本系列博文主要介绍了在文本摘要领域神经网络模型的一些发展,主要基于如下几类模型:
- Basic Encoder-Decoder model
- Encoder-Decoder + Attention
- Deep Reinforced model
- Bert based model
- GAN based model
- Consideration
Deep Reinforced Model
NACCL 2018 《Ranking Sentences for Extractive Summarization with Reinforcement Learning》
模型的运行流程可视化:
对于抽取式摘要生成模型来说,主要任务是从源文档中抽取最可能句子组成摘要。因此一种方法是将其看作语句标注任务,对于可能出现在最终摘要的句子标注1,否则标注0。而在本文中作者将其看作是语句排序任务,然后使用ROUGE的评估结果通过强化学习进行模型的优化,排名越靠前的句子越可能出现在摘要中。
本文的主要贡献在于:
- 提出了使用强化学习进行句子排序来完成抽取式摘要生成任务
- 表明交叉熵损失并不适合摘要生成任务
- 当抽取式模型可以在全局优化的很好的时候,效果通常优于state-of-the-art的抽象式模型
假设文档 ,模型需要从中抽取 个句子组成摘要 。对于 中的每一个句子 来说,模型需要预测它的标签 ,判断它是否可能会出现在摘要中。同时使用神经网络模型计算函数 来判断当前句子和摘要的相关性,相关性越大自然得分越高。最后选择分数 最高的几个句子组成摘要 。
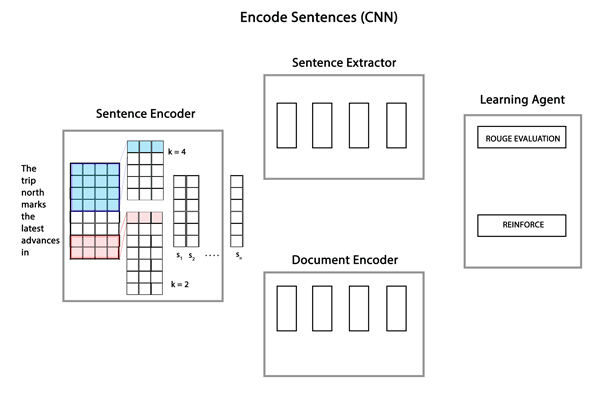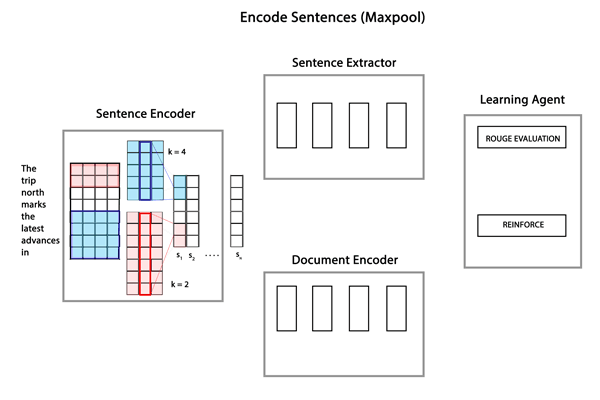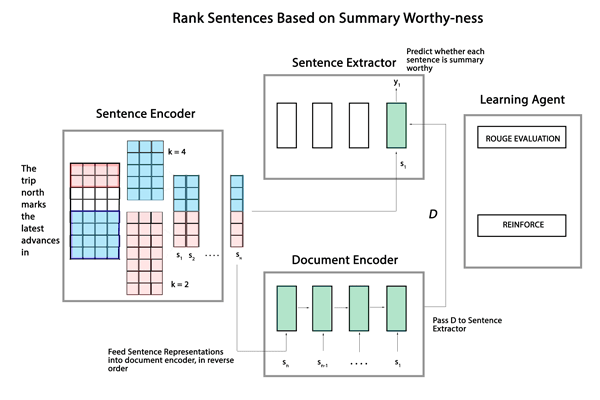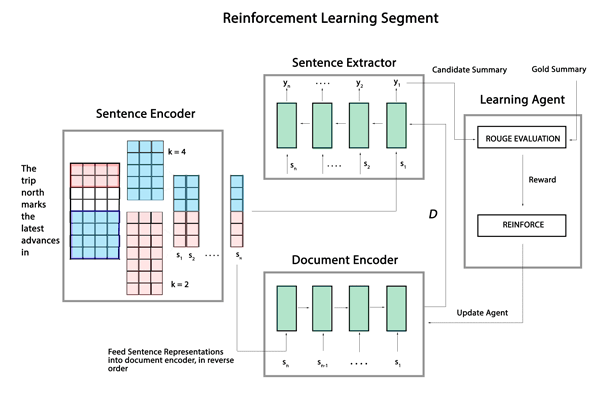
整个模型架构如下所示,主要包含sentence encoder、document encoder和sentence extractor三部分。

