转自:https://blog.csdn.net/zhangxb35/article/details/78626799
ABS 和 ABS+
[Rush, 2015] A Neural Attention Model for Abstractive Sentence Summarization
这篇 facebook 的论文是用神经网络来做生成式摘要的开山之作,后续的论文基本都会引用。而且在 github 上有开源的代码放出来,可以参考 facebook/NAMAS.
模型的主要结构见下图(a),即左边的那部分,其实本质上就是个 conditional neural network language model,也就是要最大化概率 p(yi+1|x,yc;θ)p(yi+1|x,yc;θ),这一套框架还是逃不了 Bengio 那篇2003年的经典论文 A Neural Probabilistic Language Model.
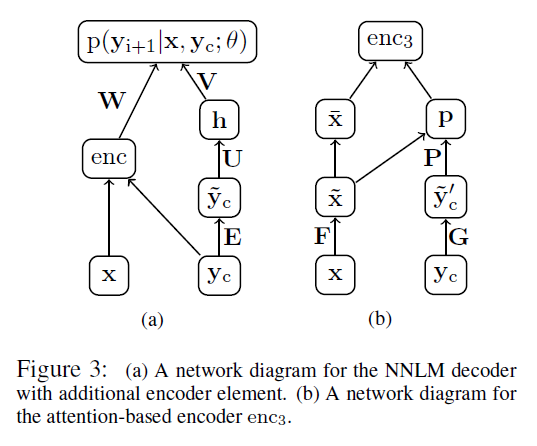
图中的 x,yx,y 表示输入/输出的序列, ycyc 是 yi+1yi+1 的前 CC 个词(不够就做 padding),可以看做是 yi+1yi+1 的上下文信息(context)。θθ 泛指模型的参数,如 W,V,U,EW,V,U,E 和 enc 网络中的参数。
子网络 enc 是 encoder,要把输入序列 xx 和 context 信息融合,(b) 图就是就是其中一种设计,用上了 Attention 的思想。这个后面再细讲。回到 (a) 图上来,y~cy~c 是 ycyc 的词向量表示。具体公式如下,
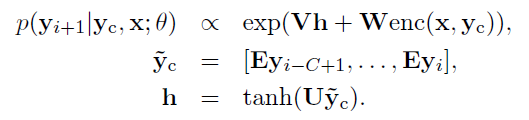
论文尝试了三种 encoder 的方式,分别是 Bag-of-Words,CNN 和 Attention-Based,公式如下,

其中 BoW 的做法是直接把 xx 的词向量叠加,不考虑和 context 信息的融合,最后的效果也比较差一些;Convolutional Encoder 就是标准的卷积和池化操作,其中 QlQl 就是第 ll 层的卷积核,最上面的 max 操作是沿着时间找个最大的,剩下的维度只是卷积核的个数了,也就是 encoder 网络得到的特征维度大小。Attention-Based Encoder 和之前的 Attention 做法很类似,想要把 xx 和 ycyc 融合起来。F,GF,G 都是词向量矩阵,x¯ix¯i 是平滑后的 x~ix~i,而 y~′cy~c′ 则是 ycyc 的词向量表示。pp 相当于 Attention 中的权重 αtαt,而 enc3(x,yc)enc3(x,yc) 的输出则相当于是 context vector ctct.
