

前言: faster-RCNN在目标检测精度上已经能够达到一个很高的水准,但是作为RCNN系列的最巅峰,它提出了RPN网络产生推荐性区域,但是它依旧有着一些缺点,这些区域里面有大面积是重合的,影响了计算效率。为了更好地提升目标检测的计算效率,从DPM检测中获得了相关的灵感,于是yolo网络应运而生,现在yolo网络已经有了很多的版本,yolo v1、yolo v2、yolo v3、fast yolo 等系列算法,本文针对最原始的yolo v1算法。
目录
一、初识yolo
二、目标检测相关背景知识
三、yolo算法详解
3.1 yolo的核心设计思想
3.1.1 什么是格子的置信度confidence score?
3.1.2 什么是物体的概率probability?
3.1.3 每一个grid的输出数据维度的对应关系
3.1.4 yolo原理的运算过程展示
3.2 yolo网络的设计架构
3.3 yolo损失函数的设计
3.4 yolo网络的训练
3.5 yolo网络的测试——class-specific confidence score
3.6 yolo网络的结果展示
3.7 yolo的主要特点总结
一、初识yolo
YOLO(You Only Look Once)是CVPR2016的一篇文章,yolo的全称是《You Only Look Once: Unified, Real-Time Object Detection》,这是rbg(Ross Girshick)大神继RCNN,fast-RCNN 和 faster-RCNN之后的又一创作,通过名字我们可以看出本文的设计思想——“你只需要看一次” 。的确相比于前面的RCNN系列思想,它不用对大量重复的RP区域进行操作,所以yolo解决了深度学习目标检测中一个大痛点,就是速度问题。
其增强版本GPU(Titan X )中能跑45fps(即每秒识别45张图,这速度已经很快了),简化版本155fps。
从它的论文名字中就可以得出几个非常重要的思想:
(1)组需要看一次。即对图片只需要扫描一次即可;
(2)unified。这是单位化的意思,究竟是对什么单位化,后面会讲到。
(3)real-time。实时运算。
二、目标检测相关背景知识
在介绍yolo之前,首先引入一下目标检测的进展,yolo之前的目标检测一般是如何做的呢?有两个代表:DPM以及RCNN系列
(1)DPM:即Deformable Parts Model,它利用sliding window,提取特征(SIFT等),进行比对 。DPM算法由Felzenszwalb于2008年提出,是一种基于部件的检测方法,对目标的形变具有很强的鲁棒性。目前DPM已成为众多分类、分割、姿态估计等算法的核心部分,Felzenszwalb本人也因此被VOC授予"终身成就奖"。
(2)RCNN: 利用region proposal方法提取,利用网络进行分类,并进行坐标回归预测,参见前面的博文。
那是如何根据DPM和RCNN系列的相关思想提出了yolo这样的设计理念的呢?
(1)首先先介绍一下滑动窗口sliding window技术,这Yolo算法思想的直接来源。采用滑动窗口的目标检测算法思路非常简单,它将检测问题转化为了图像分类问题。其基本原理就是采用不同大小和比例(宽高比)的窗口在整张图片上以一定的步长进行滑动,然后对这些窗口对应的区域做图像分类,这样就可以实现对整张图片的检测了,如下图所示:

如DPM就是采用这种思路。但是这个方法有致命的缺点,就是你并不知道要检测的目标大小是什么规模,所以你要设置不同大小和比例的窗口去滑动,而且还要选取合适的步长。但是这样会产生很多的子区域,并且都要经过分类器去做预测,这需要很大的计算量,所以你的分类器不能太复杂,因为要保证速度。
(2)滑动窗口产生的子区域太多了该怎么过滤一些不太需要的其区域呢?解决思路之一就是减少要分类的子区域,这就是R-CNN的一个改进策略,其采用了selective search方法来找到最有可能包含目标的子区域(Region Proposal),其实可以看成采用启发式方法过滤掉很多子区域,这会提升效率。但是我们知道RCNN系列文章所产生的推荐区域还是有2000个左右,所以这个计算量依然很大,很难实现实时运算。
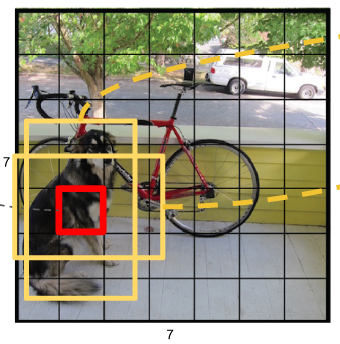
Yolo算法的思想来源虽然是sliding window ,但是它不再是窗口滑动了,而是直接将原始图片分割成互不重合的小方块,然后通过卷积最后生产这样大小的特征图,基于上面的分析,可以认为特征图的每个元素也是对应原始图片的一个小方块,然后用每个元素来可以预测那些中心点在该小方格内的目标,这就是Yolo算法的朴素思想。
三、yolo算法详解
3.1 yolo的核心设计思想
yolo最大的创新点在于改革了区域建议框式检测框架: RCNN系列均需要生成建议框,在建议框上进行分类与回归,但建议框之间有重叠,这会带来很多重复工作。YOLO将全图划分为SXS的格子,每个格子负责中心在该格子的目标检测,采用一次性预测所有格子所含目标的bbox、定位置信度以及所有类别概率向量来将问题一次性解决(one-shot)。
将一张图片分成S*S个格子之后,每一个格子具备以下几个关联属性
(1)每一个格子的bounding box,即(x,y,w,h),x,y为格子的中心位置,w,h为格子的宽和高;
(2)每一个格子包含物体的置信度confidence score,简称confidence;
(3)格子中是某一个物体的概率probability;