Sentence Encoder
它主要完成的任务是获得句子的向量表示,这里选择的是广泛使用的CNN模型,通过不同尺寸的卷积核来提取窗口中词的突出特征,池化操作使用的max-pooling-over-time。
Document Encoder
它完成的任务是通过组合一系列句子获取文档的表示,这里使用的是LSTM,这样的方式可以保证网络优先考虑对最后生成的摘要特别重要的句子。
Sentence Extractor
它根据文档中的句子与摘要的相关性为其进行标记,相关标1否则标0。这里使用的是带Softmax层的LSTM,在时刻 根据Document Encoder的结果和上一个标记的句子对当前的句子 进行标记。这样的方式可以保证Sentence Extractor可以在局部和全局都能识别出对最后的摘要重要的句子。最后每个句子的置信分数由Softmax层获得,根据分数对句子进行排序。
为什么交叉熵不适合做为排序任务的损失项?
在先前使用交叉熵的摘要模型中,模型的目标是最大化
这样的目标相当于最小化交叉熵
但是使用交叉熵训练的模型的目标和真实任务的目标存在着差异:
-
交叉熵是最大化基于真实标签的似然函数的值,而文本摘要任务是对句子进行排序生成摘要,在测试阶段使用ROUGE进行评估
-
在真实的用于训练摘要模型的数据集中并没有对于句子的标记,虽然可以通过某些方式为句子添加标注,但是会出现信息过载或是信息冗余的问题。因此作者提出直接使用强化学习来对句子进行排序,从而选择出最适合组合摘要的句子。
引入强化学习后,模型的目标函数包括两个部分:基于交叉熵的似然函数项和优化全局的ROUGE的过程中由策略梯度所给出的奖励。这样的方式有如下的优点:
- 直接优化模型的真实目标
- 更好的区分文档中的句子
ICLR 2018 《A Deep Reinforced Model for Abstractive Summarization》
基于注意力机制的Seq2Seq模型虽然可以在抽象式摘要任务上取得一定的效果,但是生成的摘要易包含重复和不连贯的短语,如何构建一个能够产生包含长连贯和有意义的摘要模型仍是一个未解决的问题。
本文中作者引入了一种带有内部注意力(intra-attention)的encoder-decoder网络模型和一种基于强化学习的训练方法,通过将标准的词预测和强化学习结合到一起,生成相关性和可读性更好的长文本摘要。

为了使模型输出的摘要更加的连贯,这里允许decoder在生成新词时回顾部分的输入文档,这种方式可称为基于时间的注意力机制(temporal attention)。与完全依赖自己的隐状态不同,decoder通过注意力函数(attention function)整合了不同部分输入的上下文信息,再通过调整注意力函数,确保模型在生成摘要时使用不同部分的输入,从而增加摘要的信息覆盖率。
同时为了使模型不产生重复信息,这里允许模型回顾decoder之前的隐状态,同样的定义内部解码注意力函数(intra-decoder attention function),它可以回顾decoder之前的隐状态。最后decoder将来自时间注意力模型的上下文向量和来自内部解码注意力函数的上下文向量进行结合,在输出摘要中生成下一个词。

模型中应用了两种注意力机制:
- 经典的 encoder-decoder注意力机制:它使decoder在生成结果时能动态的、按需求的获得输入端的信息
- decoder内部的注意力机制:它使模型能关注到已生成的词,帮助解决生成长句子时容易重复同意词句的问题
Encoder部分使用的是双向LSTM,decoder使用单向LSTM,输入和输出的嵌入矩阵都使用 ,以及使用encoder最后隐状态的值来初始化decoder的起始状态。
那么如何训练模型呢?一种方法是借鉴机器翻译(machine translation,MT)中的Teacher-forcing:在模型生成摘要时使用参考摘要(reference summary),且模型在每生成一个新词时会被分配一个逐词误差(word-by-word error),或称为局部监督(local supervision)。

