every blog every motto: There’s only one corner of the universe you can be sure of improving, and that’s your own self.
https://blog.csdn.net/weixin_39190382?spm=1010.2135.3001.5343
0. 前言
在前面我们回顾了R-CNN系列,总体来说,先生成候选框,然后对候选框进行剔除,随后对目标进行分类和box回归,进而实现目标检测。
简单说:
- 生成候选框
- 候选框分类
总体来说,分了两步,即我们熟悉的two stage。
本文开始,我们正式进入one-stage!
YOLO 是 You only look once 几个单词的缩写。
1. 正文
时间: 2015
论文: https://arxiv.org/abs/1506.02640
代码: https://github.com/pjreddie/darknet v1好像是C写的
作者: Joseph Redmon∗ , Santosh Divvala∗†, Ross Girshick¶ , Ali Farhadi∗†
作者单位: University of Washington∗, Allen Institute for AI†, Facebook AI Research¶
1.1 网络结构
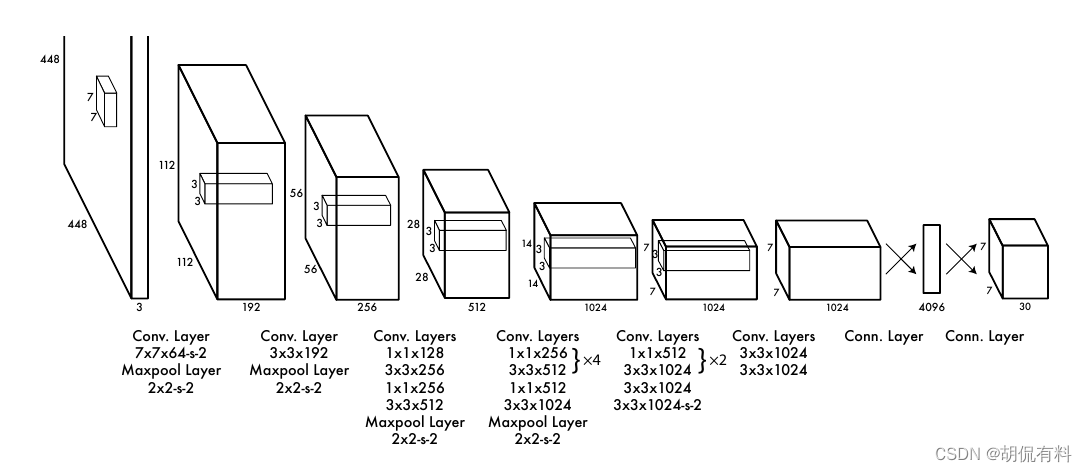
通过网络图我们看到,整体就是卷积池化等一些的堆叠,而不是像之前R-CNN那样分好多步,所以速度上自然快了不少。
是一个端到端的网络,所以自然更加优雅!!!
那到底是怎么通过简单的网络实现目标检测,这么一个“复杂的任务”的呢?
1.2 算法流程
1.2.1 核心介绍
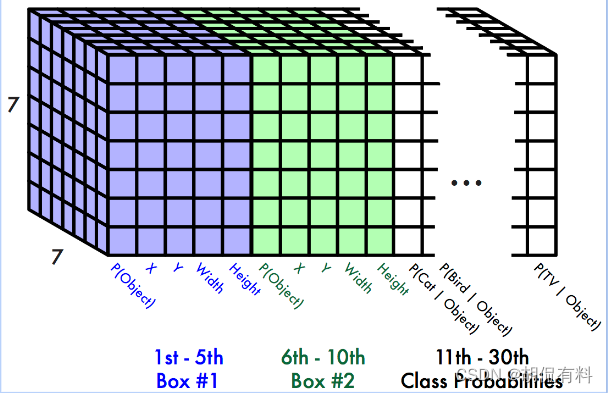
将图片分割成S × S大小的格网(grid),每个格网大小是相等的。(具体是怎么分割的呢?其实就是图片输入网络,最后输出的特征图大小为S × S的!!!)
论文中S = 7

一共会有S*S个格子,每个格子预测B个bounding box(就是最后输出物体周围的那个框框,只是这里生成的比较多,后面会剔除),论文中B = 2,即,
每个格子预测两个框框(bounding box)。
怎么确定这个bounding box呢?
中心坐标(x,y)
长宽(h,w)
这四个参数就唯一确定了一个框框(bounding box)
最后还有置信度,就是预测这个框框(bounding box)确信程度。
到这里,我们对一个框框(bounding box)会预测出5个参数为,(x , y , w , h , confidence)




