文章地址:https://arxiv.org/pdf/1805.03989.pdf
代码地址:https://github.com/lancopku/Global-Encoding
文章标题:Global Encoding for Abstractive Summarization(用于抽象摘要的全局编码)ACL2018
写在前面:本文虽然不是多标签分类的文章,但是其基于Seq2Seq模型提出的Global Encoding可以供多标签学习思考借鉴,对于模型的改进提供新的思路。
Abstract
在神经系统的抽象概括中,传统的序列-序列(seq2seq)模型往往存在重复和语义无关的问题。为了解决这个问题,我们提出了一个全局编码框架,它根据源上下文的全局信息来控制从编码器到解码器的信息流。它由一个卷积门控单元组成,用于执行全局编码以改进源端信息的表示。对LCSTS和English Gigaword的评估都表明,我们的模型优于基准模型,分析表明,我们的模型能够生成更高质量的摘要并减少重复。
一、Introduction
生成式文本摘要可以看作是一个将源文本映射到目标摘要的序列映射任务。因此,序列-序列学习可以应用于神经抽象概括(Kalchbrenner and Blunsom, 2013;Sutskever et al., 2014; Cho et al., 2014),其模型由编码器和解码器组成。注意机制在seq2seq模型中得到了广泛的应用,在seq2seq模型中,解码器根据源侧信息的注意分数从编码器中提取信息(Bahdanau et al., 2014;Luong et al., 2015)。许多基于注意力的seq2seq模型被提出用于抽象摘要(Rush et al.,2015; Chopra et al., 2016; Nallapati et al., 2016),它们都优于传统的统计方法。

表一:在Gigaword数据集上基于注意力的常规seq2seq模型的总结示例。突出显示的文本表示重复,“#”表示掩码。
然而,近年来的研究表明,注意机制存在突出问题。Zhou等(2017)指出,源文本与目标摘要之间没有明显的对齐关系,编码器输出含有噪声,值得注意。例如,在表1中的seq2seq生成的摘要中,“official”后面跟了相同的单词,因为注意机制仍然注意注意分数高的单词。基于注意的seq2seq抽象摘要模型会出现重复和语义不相关的问题,导致语法错误和对原文主旨反映不足。
为了解决这一问题,我们提出了一种全局编码的抽象摘要模型。我们设置了一个卷积门控单元来在源上下文中执行全局编码。基于卷积神经网络(CNN)的gate由于参数共享的原因,对每个编码器的输出进行了过滤,使得每个时间步的表示都能根据全局上下文进行细化。我们在LCSTS和Gigaword这两个句子总结的基准数据集上进行了实验,结果表明,我们的模型分别以ROUGE-2 F1得分26.8分和17.8分超越了现有的方法。此外,分析表明,与seq2seq模型相比,我们的模型能够减少重复。
二、Global Encoding
我们的模型是建立在seq2seq模型的基础上的。对于编码器,我们为全局编码设置了一个卷积门控单元。全局编码以RNN编码器的输出为基础,用CNN改进源上下文的表示,以改进单词表示与全局上下文的连接。下面将详细介绍这些技术。
2.1 Attention-based seq2seq
RNN编码器依次从源文本接收每个单词的嵌入字。带有整个源文本信息的最终隐藏状态成为解码器的初始隐藏状态。这里我们的编码器是一个双向LSTM编码器,其中编码器在每个时间步长从两个方向输出连接。