Teacher-forcing方法在MT中可以取得不错的效果,但是在文本摘要领域,好的摘要并不需要逐词的匹配参考摘要。对于同一个文档来说,不同的人会给出表述的摘要,但是它们有可能都是高质量的。teacher-forcing方法的不足在于:
- exposure bias:在训练阶段模型可以看到参考摘要,但是在测试阶段数据集并不会提供对应的参考摘要,那么当在某一时刻出错后,错误就会在随后的过程中不断累积
- 它无法适应一个可能更好但开始的词的序列和参考不同的摘要:尽管有不同的方法来对token进行排序生成更好的摘要,但是teacher-forcing方法迫使模型生成的摘要只能接近于参考摘要
因此作者这里选择了使用强化学习的方式进行模型的训练,首先允许模型生成完整的摘要,然后再使用外部的评分器来比较生成的摘要和正确的摘要。如何得分很高,表示模型这样的生成方式接近真实的情况,对模型进行更新;反之如果分数很低,模型将受到惩罚,并改变其生成过程防止生成类似的摘要。通过这样的训练方式,可以保证模型得出用于评估整个输出序列而不是逐词预测的分数。

传统的对于生成的摘要好坏的评估常采用ROUGE,它通过对比生成摘要和参考摘要中的子短语来计算分数,即使子短语并不完全一致,不同的ROUGE的变种也可以使用相同的方式操作。但是ROUGE分数高的句子不一定符合要求的,如果选择ROUGE分数高的句子来生成摘要,最后可能得到的是可读性很差的摘要。
因此,模型最终的训练目标时最大似然和基于ROUGE指标函数的加权平均,最大似然承担了建立好的语言模型的责任,它使模型生成语法正确、文字流畅的摘要;ROUGE指标降低了RNN中的暴露偏差(exposure bias),它允许摘要具有更多的灵活性,同时针对ROUGE的优化也直接提升了模型的ROUGE评分。
训练过程同时使用了teacher-forcing和强化学习,这样能够利用词级和整个摘要层面的监督信息,使得生成的摘要具有连贯性和可读性。特别是基于ROUGE优化的强化学习有助于改善回调,并且基于词级学习的监督信息能够确保摘要的流畅性和可读性。
其中
表示使用强化学习的损失函数,
表示似然函数损失,
为尺度因子,控制两者的相对重要性。

此外作者还使用了如下的技巧:
- 使用pointer解决OOV问题
- 共享decoder的权重,加速模型的收敛
- 根据对于CNN/Daily Mail数据集的观察,规定decoder在测试阶段不能输出同样的trigram
实验证明了采用监督学习+强化学习的方式生成的摘要具有较高的可读性,并且在只使用强化学习时也可以获得较高的ROUGE分数。

输出样例

Pretrained Language Model Based Model
arXiv 2019 《Fine-tune BERT for Extractive Summarization》
预训练模型的出现极大的提升了各种NLP任务的效果,例如阅读理解、自动推理、问答系统等。那么能否将其和摘要生成结合起来呢,作者在本文中给出了一种思路。
作者将BERT应用于抽取式摘要生成任务,提出了BERT的变体BERTSUM,并在CNN/Daily mail数据集上提升了ROUGE-L的评估值。
对于抽取式摘要生成来说,可以将文档 看做是很多句子的集合 ,它所要做的就是判断每个句子 是否应该出现在生成的摘要中,对于单个句子来说是一个二分类的问题。
尽管BERT可以为输入的句子生成一个表示,但是它最后输出的是token,而不是完整的句子;另外尽管BERT有着分割嵌入(segmentation embedding)来指示是属于句子A还是B,但是它也只有两个标签。因此为了更好的使用完成的任务,作者对于输入序列和BERT的embedding机制进行了修改,提出了下面所示的架构方式:

