摘要
在神经生成式摘要中,常规的序列到序列(seq2seq)模型经常会遇到生成重复和语义无关摘要的问题。为了解决该问题,我们提出了一种全局编码框架,该框架基于源上下文的全局信息来控制从编码器到解码器的信息流。它由卷积门控单元组成,以执行全局编码以改善源端信息的表示形式。对LCSTS和英语Gigaword的评估均表明我们的模型优于基准模型,并且分析表明我们的模型能够生成更高质量的摘要并减少重复。
1.介绍

生成式摘要可以视为序列映射任务,即源文本应映射到目标摘要。因此,序列到序列学习可以应用于神经生成式摘要,其模型由编码器和解码器组成。注意力机制已广泛用于seq2seq模型中,其中解码器基于源端信息的注意力分数从编码器提取信息。最近,已经提出了许多基于注意力的seq2seq模型用于生成式摘要,这要明显优于传统的统计方法。
但是,最近的研究表明,注意力机制存在明显的问题。Zhou et al. (2017) 指出,源文本和目标摘要之间没有明显的对齐关系,并且对于注意力来说,编码器输出中包含噪声。例如,在表1的seq2seq生成的摘要中,“officially”后跟相同的单词,因为注意力机制仍然关注具有高注意力得分的单词。用于生成式摘要的基于注意力的seq2seq模型可能会遇到重复和语义不相关的问题,从而导致语法错误和对源文本的主要语义的反映不足。
为了解决这个问题,我们提出了一种用于生成式摘要的全局编码模型。我们设置一个卷积门控单元以对源上下文执行全局编码。由于参数共享,基于卷积神经网络(CNN)的门根据全局上下文对每个编码器输出进行过滤,因此,在考虑全局上下文的情况下,可以改进每个时间步长的表示。我们在LCSTS和Gigaword这两个用于句子摘要的基准数据集上进行了实验,这表明我们的模型在ROUGE-2 F1得分分别为26.8和17.8方面优于最新技术。此外,分析表明,与seq2seq模型相比,我们的模型能够减少重复。
2.全局编码
我们的模型基于具有注意力的seq2seq模型。对于编码器,我们为全局编码设置了卷积门控单元。基于RNN编码器的输出,全局编码使用CNN改进源上下文的表示,以改善单词表示与全局上下文的连接。在下文中,我们详细介绍了这些技术。
2.1 基于注意力的seq2seq
RNN编码器从源文本顺序接收每个单词的单词嵌入。具有整个源文本的信息的最终隐藏状态成为解码器的初始隐藏状态。其中,我们的编码器是双向LSTM编码器,其中每个时刻上两个方向的编码器输出都是串联起来的 ( h i = [ h → i ; h ← i ] ) (h_i=[\overrightarrow h_i;\overleftarrow h_i]) (hi=[hi;hi])。
我们实现了一个单向LSTM解码器,通过将固定的目标词汇嵌入到高维空间 Y ∈ R ∣ Y ∣ × d i m Y∈\mathcal R^{|Y|×dim} Y∈R∣Y∣×dim中,来读取输入的单词并逐字生成摘要。在每个时刻,解码器通过从目标词汇表的分布 P v o c a b P_{vocab} Pvocab中采样来生成摘要词 y t y_t yt,当出现表示句子结尾的字符则停止采样。利用权重矩阵 W a W_a Wa计算解码器 s t s_t st和每个时刻 i i i的编码器输出的隐藏状态 h i h_i hi,以获得全局注意力得分 α t , i α_{t,i} αt,i和上下文向量 c t c_t ct。计算描述如下:
P v o c a b = s o f t m a x ( g ( [ c t ; s t ] ) ) (1) P_{vocab}=softmax(g([c_t;s_t]))\tag{1} Pvocab=softmax(g([ct;st]))(1)
s t = L S T M ( y t − 1 , s t − 1 , C t − 1 ) (2) s_t=LSTM(y_{t-1},s_{t-1},C_{t-1})\tag{2} st=LSTM(yt−1,st−1,Ct−1)(2)
c t = ∑ i = 1 n α t , i h i (3) c_t=\sum^n_{i=1}\alpha_{t,i}h_i\tag{3} ct=i=1∑nαt,ihi(3)
α t , i = e x p ( e t , i ) ∑ j = 1 n e x p ( e t , j ) (4) \alpha_{t,i}=\frac{exp(e_{t,i})}{\sum^n_{j=1}exp(e_{t,j})}\tag{4} αt,i=∑j=1nexp(et,j)exp(et,i)(4)