上面的模型可以简称为 ABS,作者还尝试了与 extractive 的方法结合,就有了 ABS+ 模型。即在每次解码出一个词的时候,不仅考虑神经网络对当前词的预测概率 logp(yi+1|x,yc;θ)logp(yi+1|x,yc;θ),还要开个窗口,去找一找当前窗口内的词是否在原文中出现过,如果有的话,概率会变大。根据窗口的不同大小,就等价于 unigram, bigram 和 trigram 特征。
论文在 DUC-2004 和 Gigawords 上做实验,结果也是 enc1 < enc2 < enc3,而且基本都比之前非 neural-network 的模型效果好。ABS+ 的效果明显好于 ABS,因为这篇论文是个 baseline,具体的实验结果会和后面的论文一起对比,这里略过。
LCSTS, SimpleAttention, TextSum 和 RAS
下面这几个工作简单提一下,
- [Hu, 2015] LCSTS: A large scale Chinese short text summarization dataset
- [Lopyrev, 2015] Generating News Headlines with Recurrent Neural Networks
- [Google, 2015] Sequence-to-Sequence with Attention Model for Text Summarization
- [Chopra, 2016] Abstractive sentence summarization with attentive recurrent neural networks
首先,[Hu 2015] 的贡献在于提出了一个新的中文数据集,LCSTS,该数据集是从新浪微博中爬取过滤得到的,训练集(Part I)有 240w 对数据,验证集(Part II)有 1w,测试集(Part III)有 1k 多一点。而且验证集和测试集用人工标注了正文和标题之间的相关度(relevance),并且从 1-5 打分,分数越高越好。见 Table 1 所示。
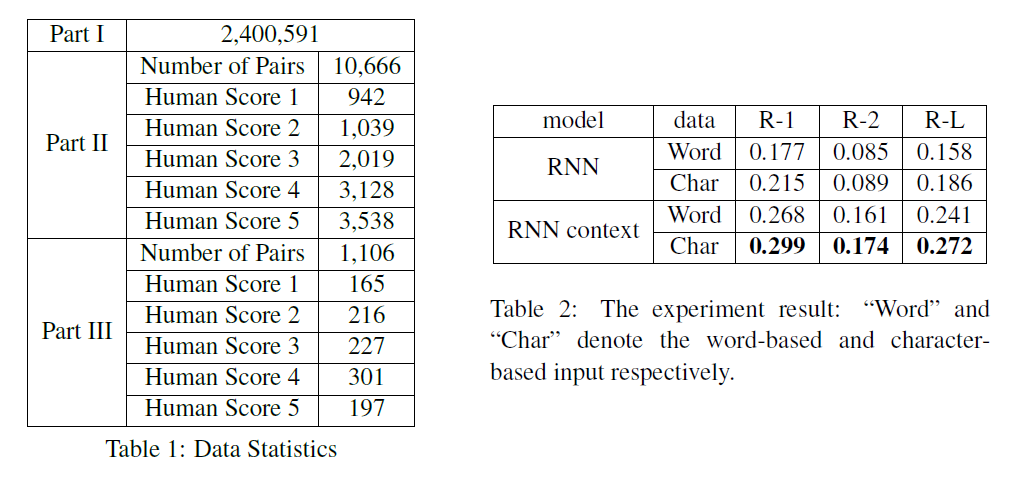
此外,论文对该数据集做了一个 baseline,用 GRU 搭建 seq2seq 和 Context(就是Attention) 两个模型,并且用字符(char)和词语(word)分别实验,共四个模型,见 Table 2 的结果。由于结巴分词后的词表必然比单字要大很多,因此有很多 OOV 的词,而且词表大了训练也很慢,预测起来也相对较难,因此还是 Char + RNN context 效果最好。
提一个小的点,就是这篇论文用了标准的 rouge 来评测,但是这个网站我一直登陆不了,不知道 pip 工具 rouge 和 pyrouge 和这个有没有区别,待挖掘。
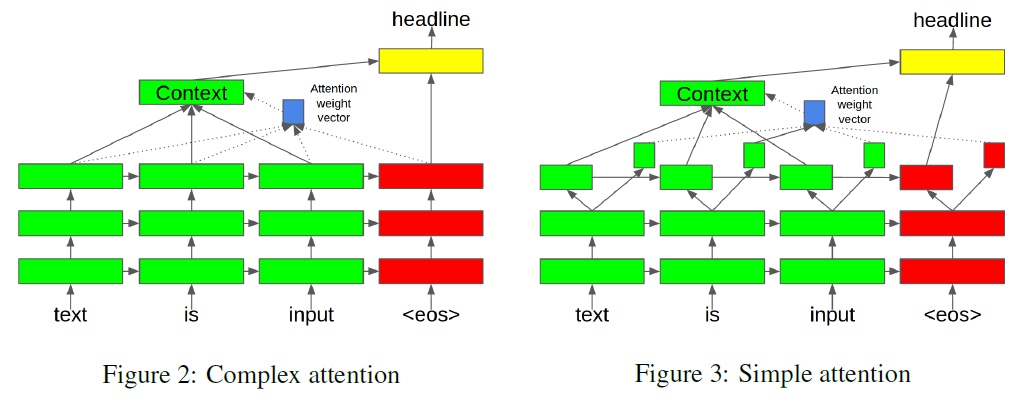
[Lopyrev, 2015] 没有什么亮点,就是把 encoder 和 decoder 都拆成两部分,算 Attention 的时候用小的那部分,正常的用大的那部分。一图以蔽之,
[Google, 2015] 其实不是论文,而是代码,但是挺具有参考意义,包括 Attention,BeamSearch 的实现等等。
[Chopra, 2016] 这篇说白了就是 CNN-RNN 的 seq2seq 结构,和第一篇论文 [Rush 2015] 是同一个小组(facebook 和 Harvard SEAS)的工作。根据 RNN 用的不同,模型叫做 RAS-Elman 和 RAS-LSTM,代码实现和 [Rush 2015] 放到了一起,见 facebook/NAMAS.