我们实现了一个单向LSTM解码器,读取输入的单词并逐词生成摘要,将一个固定的目标词汇表嵌入到高维空间Y∈R|Y|×dim中。在每个时间步,解码器通过对目标词汇表Pvocab的分布进行采样,直到出现表示句子结束的令牌,生成摘要词yt。在编码过程的每个时间步i上,解码器的隐藏状态st和编码器的输出hi和矩阵权重Wa一起被用来计算得到全局注意力at,i和上下文向量ct,如下所示:
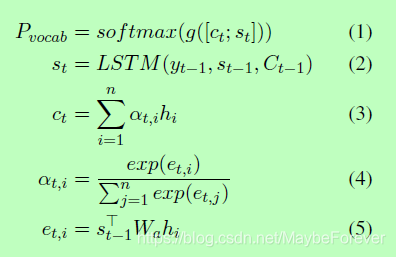
其中C为LSTM中的记忆状态(注:state分为c和h,c为cell state,即memory的state,h为hidden state,也就是LSTM的最终输出),g(·)为非线性函数。
2.2 Convolutional Gated Unit
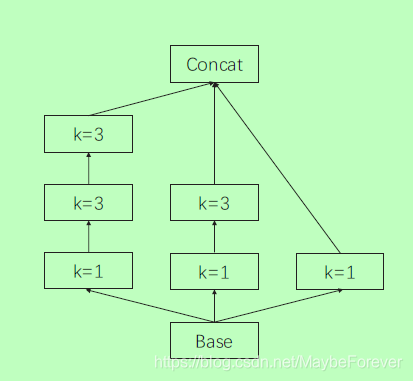
图一:我们提出的卷积门控单元的结构。我们对RNN编码器的输出进行一维卷积,其结构类似于Inception (Szegedy et al., 2015),其中k表示内核大小。
摘要需要在每个编码时间步上的核心信息。为了达到这个目的,我们在编码器输出的每个时间步上实现一个门控单元,它是一个CNN,对所有编码器输出进行卷积。卷积核的参数共享使模型能够提取特定类型的特征,特别是n-gram特征。与图像相似,语言也包含局部相关,如短语结构的内部相关。卷积单元可以提取语句中的这些公共特征,并指出源注释之间的相关性。此外,为了进一步加强全局信息,我们实施了self-attention (Vaswani et al., 2017)来挖掘某个时间步长注释与其他注释之间的关系。因此,门控单元能够找出共同的n-gram特征和全局相关性。门控单元基于卷积和自我注意,设置一个门来过滤来自RNN编码器的源注释,以选择与全局语义相关的信息。全局编码允许编码器在每个时间步长的输出成为新的表示向量,并进一步连接到全局源端信息。对于卷积,我们实现了一个类似于inception的结构(Szegedy et al., 2015)。我们使用一维卷积来提取n-gram特征。遵循先启的设计原则,我们没有在k=5的地方使用kernel,而是在k=3的地方使用两个kernels,以避免内核过大。卷积块的细节如下所述:

其中ReLU为非线性激活函数整流线性单元(Nair and Hinton, 2010)。基于卷积块,我们实现了一个类似于inception的结构,如图1所示。
在CNN模块生成的新表示法的基础上,我们进一步实现了对这些表示法的自我关注,从而挖掘出全局的相关性。Vaswani等人(2017)指出,自我关注鼓励模型学习长期依赖关系,且不产生太多计算复杂度,因此我们对每一步注释与全局信息之间的联系实现了其缩放的点积注意力(scaled dot-product attention):

其中的表征,是计算通过注意机制本身和包装成一个矩阵。具体来说,我们将Q和V表示为CNN模块生成的表示矩阵,K = WattV,其中Watt是一个可学习的矩阵。
进一步的步骤是根据来自CNN的生成和来自RNN编码器的源表示h’的self-attention模块g来设置一个门,其中:
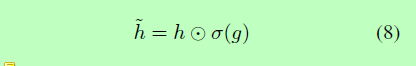
由于CNN模块可以提取整个源文本的n-gram特征,self-attention学习输入源文本组件之间的长期依赖关系,所以gate可以对编码器输出进行全局编码。根据CNN和self-attention的输出,logistic sigmoid函数在每个维度上输出一个值在0到1之间的向量。如果该值接近0,那么gate将删除源表示对应维度上的大部分信息,如果接近1,则保留大部分信息。