e t , i = s t − 1 T W a h i (5) e_{t,i}=s^T_{t-1}W_ah_i\tag{5} et,i=st−1TWahi(5)
其中 C C C表示LSTM中的单元状态,而 g ( ⋅ ) g(·) g(⋅)表示非线性函数。
2.2 卷积门控单元
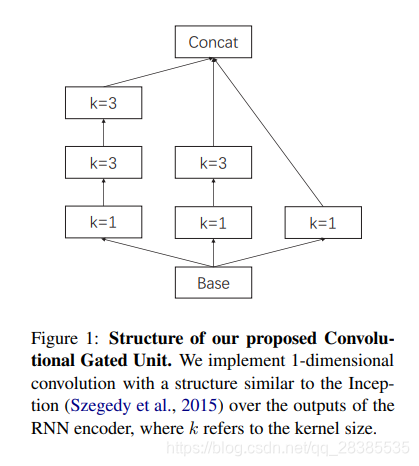
生成式摘要需要每个编码时刻的核心信息。为了达到这个目标,我们在编码器输出每个时刻的顶部实现了门控单元,即一个CNN,可以对所有编码器输出进行卷积。卷积核的参数共享使模型能够提取某些类型的特征,特别是n-gram特征。与图像相似,语言也包含局部相关性,例如短语结构的内部相关性。卷积单元可以提取句子中的这些共同特征,并表示源语义之间的相关性。此外,为了进一步加强全局信息,我们使用了self-attention,以在特定时刻挖掘当前语义与其他语义之间的关系。因此,门控单元既可以找到常见的n-gram特征,又可以找到全局相关性。基于卷积和自注意力,门控单元设置门以过滤来自RNN编码器的源语义,以便选择与全局语义相关的信息。全局编码允许编码器在每个时刻的输出成为新的表示向量,并进一步连接到全局源辅助信息。对于卷积,我们实现了与(Szegedy et al., 2015) 相似的结构。我们使用一维卷积提取n-gram语法特征。按照初始的设计原则,我们不使用 k = 5 k=5 k=5的核,而是使用两个 k = 3 k=3 k=3的核来避免较大的内核。卷积块的详细信息如下:
g i = R e L U ( W [ h i − k / 2 , . . . , h i + k / 2 ] + b ) (6) g_i=ReLU(W[h_{i-k/2},...,h_{i+k/2}]+b)\tag{6} gi=ReLU(W[hi−k/2,...,hi+k/2]+b)(6)
其中,ReLU是指Rectified Linear Unit这一非线性激活函数。在卷积块的基础上,我们实现了类似于inception的结构,如图1所示。
在CNN模块生成新表示形式的基础上,我们进一步对这些表示形式进行self-attention,以挖掘出全局相关性。Vaswani et al. (2017) 指出,自注意力鼓励模型学习长期依赖关系,并且不会产生太多的计算复杂性,因此我们针对每个时刻的语义与全局信息之间的连接实现了缩放点积注意力:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V (7) Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V\tag{7} Attention(Q,K,V)=softmax(dkQKT)V(7)
其中,我们将 Q Q Q和 V V V作为CNN模块生成的表示矩阵,而 K = W a t t V K=W_{att}V K=WattV,其中 W a t t W_{att} Watt是可学习的矩阵。
接下来,基于CNN的生成结果和自注意模块g为RNN编码器的源表示 h ′ h' h′设置一个门,其中:
h ~ = h ⋅ σ ( g ) (8) \tilde h=h\cdot \sigma(g)\tag{8} h~=h⋅σ(g)(8)
由于CNN模块可以提取整个源文本的n-gram语法特征,并且自注意力能够学习输入源文本的各个组成部分之间的长距离依赖性,因此门可以对编码器输出执行全局编码。基于CNN的输出和自注意力,sigmoid函数在每个维度上输出一个介于0和1之间的值的向量。如果该值接近0,则门将在源表示形式的相应维度上删除大部分信息,如果该值接近1,则将保留大部分信息。
2.3 训练
接下来,我们介绍进行实验的数据集以及实验设置。
给定参数 θ θ θ和源文本 x x x,模型生成摘要 y ~ \tilde y y~。学习过程是最小化生成的摘要 y ~ \tilde y y~和参考摘要 y y y之间的负对数似然:
L = − 1 N ∑ n = 1 N ∑ t = 1 T p ( t t ( n ) ∣ y ~ < t ( n ) , x ( n ) , θ ) (9) \mathcal L=-\frac{1}{N}\sum^N_{n=1}\sum^T_{t=1}p(t^{(n)}_t|\tilde y^{(n)}_{\lt t},x^{(n)},\theta)\tag{9} L=−N1n=1∑Nt=1∑Tp(tt(n)∣y~<t(n),x(n),θ)(9)
其中损失函数等于在给定参数 θ θ θ和源序列 x x x的情况下最大化摘要 y y y的条件概率。