文章目录
- ACL 2018 [《Retrieve,Rerank and Rewrite: Soft Template Based Neural Summarization》](https://www.aclweb.org/anthology/P18-1015)
- ACL 2019 [BiSET: Bi-directional Selective Encoding with Template for Abstractive Summarization](https://arxiv.org/abs/1906.05012)
- ACL 2019 [Generating Summaries with Topic Templates and Structured Convolutional Decoders](https://www.aclweb.org/anthology/P19-1504)
ACL 2018 《Retrieve,Rerank and Rewrite: Soft Template Based Neural Summarization》
github[原文中给的已失效,网上也没有找到源码 ]

传统上基于Seq2Seq的摘要生成模型尽管可以得到较高的ROUGE,但是得到的摘要仍存在着很多问题:
- 模型生成的摘要过短,有3%的摘要包含的词少于3个
- 随着摘要长度的增加,生成性能急剧恶化,即无法生成较长的摘要,这也是使用RNN的一个不足
- 摘要中重复的词较多,尽管可以使用coverage机制缓解这个问题,但是和ground-truth还是有差距
- 模型更侧重于大量复制原文中的部分,而ground-truth中的比例要少的多
因此直接使用Seq2Seq模型从源文档中生成摘要并不能达到让人满意的效果。既然无法直接从源文档中生成高质量的摘要,那么我们是否可以借助外部的一些信息来帮助更好的生成摘要呢?本文作者提出了一种巧妙的思路:寻找与所处理文档的文档中句子相似的其他的文档,然后使用它们的摘要作为一种“软模版”,根据软模板所提供一些信息来帮助生成过程。
2004 ACL上的《Template-filtered headline summarization》一文首先提出了使用模板来帮助生成摘要,但那时主要依赖于人工来构建规则、建立模板,这样的方式有很多缺陷:
- 构建模板需要耗费大量的人力、物力
- 需要丰富的专业领域知识
- 构建所有领域的模板是不现实的
随着深度学习的兴起,使用神经网络从大规模的语料库中自动的发现一些规则,从而来帮助生成过程成为了可能。根据作者的思想,本文所提出的模型 主要分为三大部分:Retrieve、Rerank和Rewrite。

Retrieve
作者认为,相似的句子所组成的文档的摘要应该具有相似的模式。因此对于给定处理的文档 ,首先使用检索系统(这里使用的是Lucene)从语料库中找到与它相似的文档集,然后将它们的模板作为候选模板 (这里候选模板集的大小为30)。
Rerank and Rewrite

Rerank和rewrite这里是同时进行训练的,首先使用BiRNN来得到
和
的表示向量,每一个词的表示是双向表示的拼接
、
,最后源文档和模板的表示分别为:
在retrieve这一步中,候选模板是根据源文档的句子和语料库中其他文档句子间的相似度选择的,但是我们的目标是希望候选模板和真实摘要越相似越好,因此仅依靠基本的相似度度量是不够的。这里使用ROUGE来定义函数
来计算模板和真实摘要的ROUGE值,然后根据ROUGE结果来对其进行重排序。
上一步得到关于文档和模板的隐状态后,使用Bilinear Network来预测模板的显著性(saliency)
经过rerank得到的候选模板在ROUGE上已经可以得到较高的分数,但是它并没有很好的表述源文档的具体内容,以及会出出现很多源文档中不存在的命名实体,因此这里还需要根据源文档对其进行重写(rewrite)。
在rewrite阶段,将模板
的表示和源文档
的表示进行拼接,得到
然后将得到的表示向量输入到基于注意力的RNN中进行解码,得到每个位置
上的隐状态
最后使用softmax来预测摘要中当前时刻的词
training
在Rerank阶段我们希望
接近于
,因此损失函数使用了交叉熵
在Rewrite阶段目标是最大化生成的词的概率,这和语言模型的目标是一致的,因此同样使用最大化负对数似然的方式
experiment
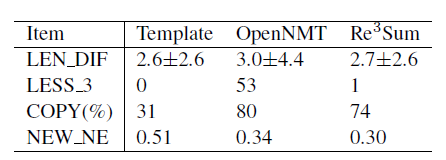
实验中所使用的语料库为Annotated English Gigaword,评估指标为通用的ROUGE,它只是评估了摘要中的信息量。因此,作者又设计了其他的一些评价指标:
- LEN_DIF:表示真实摘要和生成摘要长度差的绝对值,这里使用了绝对值+标准差的方式
- LESS_3:包含少于3个词的摘要数量
- COPY:摘要中直接从源文档中进行复制的比例
- NEW_NE:未出现在源文档和真实摘要中的命名实体的数量
相比较的基准模型有ABS+、RAS-Elman、Featseq2seq、Luong-NMT、OPenNMT和FTSum。
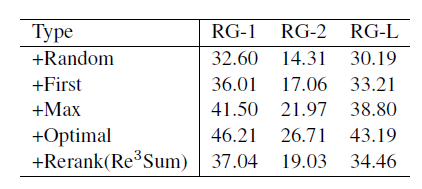
从ROUGE值来看, 在RG-2和RG-L上都可以取得更好的结果。