RNNs and Beyond
[Nallapati, 2016] Abstractive Text Summarization using Sequence-to-sequence RNNs and Beyond
这篇论文是 IBM Watson 实验室的工作,针对前面的 baseline 做的改进还挺多的,主要是下面几个方面
- 引入 Large Vocablary Trick 来解决 decoder 词表过大的问题;
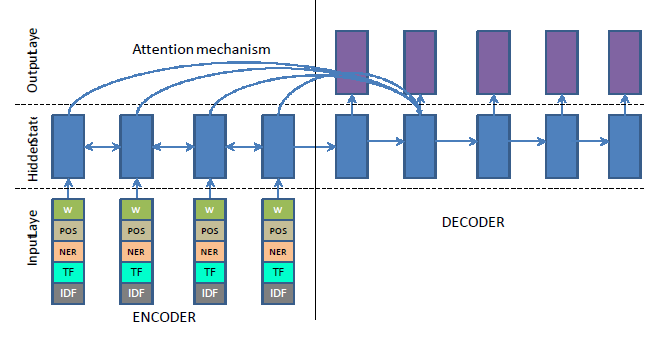
- 加入传统的 TF-IDF,POS,NER 等特征来尝试抓住句子的关键部分;
- 引入 Generator-Pointer 来解决 OOV 和低频词的问题;
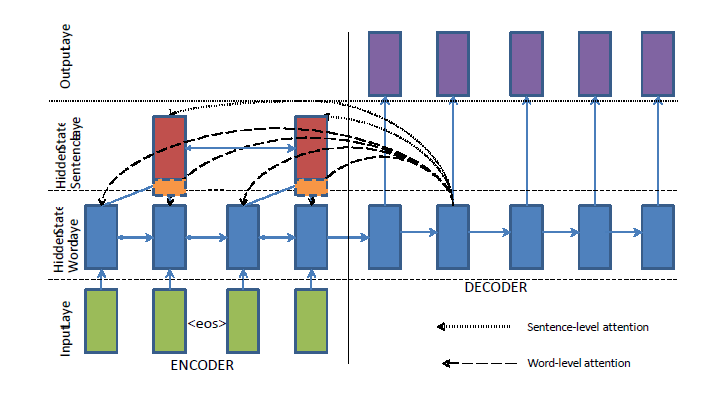
- 引入 Hierarchical Attention 来抓住句子的重要性信息;
- 引入 Temporal Attention 来缓解连续生成重复词的问题;
- 提出新的数据集 CNN/Daily Mail.