最终会预测7×7×2 = 98个框框,如下图
confidence越高,框框越粗。

每个格子不仅要预测框框(bounding box)还需要预测其中的物体类别,使用one-hot编码。如果一共对C种物体进行识别,则最后(B×5 + C)预测值,他们保存在通道方向上。
论文中预测20类,即C = 20。
所以输出: (S,S,B×5 + C)
实际为,(7,7,30),与网络图的最后输出一致(可返回去看前面的网络图)
1.2.2 部分细节
a. bounding box
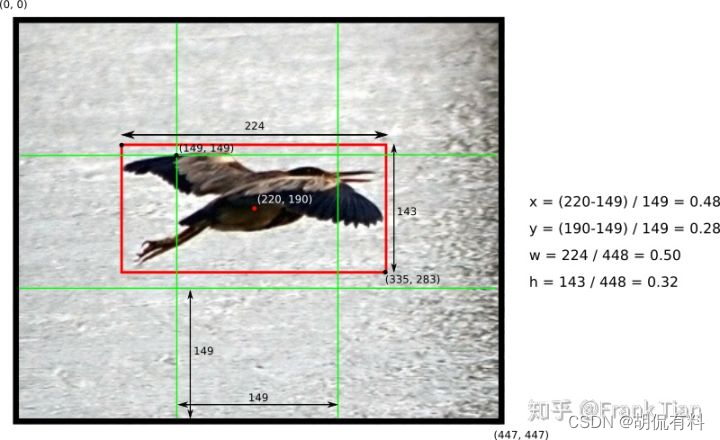
bounding box可以确定物体的位置,它输出四个值,分别为x,y,h,w。
在卷积神经网络中,常用套路是对数据进行归一化(或标准化),让数据落入0-1之间,更有利于训练,这里也不例外。
x,y的值是相对格子左上角而言的,只要让它除以格子长宽即可,具体:
x ′ = x g r i d _ w i d t h x' = \frac { x } {grid\_width} x′=grid_widthx
y ′ = y g r i d _ h e i g h t y' = \frac { y } {grid\_height} y′=grid_heighty
而,h,w却不能这样,因为bounding box可能会超出我们的格子。
bounding box可能会超出我们的格子边界。
bounding box可能会超出我们的格子边界。
bounding box可能会超出我们的格子边界。
如果除以格子长宽,数值会超过0-1之间,解决方法是,除以图片的长宽
w ′ = w i m g _ w i d t h w' = \frac { w } {img\_width} w′=img_widthw
h ′ = h i m g _ h e i g h t h' = \frac { h } {img\_height} h′=img_heighth
下图显示了4个值的计算过程:
还剩最后一个置信度confidence,计算公式为:
c o n f i d e n c e = P r ( o b j ) ∗ I o U t r u t h p r e d confidence = Pr(obj) * IoU_{truth}^{pred} confidence=Pr(obj)∗IoUtruthpred
IoU是交并比,即真实框和预测框的比值。
Pr(obj)是一个格子中是否有物体的概率,有物体为1,没有为0。
b. loss
损失函数一共分5项:
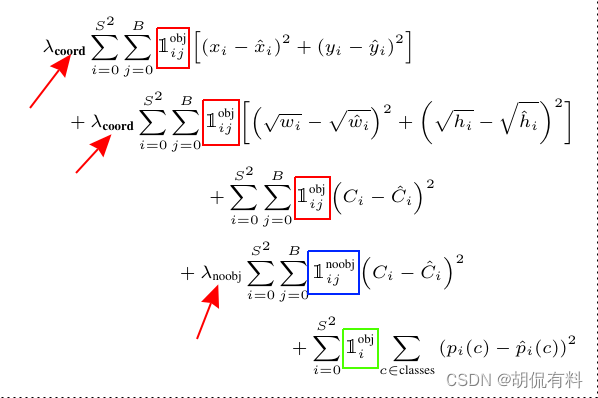
1 i j o b j 1_{ij}^{obj} 1ijobj表示这个格子是否有物体,如果有值为1,否则为0。
1 i j n o b j 1_{ij}^{nobj} 1ijnobj相反。
当一个格子有物体时,计算1、2、3、5项
当一个格子没有物体时,计算第4项。
λ c o o r d = 5 \lambda _{coord}= 5 λcoord=5
λ n o b j = 0.5 \lambda _{nobj}= 0.5 λnobj=0.5
放大第1、2项,缩小第4项。
参考
[1] https://zhuanlan.zhihu.com/p/94986199
[2] https://zhuanlan.zhihu.com/p/297965943
[3] https://bbs.huaweicloud.com/blogs/297764
[4] https://blog.csdn.net/weixin_43702653/article/details/123959840?spm=1001.2014.3001.5501#t0
[5] https://muyuuuu.github.io/2021/08/26/yolo-v1/
[6] https://www.cnblogs.com/ywheunji/p/10808989.html