为了评估直接将模板作为摘要输出的效果,作者使用了Random、Frist、Max、Optimal和Rerank五种方式,从实验结果中可以看出自然Optimal的效果更好,Random根本没有效果,其他的方式已经可以取得较好的结果。
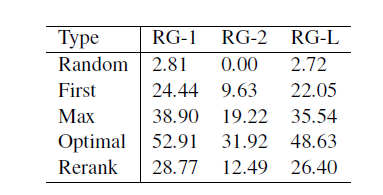
在比较Template、OpenNMT和 在新设计的指标上的实验结果如下所示,从中可以看出 在除COPY外效果都优于其他的方法,但也从中给可以看出 相比于Template还是很依赖与从源文档中直接复制内容。另外在NEW_NE一项中 的值接近于OPenNMT,显示了模型的重写能力,并不是完全的依赖于模板。
在关于引入模板来指导摘要生成的实验结果中,我们可以看出高质量的模板可以得到高的ROUGE值,而且 可以自动的判断模板是否可信,并会舍弃掉不相关的模板。
另外从生成的摘要的多样性上也可以看出 效果更好

ACL 2019 BiSET: Bi-directional Selective Encoding with Template for Abstractive Summarization

在文本摘要生成任务存在很多的数据集,但是数据集中的数据不一定都是对于最终的摘要生成有用。因此如何设计一种类似过滤器的机制来从中选择出更好的训练数据,从而帮助模型生成质量更好的摘要。
作者在本文中提出了基于模板的双向选择编码模型(Bi-directional Selective Encoding with Template (BiSET) model),通过模板从源文档中发现关键信息来指导摘要生成。
基于模板的摘要生成最初依赖于由领域专家手造的模板,但是随着数据集规模的增大,这样的方式变得不太现实。如何从数据集中生成模板或者使用某些信息作为“模板”来指导生成过程,这成为了一个亟待解决的问题。
在《Retrieve, rerank and rewrite: Soft template based neural summarization》中,作者将所选模板的表示直接和源文档的表示进行简单的拼接来帮助摘要的生成,但这样的方式并不能很好的利用模板所带来的信息。
因此作者提出了一种新的双向选择层,通过两个门(template-to-article,T2A和article-to-templete,A2T)来互助的从源文档中提取关键信息。另外作者还提出了一种新的多阶段过程来实现从语料库中自动的提取高质量模板的方法。
整个模型流程可以分为三大步:
- Retrieve:使用IR中的检索方法来语料库中寻找和所处理的原文档相关的几篇文档,将它们的摘要作为候选模板
- Fast Rerank:对后续模板进行重排序,根据选择策略从中选出最好的来作为最终的模板
- BiSET:使用得到的模板来指导摘要的生成
Retrieve
这一步相当于实现源文档和语料库中的其他文档进行相似度度量,从而选择最相似的 篇文档。
这里的检索机制和《Retrieve, rerank and rewrite: Soft template based neural summarization》中所使用的一致。
Fast Rerank
作者指出前一步的检索的结果只是简单的使用词匹配(word match)得到,它并没有很好的探究源文档和结果中其他文档的摘要深层语义上的联系,因此这一步设计了一个Fast Rerank Model来根据语义相似性进行重排。重排模型主要包含:
- Convolution Encoder Block
- Similirity Matrix
- Pooling Layer
在卷积编码块中并没有使用传统的RNN或是CNN,作者认为候选模板和源文档在长度上存在着很大的差异,简单的使用RNN或CNN得到的排序结果并不能捕获语义上的联系。因此这里设计了一个包含1D卷积+非线性激活层+残差连接层的新的编码模块。

首先将article和template经过嵌入层得到两者的表示向量
,然后使用1D卷积层来提出n-gram特征
再将提取到的特征通过gated linear unit(GLU)来减小特征的维度以及控制信息传递的比例。
为了不丢失输入的信息,这里使用了残差连接:
。
接着将GLU的输出作为相似度度量矩阵 的输入 ,其中向量间的相似度度量方式常用的有如下的几种:
- dot product:
- bilinear function:
- Eucliden distance:
这里使用的是Eucliden distance。
pooling layer过滤掉不重要的信息,同时减少处理的信息量,这也和池化操作的本质是一致的。因为在源文档中存在着很多重复的词,这里只想对其进行一次计数,因此这里定义了一个函数
来从
中选出一些显著的权重
然后对
使用k-max pooling选择
个最重要的权重。最后使用全连接层输出原文档和候选模板间的相似度得分。
在经过前两个步骤得到最优模板后,就需要考虑如何利用它所提供的信息来帮助生成过程。
首先需要得到关于源文档和模板的向量表示,传统上的模型的encoder常使用Bi-LSTM来获取表示向量,分别记为 和 。
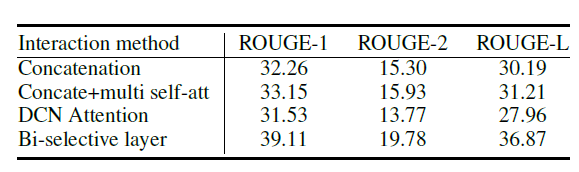
对于两者的结合方式,文中提了之前的三种:
-
Concatenation:直接将 拼接到 后面组成新的文档表示
-
Concatenation + Self-Attention:引入了多头注意力机制
-
DCN Attention:首先计算一个相似度矩阵 ,其中的每一个元素 , 表示拼接操作,这样就得到了文档和每一个模板之间的相似度得分。接着使用softmax分别按行和按列归一化元素,得到两个新的矩阵 和 。
使用DCN计算双向的注意力:
最后得到文档的表示 。
BiSET
BiSET是作者所提出的一种新的信息结合模块。

