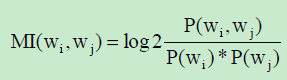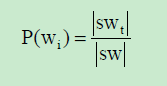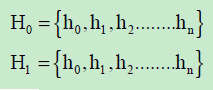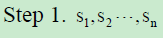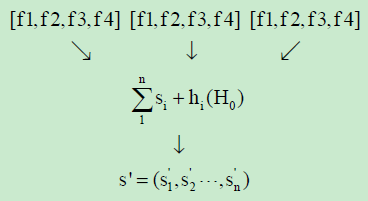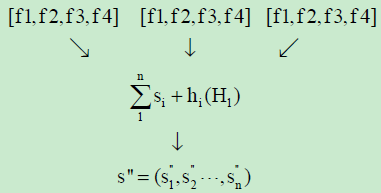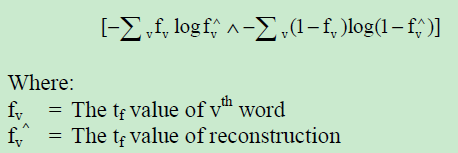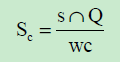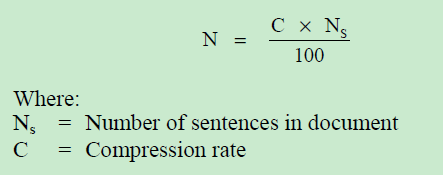Padmapriya G, Duraiswamy K. AN APPROACH FOR TEXT SUMMARIZATION USING DEEP LEARNING ALGORITHM[J]. Journal of Computer Science, 2014, 10(1):1-9.
##Abstract
RBM被广泛应用,限制玻尔兹曼机
对三种不同知识领域的文档进行了实验
基于RBM
##Introduction
- Developed a multi-document summarization system using deep learning algorithm Restricted Boltzmann Machine (RBM).
- Solving the ranking problem by finding out the intersection between
the user query and a particular sentence - Sentences are selected on the basis of compression rate entered by the user.
##Motivation
信息爆炸,从大量信息中找到我们需要的信息很有必要,做摘要是快速获取信息的一个重要途径
##Model
-Restricted Boltzman Machine
Restricted Boltzmann Machine is a stochastic neural network (that is a network of neurons where each neuron has some random behavior when activated).
这是一个随机的网络,二分图——这意味着信息在训练期间和网络使用期间都在两个方向流动,并且这两个方向的权重是相同的
##Term weight
见A survey of document summarition
##Concept feature
where, P(wi, wj)-joint probability that both keyword
appeared together in a text window.
P(wi)-probability that a keyword wi appears in a text
window and can be computed by:
Where:
swi = The number of windows containing the keyword
wi
|sw| = Total number of windows constructed from a text document
The sentence matrix generate by above steps is:
Here sentence matrix S = (s1, s2,………sn) where si = (f1, f2,………f4), i<= n is the feature vector.
##Deep Learning Algorithm - Restricted Boltzmann machine contains two hidden layers and for them two set of bias value is selected namely H0H1:
These set of bias values are values which are randomly selected
##Optimal Feature Vector Set Generation- Fine tune the obtained feature vector set by adjusting the weight of the units of the RBM
- To fine tune the feature vector set optimally we use back propagation algorithm
- Uses cross-entropy error 交叉熵
For example term weight feature of the sentence will be reconstruct by using following formula
##Sentence Score
Where:
Sc = Sentence score of a sentence
S = Sentence
Q = User query
Wc = Total word count of a text
##Ranking of Sentence
To find out number of top sentences to select from the matrix we use following formula based on the compression rate.