文本摘要(Text Summarization)作为NLP中一个重要的子任务一直以来都受到了广泛的关注,虽然问题本身的定义很简单且直观,但目前已有的模型或方法得到的结果并不理想。直到最近各种预训练模型的出现在一定程度上提升了评估指标的数值,并且不管是针对于长文档还是普通的短文档,最终生成的摘要结果还是很好的。但是如何更好的利用BERT等已有的预训练模型来做文本摘要或是更大类的文本生成任务是一个仍然没有很大解答的问题。
有关文本摘要的一些基础性知识和相关的文章这里就不再多加引入,有兴趣的可以查阅我之前的相关博文
文本摘要可以分为抽取式(extractive)和生成式(abstractive)两种,其中抽取式直接从原文中找到可以表达全文的短语或句子来组成最终的摘要,由于摘要中的成分完全来自于原文,因此结果的可读性和对主要内容的表述性相对要更好一些,因此也是目前来说广泛使用的一种;而生成式依赖于模型的生成能力,最终的结果既包含原文中已有的词,同时还包含本身并没有出现的词,但是目前已有的方法仍不能有效的解决生成式中OOV、可读性差和摘要长度较短等问题。抽取式和生成式一种直观的区别便是复制率(copy rate)的不同。在人工编辑摘要的工作中,人可以根据不同的应用场景和要求有意识的控制从原文中直接复制内容的比例,从而决定最终的结果偏抽取式多一些还是更倾向于生成式,但目前的模型并不具备处理这种要求的灵活性和弹性。
本文中作者希望通过控制复制率来进行建模,从而得到一个具有弹性的文本摘要模型。作者认为在模型的解码阶段无需使用teacher-forcing方法逐字的进行监督训练,为了更好的使模型具有弹性,可以参考摘要中可见[即在原文中出现过的词]和不可见[即原文中并没有出现过的词]的词分开。当模型解码时,如果模型仅预测可见词,那么结果偏抽取式多一些;如果模型预测不可见词的比例多一些,那么结果偏生成式就更多一些。
此外,为了更好的将文本摘要的目标和预训练模型结合在一起,作为将任务定义为语言建模任务,模型采用了多层Transformer的结果和MLM的预训练策略,模型的训练和推断阶段通过控制复制率来引导模型预测结果的趋向。另外在推断阶段比较了不同的检索和重排序方式对于结果的重用度的影响。实验中使用了Gigaword和Newsroom两个数据集,评价指标为衡量词相似度的ROUGE和衡量语义相似度的BERTScore。
Model
模型本身采用了和BERT相同的多层Transformer结构,为了更好的构建输入,文中使用START和END两个特殊的字符。输入的形式如下所示,输入是包含了原文和参考摘要的配对形式,两部分使用END进行分隔。
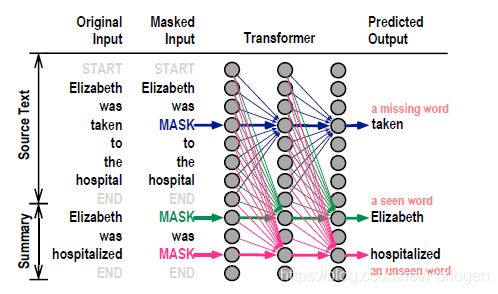
