ACL 2019 Sentence Centrality Revisited for Unsupervised Summarization
单文档的文本摘要任务已经取得了不错的进展,不同的研究人员纷纷提出了不同的解决思路和摘要模型,有关进展可浏览之前的几篇博文,这里就不再赘述:
- Development of Neural Network Models in Text Summarization - 1
- Development of Neural Network Models in Text Summarization - 2
- Development of Neural Network Models in Text Summarization - 3
- Development of Neural Network Models in Text Summarization - 4
- Template Based Neural Summarization Models
- Generate summaries in an unsupervised manner
由于大规模、高质量的标注数据集不易获取,因为本文提出了一种新的无监督文本摘要模型。模型的整体思想建立在图结构上,文档中的句子做为图中顶点,句子之间的相似性分数做为边的权值。模型的运行流程如下:
- 通过BERT获取句子的表示向量
- 根据句子的表示向量和彼此之间的相似度分数构建有向图,任意两个节点对于中心性(centrality)的贡献取决于它们在文档中的相对位置
最后在CNN/Daily Mail、NYT和TTNews三个数据集进行试验证明了模型的有效性,并进一步的显示了文档中句子的位置信息对于抽取式摘要生成任务的重要性。
假设所处理的文档记为
,
表示句子对
之间的相似性分数。每一个句子的中心性是通过计算它和其他句子的相似度分数的和来度量的,具体计算公式如下所示:
然后根据得到的结果降序排列,最后选择分数最高的句子作为最后结果的一部分。前面说到数据的表示整体上基于图结构,因此这里使用了PageRank来实现分数的排序。
直觉上来说,一篇文档中的句子并不具有相等的重要性,即最后的摘要中不可能包含所有的句子,因此可以采用类似于RST(Rhetorical Structure Theory)的思想构建图。
RST是一种语篇结构的构建模式,它逐渐的将基本的语篇单元合并为更大的语篇单元,直到最终覆盖全文档。
因此,通过图的构建我们可以知道哪些句子是重要的,哪些是相对来说没那么重要的,接着不断的从重要的句子开始抽取摘要中的部分,直到满足设定的长度需求。
为了实现语篇单元的划分,一种方法是使用语篇解析器(discourse parser),但是它严重依赖于标注语料库的存在,同时需要额外的使用一些相关的工具,较为麻烦。另一种方法相比就很简单且直接,即直接使用句子在文档中的相对位置来逼近真实中心性的度量。因为通常来说位于文档前面的句子通常包含有更多的信息,因此通过句子之间的位置信息就可以简单的实现语篇单元的划分。
另外文中对于一个句子对
来说构建的是有向边,对应的权重分别是
和
,这样句子的中心性计算就使用了一种线性插值的方式,通过超参数
和
来进行权衡。
其中 和 分别负责前向边和后向边。而超参数的值可以根据验证集来自动微调,也可以根据人的先验知识进行手工的调整。文中为了方便后续的实验,规定 ,同时这里也只考虑权值为正的情况。
在明确了图的构建方式后,接下来就需要考虑句子表示向量的获取和相似性度量方式的选择。
-
表示向量:直接使用了BERT来获取句子的表示向量,借助预训练模型的强大表示能力,希望它能更好的捕捉上下文信息。同时借鉴负采样思想,将 的前一句 和后一句 作为正样本,将语料库中的其他随机选择的句子作为负样本,通过优化如下的目标函数来训练得到 的表示向量
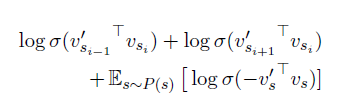
其中 和 是参数不同的BERT对于同句的不同表示
-
相似性度量:文中试验了点乘(pair-wise dot product)和余弦相似度两种方式,发现简单的点乘效果更好一些。
另外对于相似度分数进行了标准化,通过这样的方式可以强调不同相似度分数的相对分布
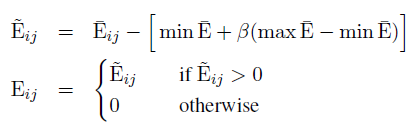
其中 。
实验结果
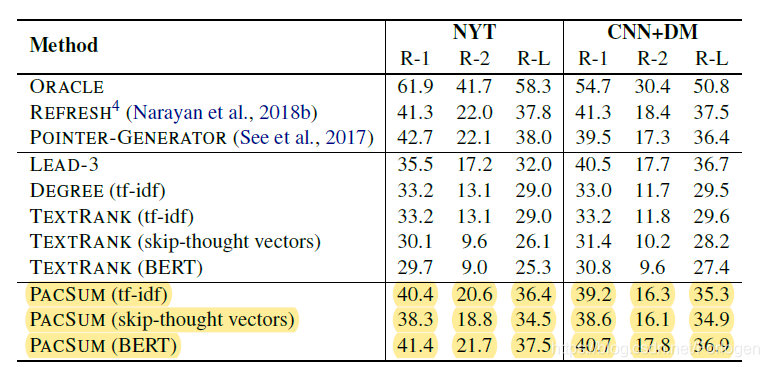
更详细的实验结果可见原文。
下面我们来看一下github上的开源代码,整个代码的结构如下所示:
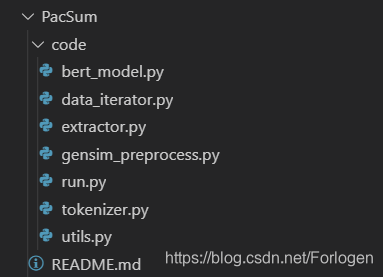
其中gensim_preprocess.py中主要是使用gensim这个库对文本进行的一系列预处理操作,其中的多个正则式可以重复用在自己的项目中
RE_PUNCT = re.compile(r'([%s])+' % re.escape(string.punctuation), re.UNICODE)
RE_TAGS = re.compile(r"<([^>]+)>", re.UNICODE)
RE_NUMERIC = re.compile(r"[0-9]+", re.UNICODE)
RE_NONALPHA = re.compile(r"\W", re.UNICODE)
RE_AL_NUM = re.compile(r"([a-z]+)([0-9]+)", flags=re.UNICODE)
RE_NUM_AL = re.compile(r"([0-9]+)([a-z]+)", flags=re.UNICODE)
RE_WHITESPACE = re.compile(r"(\s)+", re.UNICODE)
utils.py主要是使用pyrouge来计算ROUGE分数的部分
def evaluate_rouge(summaries, references, remove_temp=False, rouge_args=[]):
'''
Args:
summaries: [[sentence]]. Each summary is a list of strings (sentences)
references: [[[sentence]]]. Each reference is a list of candidate summaries.
remove_temp: bool. Whether to remove the temporary files created during evaluation.