首先引入 LVT,这个 tensorflow 也有实现,参考 tf.nn.sampled_softmax_loss 和原始论文 On Using Very Large Target Vocabulary for Neural Machine Translation. 因此大部分的计算都在 decoder 预测词得分 logits,特别是如果用词级别来编码,词表可以到几万或者几十万的大小,使用 LVT 以后可以缩小一两个数量级,因此很有必要。因为交叉熵只关心正确答案对应词的概率,LVT 的原理大致是用负采样来估计 softmax 的分母,其他的就不用算了,因此可以大大节约计算量和训练时间。实际实验中,作者发现 2k 个负采样就基本够了。
引入语言学特征(linguistic feature)的目的是为了抓住句子中的关键概念和关键实体等,就是说哪些词是这段话想要表达的主体和重点。论文的做法比较简单,抽取了词性标注(POS tagging)、命名实体识别(NER)和 TF-IDF 特征,直接 embedding 后和词向量拼接到一起。这里只是 encoder 做这些工作,decoder 还是只用词向量。注意这里的 TF-IDF 是连续值,需要先离散化才能 embedding 成向量。见下图,
Generator-Pointer 的机制和后面要讲的 Pointing,CopyNet 等都是一个思路。因为摘要的任务特点,很多 OOV 或者不常见的 的词其实可以从输入序列中找到,因此一个很自然的想法就是去预测一个开关(switch)的概率 P(si=1)=f(hi,yi−1,ci)P(si=1)=f(hi,yi−1,ci),如果开关打开了,就是正常地预测词表;如果开关关上了,就需要去原文中指向一个位置作为输出。在训练的过程中,这个 P(st)P(st) 是有监督地给出,假设给出的 pointer label 叫做 gigi。见下面的 loss,
logP(y|x)=∑i(gilog{P(yi|y−i,x)P(si)}+(1−gi)logP(p(i)|y−i,x)(1−P(si)))logP(y|x)=∑i(gilog{P(yi|y−i,x)P(si)}+(1−gi)logP(p(i)|y−i,x)(1−P(si)))
上面的损失函数比较长,但是逻辑还是比较清晰的,大概是 ∑i(gilogA+(1−gi)logB)∑i(gilogA+(1−gi)logB) 这种交叉熵的形式。也就是说,当 gi=0gi=0 是,模型是拷贝,从原文里指向某个位置 p(i)p(i),具体是直接复用 Attention 的概率分布 Pai(j)Pia(j),就是在第 ii 时刻指向原文第 jj 个位置的概率;当 gi=1gi=1 时,则是生成概率,直接像原来那样算词表的概率就好了。见下图,

受 A hierarchical neural autoencoder for paragraphs and documents 的启发,引入 Hierarchical Attention 的引入来处理原文太长的问题,如果原文的句子很多,其实大部分的句子都是没有必要去看的,不过处理不了太长文本,根本原因还是 LSTM 不能完全避免梯度消失,毕竟 memory cell 的大小也是有限制的。Hierarchical Attention 是尝试给每个句子一个权重,有点抽取式摘要的意思。论文用了两个双向的 LSTM 分别用于 word-level 和 sentence-level 的特征提取。而最后的 Attention 是 word-leval Attention Paw(j)Pwa(j) 乘上 sentence-level Attention Pas(j)Psa(j),如下面的公式,
Pa(j)=Paw(j)Pas(s(j))∑Ndk=1Paw(k)Pas(s(k))Pa(j)=Pwa(j)Psa(s(j))∑k=1NdPwa(k)Psa(s(k))
其中 Pa(j)Pa(j) 是重新调整过的 Attention 权重,s(j) 是第 jj 个词对应的句子 ID,NdNd 是输入文本中词的个数。值得一提的是,在 sentence-leval RNN 中,额外加入了句子的位置 embedding 信息,因为比较靠前或者结尾的句子可能一般会有总结的信息。
Temporal Attention 的是来源于论文 Temporal Attention Model for Neural Machine Translation,做法也很简单,即拿未归一化的 Attention 权重 α′tαt′ 除以之前积累的权重 βtβt,如下,
βt=∑k=1t−1α′k;αt∝a′tβtβt=∑k=1t−1αk′;αt∝at′βt
