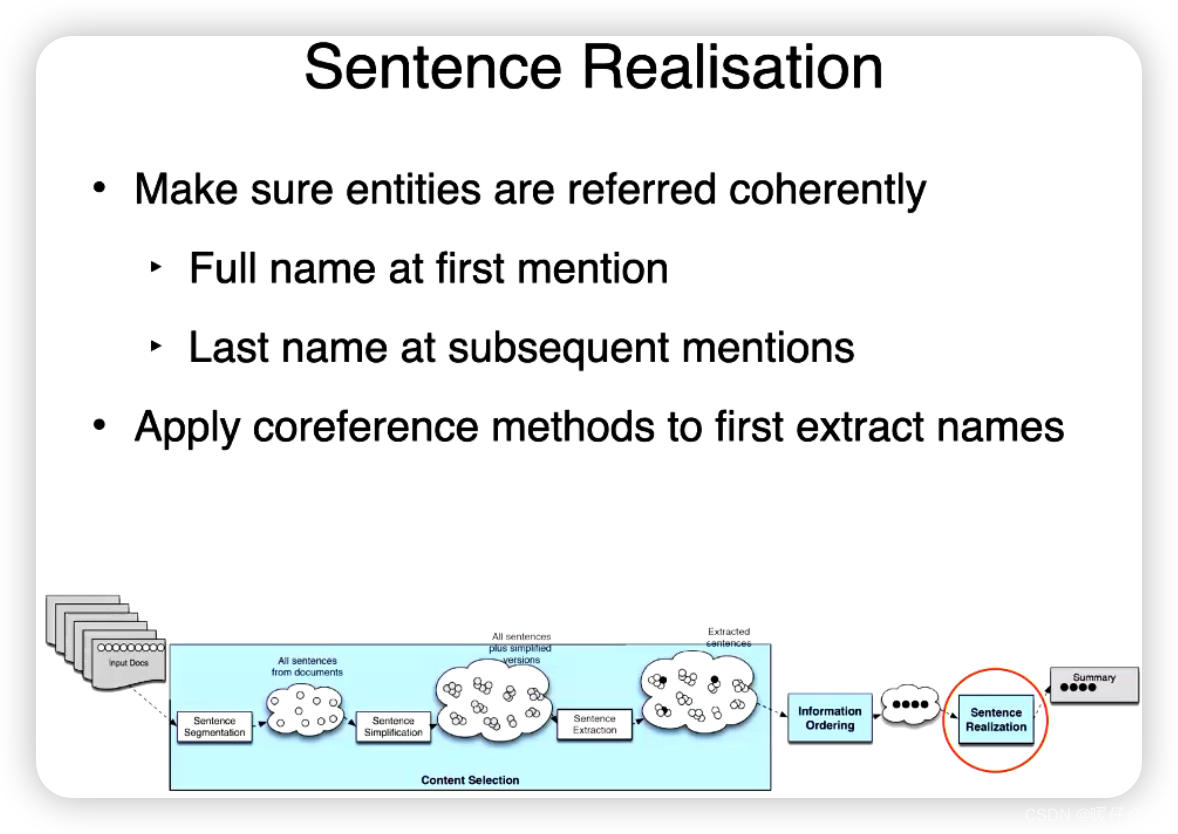
“句子实现”(Sentence Realisation)通常指的是在自然语言生成(NLG)中将一个语义表示或语义框架转化为一个完整的、语法正确的句子的过程。
这通常涉及到以下几个步骤:
- 词汇选择:根据语义表示选择合适的词语来表达意思。例如,如果语义表示是“移动”,可以选择"移动",“走”,"跑"等词汇。
- 语序决定:不同的语言有不同的语序规则,需要根据语法规则决定词语的排列顺序。
- 形态生成:在某些语言中,词形会根据其在句子中的角色而改变,例如在英语中,动词的时态可能需要根据语境变化。
- 修饰词添加:可能需要添加一些额外的词语,如冠词、介词、连词等,以生成语法正确的句子。
Abstractive summarisation
Single-document (deep learning models!)