rouge_args: [string]. A list of arguments to pass to the ROUGE CLI.
'''
temp_dir = ''.join(random.choices(string.ascii_uppercase + string.digits, k=10))
temp_dir = os.path.join("temp",temp_dir)
print(temp_dir)
system_dir = os.path.join(temp_dir, 'system')
model_dir = os.path.join(temp_dir, 'model')
# directory for generated summaries
os.makedirs(system_dir)
# directory for reference summaries
os.makedirs(model_dir)
print(temp_dir, system_dir, model_dir)
assert len(summaries) == len(references)
for i, (summary, candidates) in enumerate(zip(summaries, references)):
summary_fn = '%i.txt' % i
for j, candidate in enumerate(candidates):
candidate_fn = '%i.%i.txt' % (i, j)
with open(os.path.join(model_dir, candidate_fn), 'w') as f:
f.write('\n'.join(candidate))
with open(os.path.join(system_dir, summary_fn), 'w') as f:
f.write('\n'.join(summary))
args_str = ' '.join(map(str, rouge_args))
rouge = Rouge155(rouge_args=args_str)
rouge.system_dir = system_dir
rouge.model_dir = model_dir
rouge.system_filename_pattern = '(\d+).txt'
rouge.model_filename_pattern = '#ID#.\d+.txt'
output = rouge.convert_and_evaluate()
r = rouge.output_to_dict(output)
print(output)
return r
tokenizer.py主要完成分词的任务,其中包含了BERT中使用的两种tokenizer:FullTokenizer和WprdpieceTokenizer。
bert_model.py中包含构建一个BERT所需的一些基本组件,这个部分并不需要自己重写,只需使用已有的代码学会怎么得到一个BERT即可。
data_iterator.py完成批数据的产生任务,从而实现为不同的Extractor提供数据进行训练。
接下来看一下run.py,从中可以看出整个项目主要是使用了PacSumExtractorWithTfIdf和PacSumExtractorWithBert这两种抽取模型,而且都可以使用参数的自动微调。
if args.rep == 'tfidf':
# 获取 tf-idf 摘要抽取模型
extractor = PacSumExtractorWithTfIdf(beta = args.beta,
lambda1=args.lambda1,
lambda2=args.lambda2)
#tune
if args.mode == 'tune':
tune_dataset = Dataset(args.tune_data_file)
tune_dataset_iterator = tune_dataset.iterate_once_doc_tfidf()
extractor.tune_hparams(tune_dataset_iterator)
#test
test_dataset = Dataset(args.test_data_file)
test_dataset_iterator = test_dataset.iterate_once_doc_tfidf()
extractor.extract_summary(test_dataset_iterator)
elif args.rep == 'bert':
extractor = PacSumExtractorWithBert(bert_model_file = args.bert_model_file,
bert_config_file = args.bert_config_file,
beta = args.beta,
lambda1=args.lambda1,
lambda2=args.lambda2)
#tune
if args.mode == 'tune':
tune_dataset = Dataset(args.tune_data_file, vocab_file = args.bert_vocab_file)
tune_dataset_iterator = tune_dataset.iterate_once_doc_bert()
extractor.tune_hparams(tune_dataset_iterator)
#test
test_dataset = Dataset(args.test_data_file, vocab_file = args.bert_vocab_file)
test_dataset_iterator = test_dataset.iterate_once_doc_bert()
extractor.extract_summary(test_dataset_iterator)
在extractor.py中包含了整个模型的实现逻辑,它主要包含PacSumExtractor这个基类和PacSumExtractorWithBert、PacSumExtractorWithTfIdf两种不同的实现。
PacSumExtractorWithBert
class PacSumExtractorWithBert(PacSumExtractor):
def __init__(self, bert_model_file, bert_config_file, extract_num = 3, beta = 3, lambda1 = -0.2, lambda2 = -0.2):