为了使模型具备理解原文和参考摘要间关联的能力,作者在训练中仍然使用了Mask Language Modeling的策略。首先构建合适形式的输入,然后随机选择一部分进行MASK,其中MASK比例的选择和BERT是一致的。另外为了控制复制率,作者将输入序列中的词分为了三类:
- 摘要中原文中出现过的词
- 摘要中有但原文并未出现过的词
- 原文中的词
如果MASK的内容选择的是第一种,那么得到的模型生成的摘要更偏抽取式;如果选择的是第二种,生成的摘要更偏生成式;如果选择的是第三种,模型完成的工作和BERT是一样的,只是增强模型本身的上下文表示能力。模型训练仍然是通过建模条件概率分布来对目标序列进行逐词的预测MASK的部分直到遇见最后的END标识符。
模型训练的损失函数即负对数似然:
为了方便在选择不同的内容进行MASK预测,文中在自注意力机制中使用了binary mask的方式来控制预测时模型可以看到的内容。其中对于原文中的符号,计算时可注意到包括自己在内的所有原文符号;对于摘要中的符号,计算时只能注意到MASK部分和之前的内容。
模型最终的输入可表示为:
其中
、
和
分别表示token embedding、positional embedding和segment embedding;
、
和
是one-hot形式的方便token进行检索的矩阵。
推断阶段即建模最大化 的过程,除了最常使用Beam Search外,作者还提出了Best-First Search,算法描述如下所示:

它首先建立一个优先堆来存储不完整摘要,每次迭代时模型会选择分数最高的不完整的摘要,在取出的摘要后接k个不同的词,生成k份新的摘要放入堆中。因此,每次迭代后堆中的摘要长度不等,若堆中的最高得分摘要以END符号结尾,则将其置入完整摘要池等待重排。
beam search在每次迭代过程中生成的摘要的长度和个数是固定的,最终生成的摘要同样会有一个重排序的过程。两者的不同之处在于前者更倾向于选择分数高的结果,而后者同时还考虑了摘要的长度。
为了满足对于生成的摘要长度的要求,模型还需要进行重排序(reranking)来选择最终的结果。文中提出了三种方式来制约摘要的长度:
- Length normalization:似然分数除以长度,从而避免生成过长的摘要
- BP-norm:同用于惩罚哪些未满足长度要求的结果,使生成摘要趋向于更高的复制率 其中 表示复制率
- Soft-bounded word reward(SBWR):目的是为了使摘要的长度和参考摘要一致 其中 表示奖励值,softmax函数用于平滑分数
Experiment
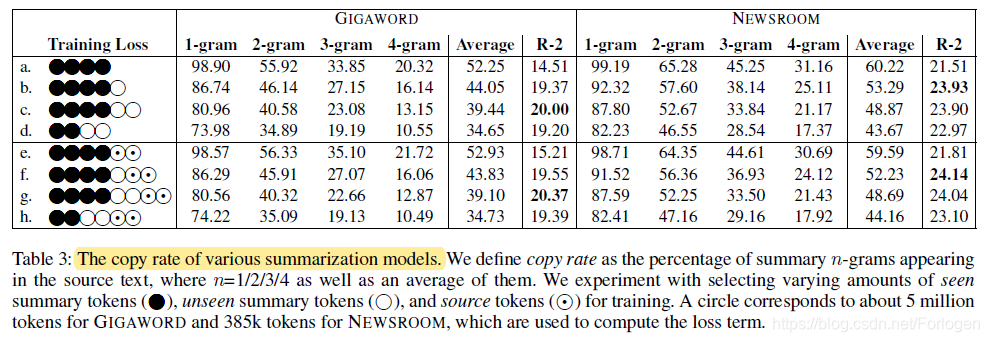
实验验证不同的MASK内容的选择对于摘要表现出的复制率的影响。
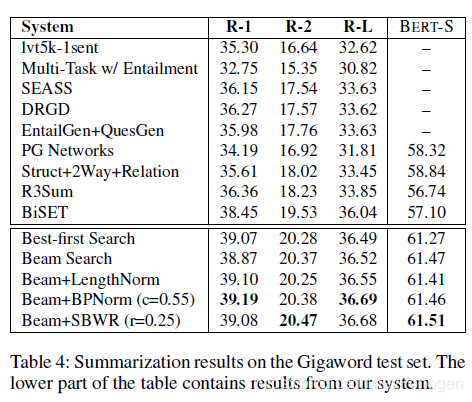
模型和其他基准模型的对比。
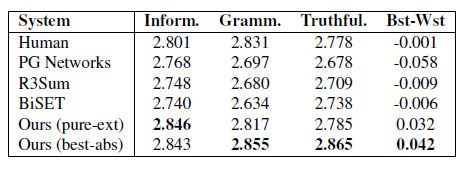
人工评测。