它的主要思想在于使用模板来帮助文档的表示和摘要的生成。模块主要包含两个门template-to-article(T2A)和article-to-template(A2T)两个门。T2A用来过滤源文档的表示 。A2T用来控制 在最终的文档表示中所占的比例。
使用
和
来计算置信分数
文档的最终表示是
和
的线性插值形式
decoder使用RNN来生成摘要。
Training
在Fast Rerank阶段使用ROUGE-1的值来作为评估指标,对应的损失函数为
BiSET的损失函数为
目标是使生成的摘要接近于人写的摘要。
实验
数据集为Gigaword,从下图中可以看出,当候选模板的数量增多时,各个阶段的效果都有提升。

下图表示了Bi-selective layer的效果,可以看出它优于传统的三种方法。
下图表示和其他抽象式模型的效果对比,可以看出BiSET的效果更好一些。

消融实验中可以看出T2A比A2T更加的重要。
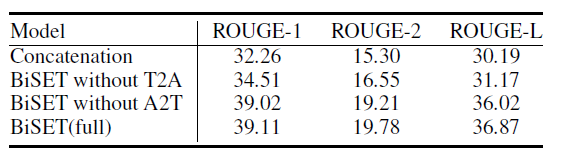
人工评断结果中也可以看出BiSET确实有一定的效果。

ACL 2019 Generating Summaries with Topic Templates and Structured Convolutional Decoders
本文提出了一种新的基于目标摘要内容的结构化卷积解码器(structured convolutional decoder),并在多个不同域的数据集上实验,证明了所提出的模型具有更好的内容覆盖率。
在针对不同领域的文档进行摘要生成时,由于不同的领域的内容具有不同的表述顺序,因此我们可以在生成摘要前先识别文档所在的主题域,然后根据不同域的摘要结构来指导生成过程。这样通过引入外部的指导信息来帮助更好的把握文档的关键信息和主要结构,使得到的摘要更加符合主题特点。
因此作者提出了一种新的解码器,使得模型在生成摘要时可以知道每一句话所涉及的主题,以及它们在目标摘要中的位置。这样一个明确考虑了目标摘要内容结构的解码器可以生成更好的摘要,并在一定程度上缓解传统模型的结果一般化、相关性差等问题。
另外作者从WikiSUM中抽取部分内容得到了一个适合本文内容的数据集WIKICATSUM,它的文档主要分布在namely Companies、Films和Animals三个域。
对于不同域文档的建模过程基于如下的假设:
- 不同域的文档应包含不同的主题和实体
- 对于不同实体存在着不同形式的摘要
因此这里将特定域的段落簇作为多文档摘要生成模型的输入,将Wikipedia的lead section 部分作为目标摘要。通过从各自域的多文档中提取主题模板来指导摘要生成过程。

为了方便处理,这里将输入的多个有序段落 拼接为一个向量 ,目标输出为多个句子序列组成的摘要。
模型整体上基于卷积神经网络的Encoder-Decoder结构,首先通过CNN encoder得到输入的隐状态表示 ;再使用层次化的decoder生成目标摘要。其中decoder包含两个层级:
- document-level decoder:基于LSTM,目标是生成句子向量来表示句子的内容规范
- sentence-level decoder:基于CNN,目标是具体生成每一个词组成最后的结果

在document-level decoder阶段,使用基于注意力的LSTM在每个时刻得到状态
来输入
时刻的隐状态
。
其中
表示上下文向量,它由注意力机制计算而得。
上一步得到的隐状态只是表示了目标摘要中句子应满足的规范,并没有具体的相关内容。因此需要sentence-level decoder逐词的生成最终的摘要。在decoder的每个时刻
词的表示为
,其中
表示时刻
目标摘要
位置的目标词,
表示词是否在目标句中,
表示句子在目标摘要中的位置。
与使用RNN作为decoder不同,作者在本文中使用
来扩展多步注意力(multi-step attention)机制,decoder每一层
的输出向量为
最后根据概率
得到目标词。
同时为了使得decoder感知主题,这里使用LDA为每个句子分配一个主题标签,然后训练document-level decoder去预测它,将其作为一个辅助的任务。
其中
表示第
个主题的表示向量。
从实验结果中可以看出结构化的decoder和附加的主题标签预测任务可以在一些域上得到效果的提升,但总体来说并不大。

其中TF-S2S表示基于Transformer的Seq2Seq模型,CV-S2S表示基于卷积网络的Seq2Seq模型模型,CV-S2D是作者提出的模型,+T 表示附加的主题预测任务。