实验部分是在 DUC-2004,Gigawords 上做的,后来自己又提了一个 CNN/Daily Mail,只能和自己对比。在 DUC-2004 上的效果和 RAS-Elman 差不多,但是 Gigawords 上因为句子比较长,所以更能体现模型的优势,效果也是提升很大。见下图 Gigawords 的结果,

LenEmb
[Kikuchi 2016] Controling Output Length in Neural Encoder-Decoders
这篇论文挺有意思,论文构建了四种控制 seq2seq 中生成句子的长度,而且在 Text Summarization 上做了实验,结果并没有太多的损失。
前两种方法叫做 fixLen 和 fixRng 模型,都是没有改之前训练的模型,只是在测试集上解码的时候,做了点改动。fixLen 是说,在到达给定长度之前为了防止句子提前结束,替换 EOS 的概率为 0(分数为 -∞),到达固定长度,强行替换 EOS。fixRng,也是训练不变,只改 decoder。给定一个长度范围,在 beam search 解码时,如果生成的句子小于最小长度,直接丢弃掉;如果大于最大长度,直接像上面一样强行替换 EOS,再加入 beam search 的候选集。这个方法的 beam size 要设置稍大一点,论文里用 30
后两种方法叫做 LenEmb 和 LenInit,都是把目标序列的长度编码到模型中去。LenEmb 是直接把生成的标题的剩余长度嵌入到模型中,即 LSTM Decoder input 会多一个 ltlt,且每次都根据生成词的长度 byte(yt)byte(yt) 来更新 ltlt,见下图的更新公式,
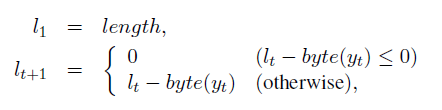
LenInit 也是把长度加到模型里去,但是只是拿来初始化 decoder,具体是用 encoder hidden state h←1h←1 来初始化 decoder LSTM hidden state s0s0,用 bc∗lengthbc∗length 来初始化 decoder LSTM memory cell m0m0,很神奇,竟然效果最好。这种方法的想实现的效果是,让模型的 memory state 自己控制长度,以便生成的句子更通顺和合理。
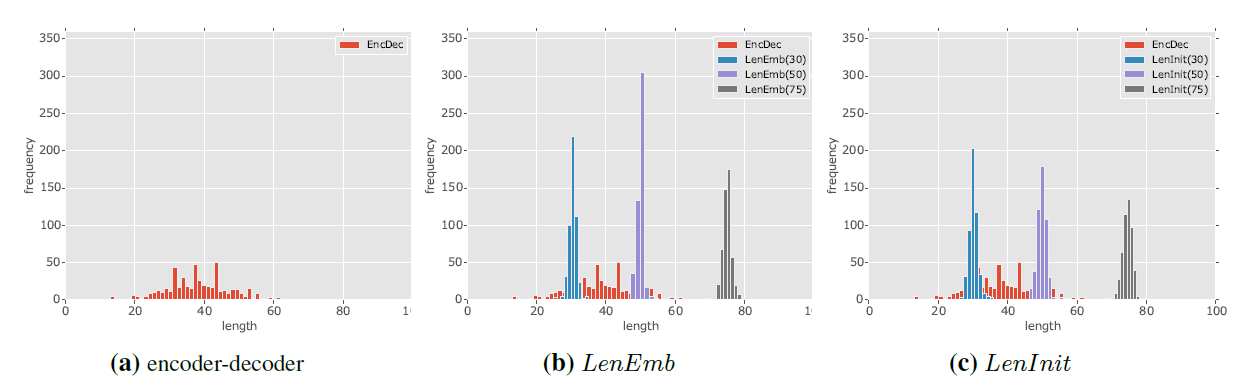
在 DUC-2004 和 Gigawords 上做了实验,后两个模型的效果明显好于前两个,但是只比 ABS 的结果好一点点,其他的模型效果都好用本篇。但是本篇论文的创新点在于能够控制生成的句子长度,而下图中的实验结果基本可以看出是符合预期的。
Read-Again
[Zeng 2016] Efficient summarization with read-again and copy mechanism
这篇论文的创新点在于提出了 Read Again 的 encoder 机制。论文的出发点是说,RNN 在编码某个词的时候,只是考虑之前所有词的情况,并不是完整的 context 信息,而双向的 RNN 得到的信息又没有做融合。因此一个朴素的想法是,先用一个 RNN 看一遍全文,得到一个全局的信息,接着再去重新读一遍原文。
具体的,提出了基于 GRU,LSTM 和 Multiple SentenceS 的三个模型。LSTM Read Again 比较简单,假如 h1i,h2ihi1,hi2 分别第 ii 时刻的第一个和第二个 LSTM hidden state,那么有
h1ih2i=LSTM1(xi,h1i−1)=LSTM2([xi,h1i,h1n],h2i−1)hi1=LSTM1(xi,hi−11)hi2=LSTM2([xi,hi1,hn1],hi−12)
因此,第二个 LSTM 在给每个词编码的时候,就有了一个全局的信息 h1nhn1,得到的语义向量就比较合理。
GRU 设计的就复杂一点,假设第一个 GRU 为 h1i=GRU1(xi,h1i−1)hi1=GRU1(xi,hi−11),那么还要先预测一个权重 αi=tanh(Weh1i+Ueh1n+Vexi)αi=tanh(Wehi1+Uehn1+Vexi) 来表示当前词的重要程度。第二个 GRU 更新的时候,就是
h2i=(1−αi)⊙h2i−1+αi⊙GRU2(xi,h2i−1)hi2=(1−αi)⊙hi−12+αi⊙GRU2(xi,hi−12)
从上面的公式可知,当 αiαi 很小时,基本就是忽略当前词 h2i−1hi−12 和 h2ihi2 差不多。如果 αiαi 很大(最大是 1),那么基本是从 GRU2GRU2 的结果。熟悉 GRU 公式就可以发现上面的 αiαi 和 GRU 的 update gate 有点像,可以把上面的公式继续展开化简,这里省去不表。
[思考,上面的 GRU 和 LSTM 设计是不是可以互通的?]
