ACL 2019 Self-Supervised Learning for Contextualized Extractive Summarization
背景
本文所表述的内容十分的清晰明了,同样也很简单,即如何使用不同的预训练策略来提升抽取式摘要任务的效果。作者指出:现有的模型在抽取句子使用交叉熵训练模型时,往往只考虑了句子级别的信息,并没有很好的捕获全局或说是文档级的信息,因此对于最后的生成结果也有一定的影响。
而大热的预训练模型的优异效果强势的证明了:类似于BERT中的mask机制和预测下一句等不同的预训练策略可以以自监督的方式有效的提升模型在下游具体任务上的效果。因此,作者在本文中尝试了Mask、Replace和Switch三种不同的预训练策略,并在CNN/DM数据集上实验证明了它们的有效性。
模型
本文中实验所使用的模型如下:
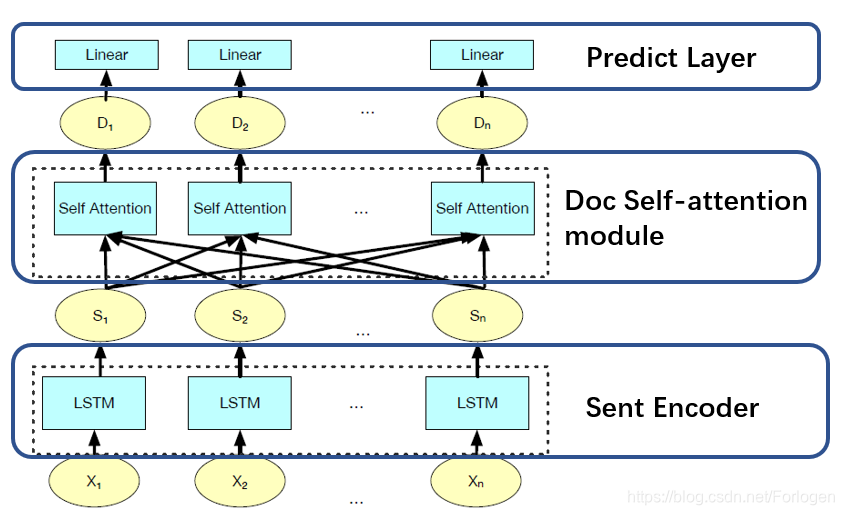
该模型整体上并没有分支结构,因此理解起来十分容易。它主要由以下的三部分组成:
- Sentence Encoder:使用单层的双向LSTM对于文档中的句子进行编码,使用最后一步的输出作为当前句子的表示
- Doc Self-attention module:使用六层四头的Transformer捕获全局信息,得到每个句子在文档层次上的表示
- Linear Layer:使用线性层来预测哪些句子会出现在最后的结果中
模型并不是关注的焦点,任何一个简单的抽取式模型都可以作为本文预训练策略的验证模型。
Mask
这里的Mask不同于BERT中预测mask掉词的方式,它所关注的层级是句子。首先从所处理文档中选择一些句子作为mask的部分并将其放到候选池
中,同时将文档中相应位置使用<unk>进行填补。通过模型可以获取到文档中句子两个层次上的表示向量
和
。最后使用余弦相似度来评估
中的句子可能是文档中mask部分的概率:
对应的损失函数这里选择的是ranking loss:
Replace
Replace策略类似Mask,不同之处在于替换的内容不是<unk>,而是从其他文档中随机选择的句子,然后让模型预测某个句子是否是被替换的。这样模型的训练将相当于二分类问题,因此对应的损失函数为:
Switch
Switch又类似于Replace,不过它只随机的交换本文档中的句子位置,并不使用其他文档中的内容。对于所处理文档中的每一个句子而言,预测是否是交换过的问题也就是二分类问题,因此这里的损失函数仍然是均方误差:
其中当
时表示该位置的句子是交换顺序后的结果。
实验
在CNN/DM数据集上的实验结果如下:
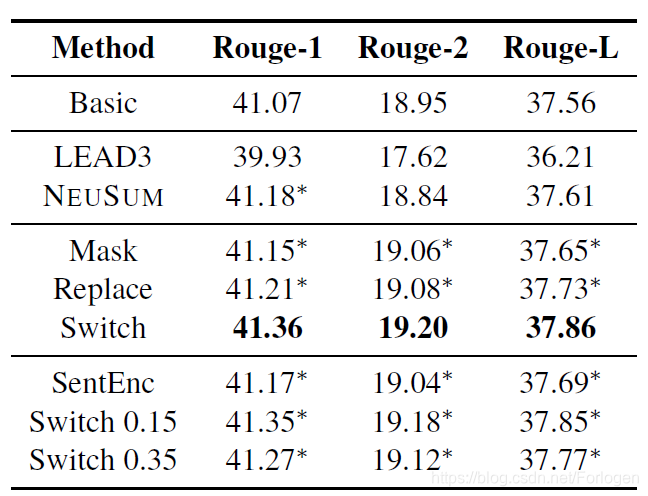
总之只需要清楚:三种预训练策略中Switch的效果更好,模型收敛的速度更快,而且预训练确实可以有效的提升下游任务的效果~