BERTSUM
为了处理文档中的多个句子,作者使用[CLS]和[SEP]做为不同句子间的分隔记号,同时提出了Interval Segment Embeddings机制来区分文档中的不同句子。对于 来说,当 为奇数时,标记为 ;当 为偶数时标记为 。另外BERT顶端的 可以作为 的表示,用于下游的处理。
在得到了不同的
的表示
后,作者这里添加了Summarization Layers来捕获文档级别的特征用于后续的摘要生成。对于每个
预测它的得分
,然后和真实标记
比较,使用交叉熵进行参数更新。
除了使用分类器外,还可以使用Inter-sentence Transformer来从BERT的输出中捕获文档级别的特征用于摘要生成。
其中MHAtt表示多头注意力操作,LN表示层归一化(layer normalization)操作。同样将最后的输入送到sigmoid层中得到
经过实验发现当使用两层的Transformer时模型效果最佳。
另一种方式是使用LSTM,它的输入就是BERT的输出
,计算如下:
其中
表示遗忘门、输入门和输出门的输出,
表示隐状态向量,
vi表示记忆单元向量,
表示不同层的层归一化操作。最后使用sigmoid层计算
。
实验结果如下,前面的为比较的基准模型,最下面的四个为作者提出的不同的结合方式,可以看出BERTSUM+Transformer的模型效果最佳。

更多实验细节可见原论文。
arXiv 2019《Pretained-Based Natural Language Generation for Text Summarization》
《Fine-tune BERT for Extractive Summarization》主要是针对于抽取式摘要生成任务,主要的工作在于如何为句子进行打分,从而选择出得分较高的句子组成摘要。而本文也是使用BERT来完成文本摘要,不过针对的抽象式摘要生成任务。作者认为,在此之前的各种模型在decoder阶段只是利用了上文信息,并没有很好的利用下文信息;由于RNN的限制,decoder难以学习到语法等高级的语义信息。
作者在本文中依然使用encoder-decoder的模型架构,encoder阶段使用BERT来学习输入序列的表示;decoder阶段采用两阶段的方式:
- 首先使用基于transformer的decoder生成一个粗略的摘要,文中称为draft summary
- 然后将draft summary中的每个位置的词依次mask掉,使用BERT强大的上下文学习能力来进行预测,从而寻找更合适的替代词,最后生成更好的摘要
经过实验证明了模型可以在CNN/Daily Mail和NYT两个数据集上实现SOTA。
假设将输入文档记为 ,对应的摘要记为 ,encoder 学到的表示向量为 ,生成的draft summary为 。

Encoder
它主要是使用BERT得到文档的表示向量(Document Embedding)。
Decoder
首先使用基于transformer的decoder生成一个粗略的摘要,基本方式是根据已生成的部分和
来预测下一个词,计算概率
,对应的损失函数为
作者指出,使用transformer依然无法很好的学习到上下文信息,但如果直接将不完整的语句输入到BERT中预测context vector,反而会损失BERT的效果。另外如果只使用在这里使用BERT的嵌入矩阵,将会导致transformer的参数更新困难,不宜学习好的表示。
在得到 之后,首先将 中的每个词分别mask,得到 ;将其输入到BERT中得到draft summary的embedding。将学到的embedding输入到基于transformer的decoder中,预测该mask的词为真实摘要中词的概率,最后生成最终的摘要。
在第一个decoder阶段,并不是在等生成完整的draft summary后再进入下一个阶段,而是边生成边将结果作为下一个阶段的输入。
最终的损失函数为:
这里的decoder和第一步中的decoder是参数共享的,因为作者发现使用新的decoder会造成效果的下降。
为了提升模型的效果,这里同样使用了基于强化学习的损失函数
模型最终的目标函数为
另外为了解决OOV问题,这里同样使用了copy机制。
实验结果如下

从中可以看出,相比于基准模型,BERT的使用和两阶段的decoder确实可以在一定程度上提升效果,但是相比于先前的模型提升并不显著。特别是相比于lead-3来看,提升并不大。通过消融实验也可以看出基于RL的训练目标可以提升模型效果,不过这在其他的模型中已有证实。

在关于序列长度的实验中可以看出:当真实摘要过长时,模型的效果变差,作者认为是因为在生成摘要时,对于长文档和golden summary的截断,导致无法获得完整的上下文信息。
Tricks
- Beam search中当预测词出现重复的trigram时,将该词的概率置零,解决词重复问题
- 当出现多句相同的摘要时仅使用第一个
- 去除小于3个词的句子
整体来看,虽然使用了BERT和Transformer,但模型在抽象式摘要生成任务中并没有太大的提升,这值得思考。
在整个过程中参考了很多网上的资料,由于忘记保存链接,这里就给出参考资料地址了,衷心感谢他人的付出~