基于多个句子的 Read Again 模型,也是分别用两个 RNN 去编码句子,一个负责捕捉全局信息,另一个负责局部信息,这个有点像 Hierarchical Attention。拿两个句子 {x1,x2,...,xn}{x1,x2,...,xn} 和 {x′1,x′2,...,x′m}{x1′,x2′,...,xm′} 举例,第一层 RNN 得到两个句子编码 h1n,h1′mhn1,h′m1,那么第二层的 RNN 就是把两个包含全局信息的向量考虑进去,
h2ih′2i=RNN2([xi,h1i,h1n,h′1m],h2i−1)=RNN2([x′i,h′1i,h1n,h′1m],h′2i−1)hi2=RNN2([xi,hi1,hn1,hm′1],hi−12)hi′2=RNN2([x′i,hi′1,hn1,hm′1],h′i−12)
考虑到上面句子越多,得到的句子向越多,可以用一个全局的信息来替代,
hglobal=tanh(Wrh1n+Urh′1m)+vrhglobal=tanh(Wrhn1+Urh′m1)+vr
那么第二层的 RNN 就变成了 ,
h2i˜h′2i˜=RNN2([xi,h1i,h1n,hglobal],h2i−1)=RNN2([x′i,h′1i,h′1m,hglobal],h′2i−1)hi2~=RNN2([xi,hi1,hn1,hglobal],hi−12)hi′2~=RNN2([x′i,hi′1,hm′1,hglobal],hi−1′2)
本篇论文里的 Copy Mechanism 比较简单,应该只能算一个简单的 trick,就是作者认为 yt−1yt−1 如果是 OOV 的话,都共享同一个 UNK 的词向量有点不合适,如果这个词在 input 中出现了,可以考虑去 encoder 中找到对应的 hidden state 替代掉。
实验结果在 DUC 2004 上比前面几个模型都稍好,但是在 gigawords 上的结果却只跟 Rush 对比,有点说不过去。
CopyNet
[Gu 2016] Incorporating Copying Mechanism in Sequence-to-Sequence Learning
这篇论文是港大和华为诺亚方舟实验室的论文,也是想尝试把生成概率和拷贝概率结合起来,但是和 [Nallapati 2016] 不同,并不是非此即彼的关系,而是把两者的概率叠加起来去预测。此外拷贝概率也不是直接套用 attention,而是额外用一个网络来预测。
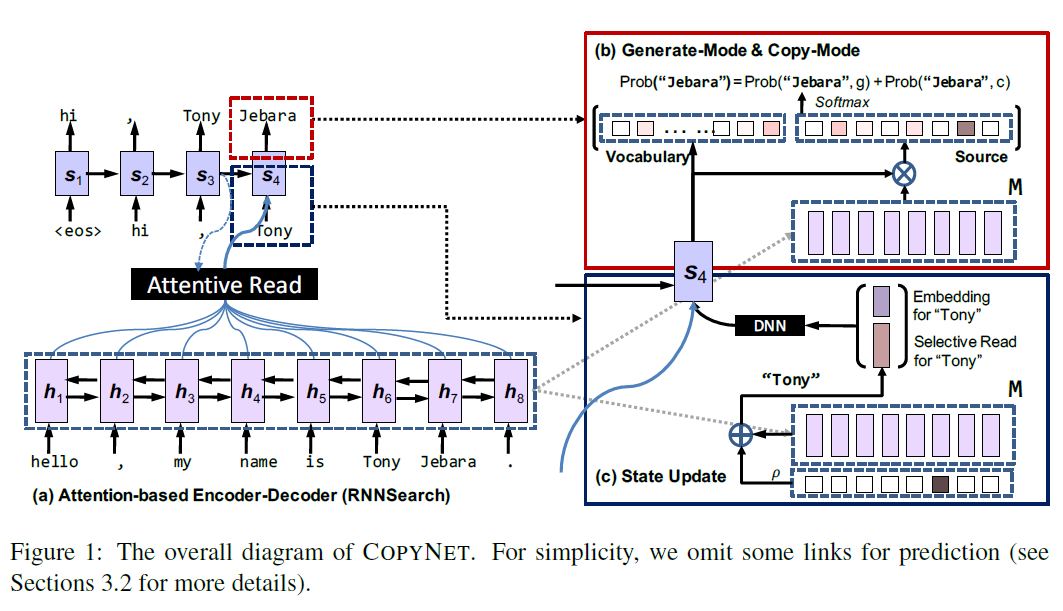
上面的图(a) 是 Attention encoder-decoder,图(b)结合生成概率和拷贝概率的部分,图(c) 则是 Read-Again 里的拷贝机制的延伸,即除了词向量,还要把对齐的 encoder hidden state 考虑进去。