Encoder-Decoder 模型
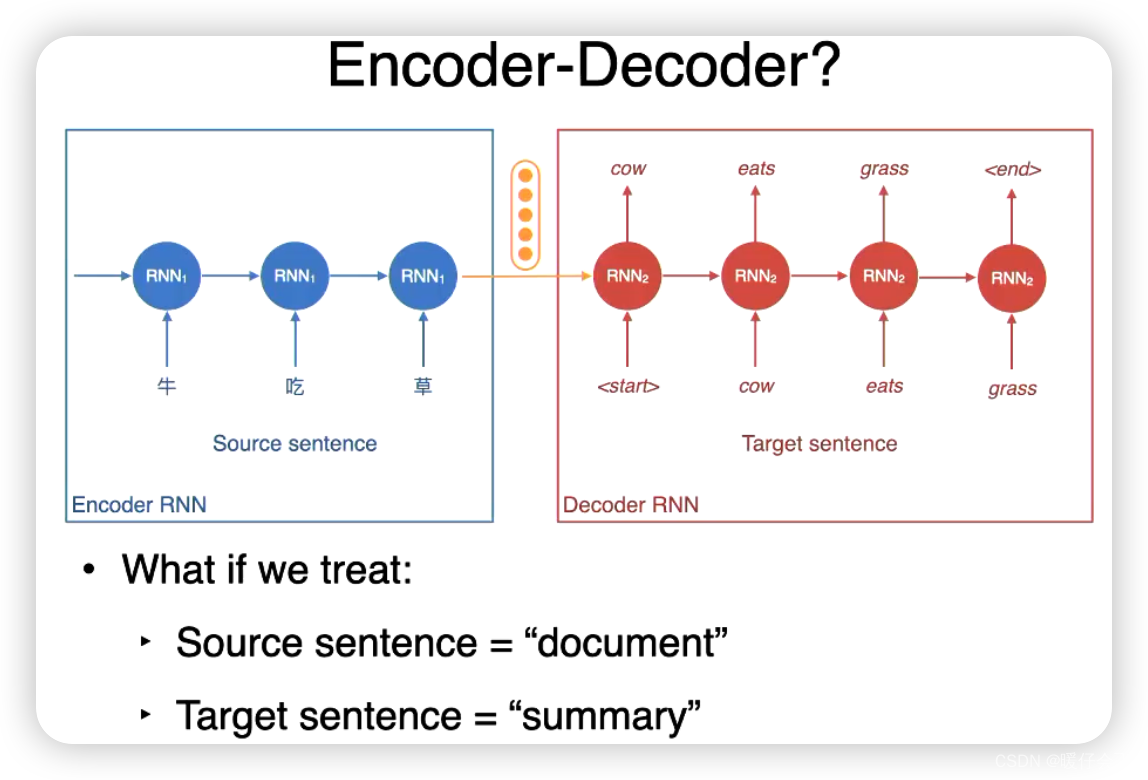
-
为了训练这些模型,我们使用的数据的类型也不同,其中一种就是: 将文章的第一句话作为 document,summary 就是文章的题目


-
按照这种方式产生的结果实例如上:
- G 是
groundtruth - A 是生成的
summary
- G 是
-
还有其他数据集形式:

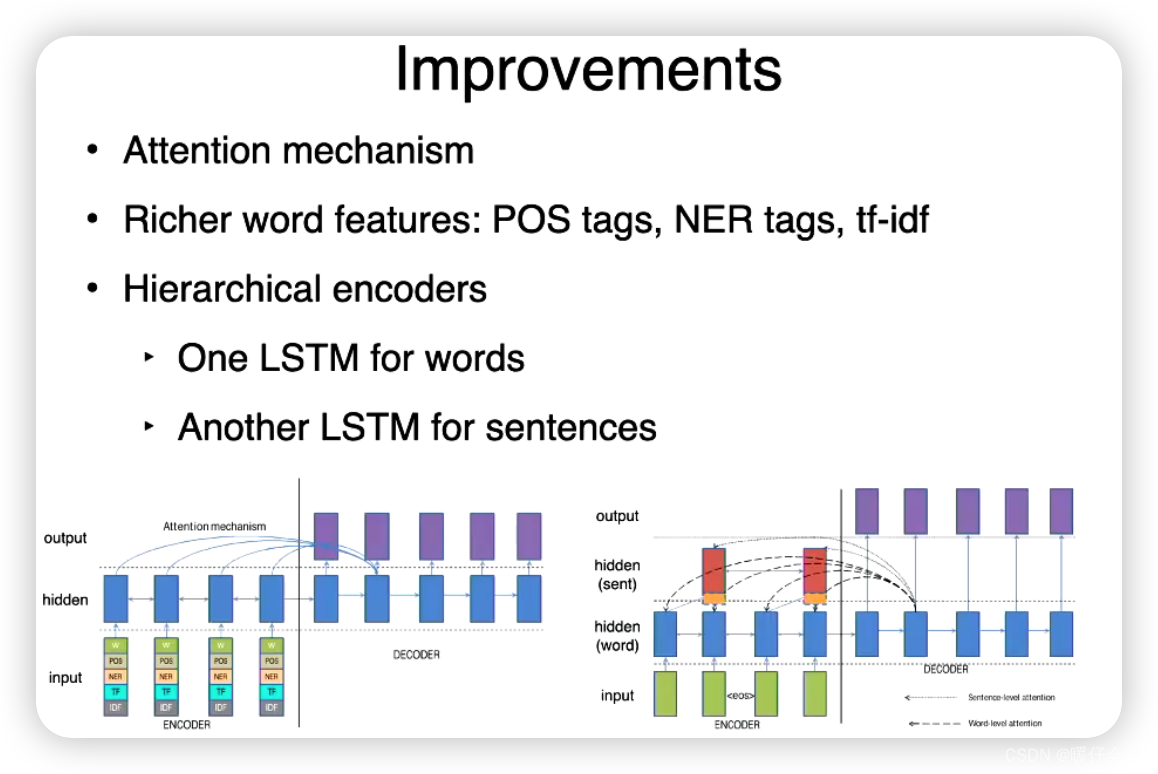
Improvements
Encoder-Decoder with Attention
其工作原理的简单解释为:
-
编码器:编码器的任务是将输入的源文本(例如,一篇文章)转换成一系列的向量表示,这些向量捕获了文本的语义信息。常见的编码器是循环神经网络(RNN)或者Transformer编码器。
-
注意力机制:注意力机制在编码和解码过程中起着重要的作用。它的基本思想是在生成每一个输出单词时,不仅考虑解码器的当前状态,也考虑源文本中的所有词语,而且对于不同的词语赋予不同的权重。