super(PacSumExtractorWithBert, self).__init__(extract_num, beta, lambda1, lambda2)
self.model = self._load_edge_model(bert_model_file, bert_config_file)
def _calculate_similarity_matrix(self, x, t, w, x_c, t_c, w_c, pair_indice):
#doc: a list of sequences, each sequence is a list of words
def pairdown(scores, pair_indice, length):
#1 for self score
out_matrix = np.ones((length, length))
for pair in pair_indice:
out_matrix[pair[0][0]][pair[0][1]] = scores[pair[1]]
out_matrix[pair[0][1]][pair[0][0]] = scores[pair[1]]
return out_matrix
scores = self._generate_score(x, t, w, x_c, t_c, w_c)
doc_len = int(math.sqrt(len(x)*2)) + 1
similarity_matrix = pairdown(scores, pair_indice, doc_len)
return similarity_matrix
def _generate_score(self, x, t, w, x_c, t_c, w_c):
#score = log PMI -log k
scores = torch.zeros(len(x)).cuda()
step = 20
for i in range(0,len(x),step):
batch_x = x[i:i+step]
batch_t = t[i:i+step]
batch_w = w[i:i+step]
batch_x_c = x_c[i:i+step]
batch_t_c = t_c[i:i+step]
batch_w_c = w_c[i:i+step]
inputs = tuple(t.to('cuda') for t in (batch_x, batch_t, batch_w, batch_x_c, batch_t_c, batch_w_c))
batch_scores, batch_pros = self.model(*inputs)
scores[i:i+step] = batch_scores.detach()
return scores
def _load_edge_model(self, bert_model_file, bert_config_file):
bert_config = BertConfig.from_json_file(bert_config_file)
model = BertEdgeScorer(bert_config)
model_states = torch.load(bert_model_file)
print(model_states.keys())
model.bert.load_state_dict(model_states)
model.cuda()
model.eval()
return model
PacSumExtractorWithTfIdf
class PacSumExtractorWithTfIdf(PacSumExtractor):
def __init__(self, extract_num = 3, beta = 3, lambda1 = -0.2, lambda2 = -0.2):
super(PacSumExtractorWithTfIdf, self).__init__(extract_num, beta, lambda1, lambda2)
def _calculate_similarity_matrix(self, doc):
idf_score = self._calculate_idf_scores(doc)
tf_scores = [
Counter(sentence) for sentence in doc
]
length = len(doc)
similarity_matrix = np.zeros([length] * 2)
for i in range(length):
for j in range(i, length):
similarity = self._idf_modified_dot(tf_scores, i, j, idf_score)
if similarity:
similarity_matrix[i, j] = similarity
similarity_matrix[j, i] = similarity
return similarity_matrix
def _idf_modified_dot(self, tf_scores, i, j, idf_score):
if i == j:
return 1
tf_i, tf_j = tf_scores[i], tf_scores[j]
words_i, words_j = set(tf_i.keys()), set(tf_j.keys())
score = 0
for word in words_i & words_j:
idf = idf_score[word]
score += tf_i[word] * tf_j[word] * idf ** 2
return score
def _calculate_idf_scores(self, doc):
doc_number_total = 0.
df = {}
for i, sen in enumerate(doc):
tf = Counter(sen)
for word in tf.keys():
if word not in df:
df[word] = 0
df[word] += 1
doc_number_total += 1
idf_score = {}
for word, freq in df.items():
idf_score[word] = math.log(doc_number_total - freq + 0.5) - math.log(freq + 0.5)
return idf_score