参考我之前的笔记,论文阅读:CopyNet
Pointer-Generator and Coverage
[See 2017] Get To The Point: Summarization with Pointer-Generator Networks
这篇 Stanford 和 Google Brain 的论文比较新,创新点在于结合了 Pointing the unknown words 和 Modeling Coverage for Neural Machine Translation 的思想,而且提出了相应的改进方案。此外,作者的 tensorflow 源码 和 博客 都具有很好的参考意义。
首先,提出 Pointer-Generator 还是为了解决生成 OOV 和低频词的问题,这个出发点和 Pointing,CopyNet,Read-Again,RNNs and Beyond 等都是一样的。CopyNet 是把生成概率和拷贝概率直接叠加到一起;Pointing, RNNs and Beyond 则是非此即彼,没有考虑融合;而这篇论文的做法是直接用一个网络来学习这两个概率之间的权重,即在 decoder 的第 t 时刻,算一下
pgen=σ(W[h∗t,st,xt])pgen=σ(W[ht∗,st,xt])
其中 h∗tht∗ 是 context vector,stst 是 t 时刻的 decoder state,xtxt 是 t 时刻的输入。标量 pgen∈[0,1]pgen∈[0,1] 是生成概率,是一个 soft switch。当 pgenpgen 偏向 1 时,就是正常的生成,偏向 0 时,则是从 attention 概率分布 atiait 中 sample 一个对应的词。即拓展后的词概率可以这样计算,
P(w)=pgenPvocab(w)+(1−pgen)∑i:wi=watiP(w)=pgenPvocab(w)+(1−pgen)∑i:wi=wait
注意如果 w 是 OOV 的词,Pvocab(w)=0Pvocab(w)=0;同理,当 w 不在输入中时,∑i:wi=wati=0∑i:wi=wait=0
其次,提出 Coverage 机制是为了解决生成连续重复的词的问题。首先考虑把之前的 attention weight at′at′ 都加起来,得到 coverage vector
ct=∑t′=0t−1at′ct=∑t′=0t−1at′
这个向量的大小是输入序列的长度,其直观上的意义是,到 tt 时刻每个输入已经被关注的程度,注意这个虽然是概率的叠加,但是是没有归一化的。这个向量会作为一个额外输入来计算 tt 时刻第 ii 个输入的 attention 权重,