这些权重被称为“注意力”,它们表示解码器在生成当前词语时对源文本中的每个词语的关注程度。通过注意力机制,解码器可以更好地利用源文本的信息,从而生成更准确的摘要。
-
解码器:解码器的任务是根据编码器的输出和注意力权重,生成目标文本(例如,一个摘要)。在生成每一个词语时,解码器都会参考之前生成的所有词语和注意力权重。常见的解码器是循环神经网络(RNN)或者Transformer解码器。
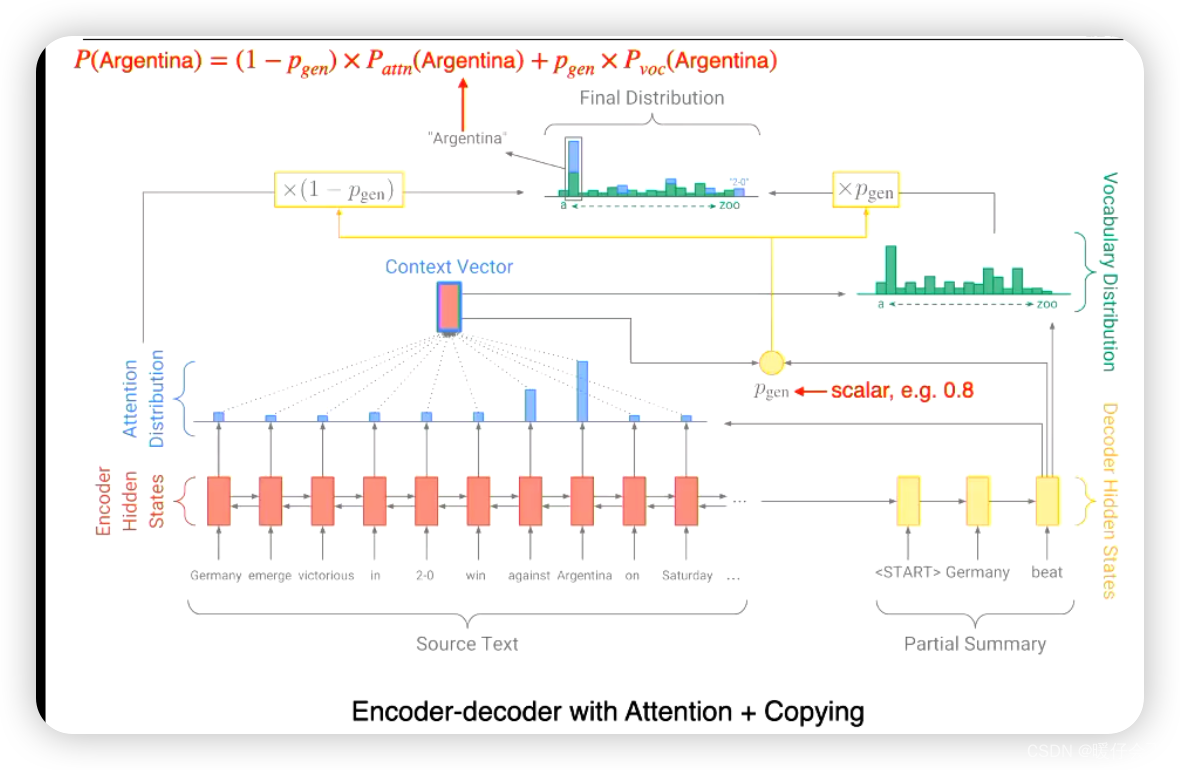
基于 Copy 机制的方法
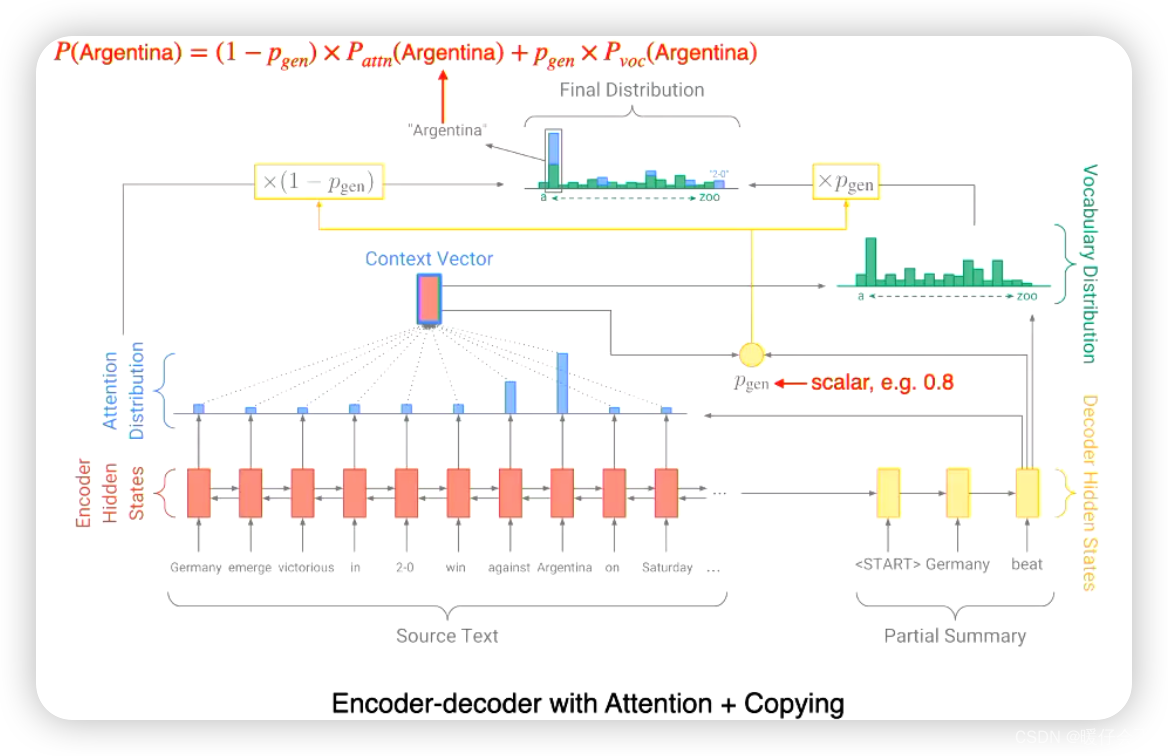
如上图,具体来说:
- 上述方法结合了
copy机制,这样避免解码端直接解码,而是在解码的每一个时间步都考虑编码端的信息 - 上图中使用了
Bi-lstm作为encoder,decoder端就是使用普通的lstm。 - 假设目前的
decoder时间步为 t i t_i ti 用decoder的hidden向量与encoder端的每一个时间步的hidden向量计算相似度,通过softmax之后得到attention distribution,根据这个distribution对每个encoder向量加权求和之后得到当前时间步 t i t_i ti 的context vector - 然后解码端的
vector与context vector计算相似度,并得到 P g e n P_{gen} Pgen 这个标量。 - 然后按照比例将原本的
attention distribution与 t i t_i ti 时间步decoder的hidden状态相加,得到最终用于解码的Final Distribution,并从中选出最argmax作为当前时间步的生成单词 - 原本的
attention distribution就是copy的部分,代表直接利用原文的信息

Transformer-based

- 由于
BERT只是 transformer 的编码端,因此无法进行这类任务 - 这类任务需要
encoder+decoder或者只有decoder