2.3 Training
接下来,我们将介绍我们进行实验的数据集以及我们的实验设置。
考虑到参数θ和源文本x,模型要生成一个摘要y。学习过程是最小化之间的负对数似生成摘要y和参考 y:
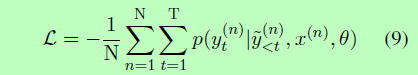
损失函数相当于给定参数θ和源序列x,摘要y的条件概率最大化。
三、Experiment Setup
在下面,我们将介绍我们进行实验的数据集、我们的实验设置以及我们进行比较的基线模型。
3.1 Datasets
LCSTS是从中国著名社交媒体网站新浪微博(Hu et al., 2015)上收集的大型中文短文本摘要数据集,包含240多万对文本摘要。原始文本短于140个汉字,摘要是人工创建的。我们根据之前的研究(Hu et al., 2015)对数据集进行了训练、验证和测试的分割,其中训练用了240万对句子,验证用了8K,测试用了0.7K。
英语Gigaword是一个基于带注释的Gigaword (Napoles et al., 2012)的句子摘要数据集,该数据集由句子对组成,即收集到的新闻文章的第一个句子和相应的标题。我们使用Rush等人(2015)预处理的数据,380万对句子用于训练,8K用于验证,2K用于测试。
3.2 Experiment Settings
我们在一个NVIDIA 1080Ti GPU上用PyTorch实现了我们的实验。嵌入维数和隐藏单元数都是512。在两个实验中,批量大小都设置为64。我们用亚当优化器(Kingma和Ba, 2014),默认设置α= 0.001,β1 = 0.9,β2 = 0.999和ǫ= 1×10−8。学习速度每隔一段时间就减半。梯度裁剪应用范围[- 10,10]。
根据之前的研究,我们选择ROUGE score来评价我们的模型的性能(Lin and Hovy, 2003)。ROUGE score是计算生成的总结和参考之间的重叠程度,包括n-grans的数量。以ROUGE score-1、ROUGE score- 2、ROUGE score-l 的F1得分作为评价指标。
3.3 Baseline Models
当我们将我们的结果与他们的原始论文中报告的基线模型的结果进行比较时,两个数据集的评估有不同的基线。接下来,我们将分别介绍LCSTS和Gigaword的基线。
下文将介绍LCSTS的基线。RNN和RNN-context是基于RNNbased的seq2seq模型(Hu et al., 2015),分别没有和有注意机制。copy - net是基于注意力的seq2seq模型,具有复制机制(Gu et al., 2016)。SRB是一种改进源文本和摘要之间语义相关性的模型(Ma et al., 2017)。DRGD是传统的seq2seq,带有深度循环生成解码器(Li et al., 2017)。
至于Gigaword的基线,ABS和ABS+是具有本地关注和手工制作功能的模型(Rush et al., 2015)。专长是一个完整的RNN seq2seq模型与一些具体的方法来控制词汇量。RASLSTMand rasr -Elman是seq2seq模型,分别具有卷积编码器、LSTM解码器和Elman RNN解码器。SEASS是一个带有选择门机制的seq2seq模型。DRGD也是Gigaword的基准。
我们在两个数据集上实现常规seq2seq模型的结果也被用于评估我们提出的卷积门控单元(CGU)的改进。