eti=vTtanh(W[hi,st,cti])eit=vTtanh(W[hi,st,cit])
这样做的出发点是,让 attention 决定 tt 时刻该去关注哪一点的时候,要先知道之前已经对哪些点关注过了,就有可能解决重复关注的问题。
但是这样还不够直接,需要额外增加一个 coverage loss 来做这个事情,
covlosst=∑imin(ati,cti)covlosst=∑imin(ait,cit)
只有 ati,ctiait,cit 都比较大的时候,这个损失函数的值才相对比较大,这个正好是重复造词时的现象,因此比较有针对性。注意这个函数是有上界的,即 covlosst≤∑iati=1covlosst≤∑iait=1,而且是希望越小越好。如果是机器翻译问题,则同时希望重复翻译和漏翻译,则需要最后时刻的 coverage loss 保持在 1 左右的范围。模型最终的 loss 可以用一个超参 λλ 来调节交叉熵和coverage loss 之间的平衡,
losst=−logP(w∗t)+λ∑imin(ati,cti)losst=−logP(wt∗)+λ∑imin(ait,cit)
关于实验,作者只在 CNN/Daily Mail 上评估,而只有 Nallapati 的两篇论文在这个上面做了完整的实验,所以只跟这两篇对比,如下,
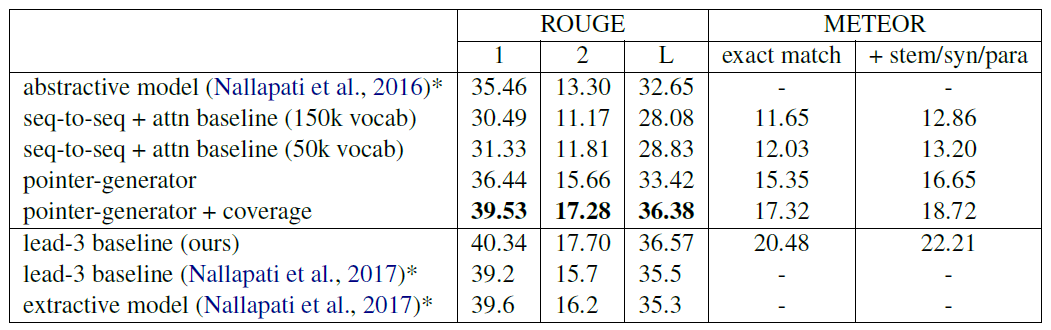
上面几行是生成式的实验结果,可以发现本篇要好于 [Nallapati 2016],即 RNN and Beyond;后面三排是抽取式的摘要,效果仍然是 state-of-art,没办法超过,作者分析可能是新闻数据集的原因,一般前三句 baseline 已经是特别好的 summarization 了,而且 rouge 这种基于词重叠度统计的标准更是加剧了这个结果。
下面两个图对模型的实验结果做了定量分析。
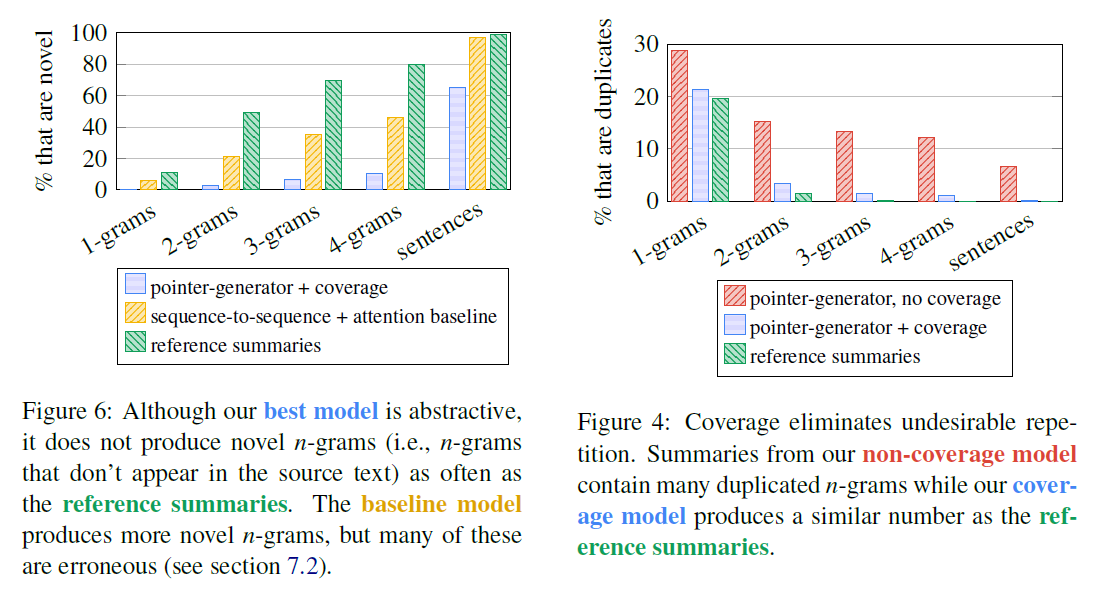
左边的图 6 是生成新词的 n-grams 统计结果,绿色的 reference 最高,黄色的 baseline 次之,最好的模型生成新词最少。可以发现完全拷贝自原文的占了 35%,而 reference 只有 1.3%,可见生成式的模型结果并不都完全是生产式。不过虽然 baseline 的新词很多,但是很多都是错的,而且包括了 UNK 词等。
右边的图 4 是生成的词里重复的占比,可以看到加了 coverage 以后的蓝色条形图,重复的情况明显减少了,基本和绿色的 reference 持平。红色的没有加 coverage 重复比较严重。