四、Analysis
在接下来的章节中,我们报告了我们的实验结果,并分析了我们的模型在重复评估方面的性能。此外,我们还提供了一个示例来演示我们的模型可以生成与源文本在语义上更一致的摘要。
4.1 Results
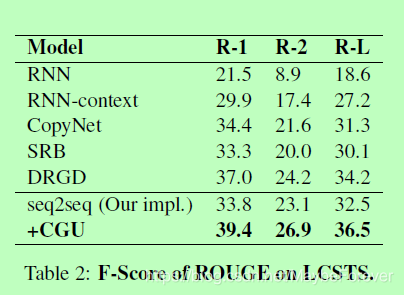
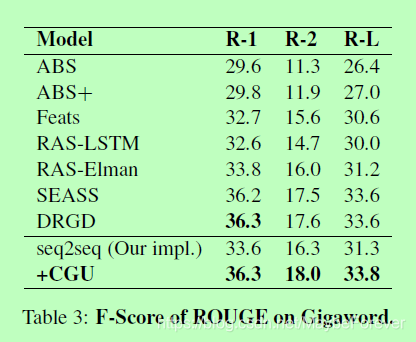
在两个数据集的实验中,我们的模型实现了 ROUGE score在基线上的优势,并且在LCSTS上 ROUGE score的优势是显著的。表2显示了我们模型的结果和LCSTS上的基线,表2显示了Gigaword上模型的结果。我们将模型的F1评分与基线模型(在其原始文章中报道)和我们自己实现的基于注意力的seq2seq进行了比较。与传统的seq2seq模型相比,我们的模型在LCSTS和Gigaword上分别具有ROUGE-2评分3.7分和1.5分的优势。
4.2 Discussion

我们展示了我们的模型与基线seq2seq模型和参考产生的总结。本文介绍了星巴克在美国的一个普通咖啡品牌,成为一个高档品牌,并以更高的价格销售咖啡的现象。很明显,文章的主要观点是关于星巴克咖啡在中国的高价。然而,seq2seq模型生成的摘要只包含品牌和国家的信息。此外,它还犯了重复使用“中国”一词的错误。它在语义上与源文本不相关,也不连贯,不够充分。与之相比,我们的模型摘要更连贯,语义上与源文本更相关。我们的模型关注的是价格信息而不是国家信息,并在生成的摘要中指出了价格差距。作为“中国”出现两次在源文本和基线模型很难把它在一个不那么重要的地方,但与问对我们的模型,它能够过滤琐碎的细节与源文本的核心意义无关,只是专注于提供的信息最主要的思想。
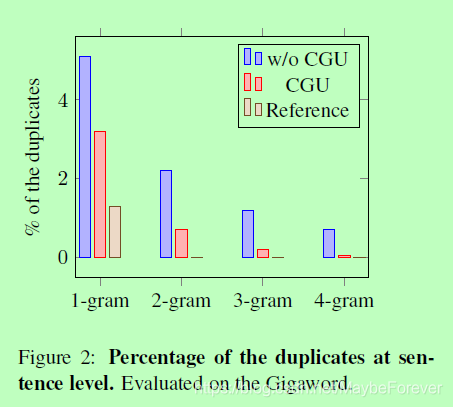
由于我们的CGU负责从RNN编码器中选择输出的重要信息来提高注意力评分的质量,所以它应该能够减少生成摘要中的重复。我们通过计算句子重复的百分比来评估重复的程度。对1-gram到4-gram重复样本的Gigaword进行了评价,结果表明,与传统的seq2seq相比,我们的模型显著减少了重复,重复率与参考文献相近。这也表明我们的模型能够以较少的重复生成更高多样性的摘要。
五、Related Work
研究人员开发了许多统计方法和基于语言规则的方法来研究自动摘要(Banko et al., 2000;多尔等人,2003;Zajic等,2004;Cohn和Lapata, 2008)。随着神经网络在自然语言处理中的发展,越来越多的研究出现在抽象概括中,神经网络似乎可以帮助实现这两个目标。Rush等(2015)首次将具有注意机制的序列-等价模型应用于抽象概括,并取得了显著的成果。Chopra等人(2016)使用RNN解码器改变了ABS模型,Nallapati等人(2016)将系统改为全RNN序列-序列模型,取得了优异的性能。Zhou等(2017)提出了一种选择性门机制来过滤二次信息。Li等人(2017)提出了一种用于学习潜在结构信息的深度递归生成译码器。Ma等人(2018)提出了一种通过查询词嵌入来生成单词的模型。
六、Conclusion
在本文中,我们提出了一种新的抽象摘要模型。卷积门控单元对源端信息进行全局编码,保留核心信息,过滤二次信息。在LCSTS和Gigaword上的实验表明,我们的模型优于基线,分析表明,与传统的seq2seq模型相比,该模型能够减少生成摘要中的重复,并且对于不同长度的输入具有更强的鲁棒性。