下面将分别对每一个属性进行说明:
3.1.1 什么是格子的置信度confidence score?
这个 confidence scores反映了模型对于这个栅格的预测,confidence score包含了两个方面——即该栅格是否含有物体,以及这个box的坐标预测的有多准(多准是通过IOU定义的,IOU越大,说明越准,IOU越小说明越不准)。
公式定义如下: 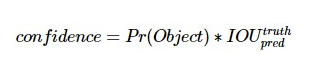
这个公式是什么意思呢?
如果这个栅格中不存在一个 object,即Pr(Object)=0,既然都不存在物体,自然也不存在什么IOU了,则confidence score应该为0;如果存在物体的话,则Pr(Object)=1,此时confidence score则为 predicted bounding box与 ground truth box之间的IOU(intersection over union)
注意:yolo默认情况才S=7,即分割成S*S=49个grid,然后对每个gird,预测B个(bounding box + confidence)(B默认为2),如果不存在物体,则confidence为0,否则期望其为IOU,bounding box为:[x,y,w,h]其中(x,y)为object中心点坐标
备注:这里为什么要对每一个grid预测B个(x,y,w,h,confidence),由于每个单元格预测多个边界框(即文中的B,B取值为2)。但是其对应类别只有一个。那么在训练时,如果该单元格内确实存在目标,那么只选择与ground truth的IOU最大的那个边界框来负责预测该目标,而其它边界框认为不存在目标。这样设置的一个结果将会使一个单元格对应的边界框更加专业化,其可以分别适用不同大小,不同高宽比的目标,从而提升模型性能。
3.1.2 什么是物体的概率probability?
每一个栅格grid还要预测C个 conditional class probability(条件类别概率),即Pr(Classi|Object)。即在一个栅格包含一个Object的前提下,它属于某个类的概率。 作者在VOC上实验,所以C取为20(这里为什么不是类似Fast RCNN的21类,因为是否为背景,作者放到了上面的confidence中)
3.1.3 每一个grid的输出数据维度的对应关系
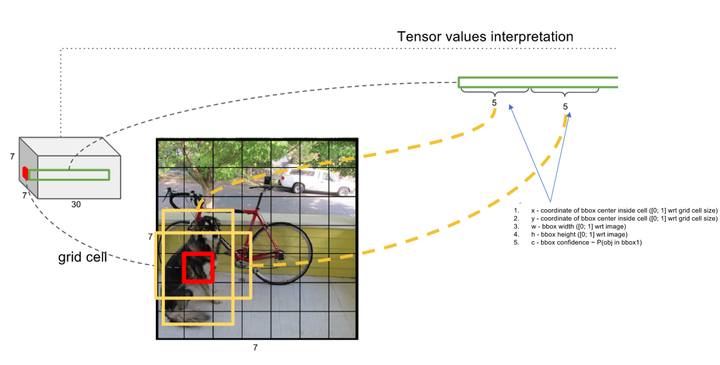
通过上面的3.2.1和3.2.2的说明,我们对每一个grid的预测会产生下面一些数据
(每一个grid)——>(x,y,w,h,confidence)
坐标x,y代表了预测的bounding box的中心与栅格边界的相对值。
坐标w,h代表了预测的bounding box的width、height相对于整幅图像width,height的比例。
confidence就是预测的bounding box和ground truth box的IOU值,即上面的confidence score。
3.1.4 yolo原理的运算过程展示
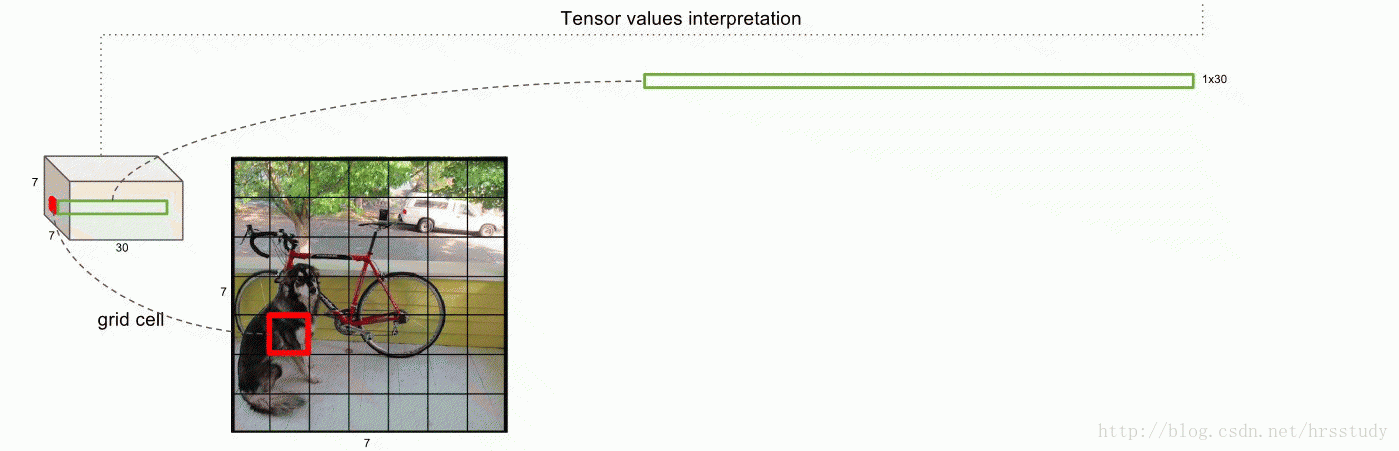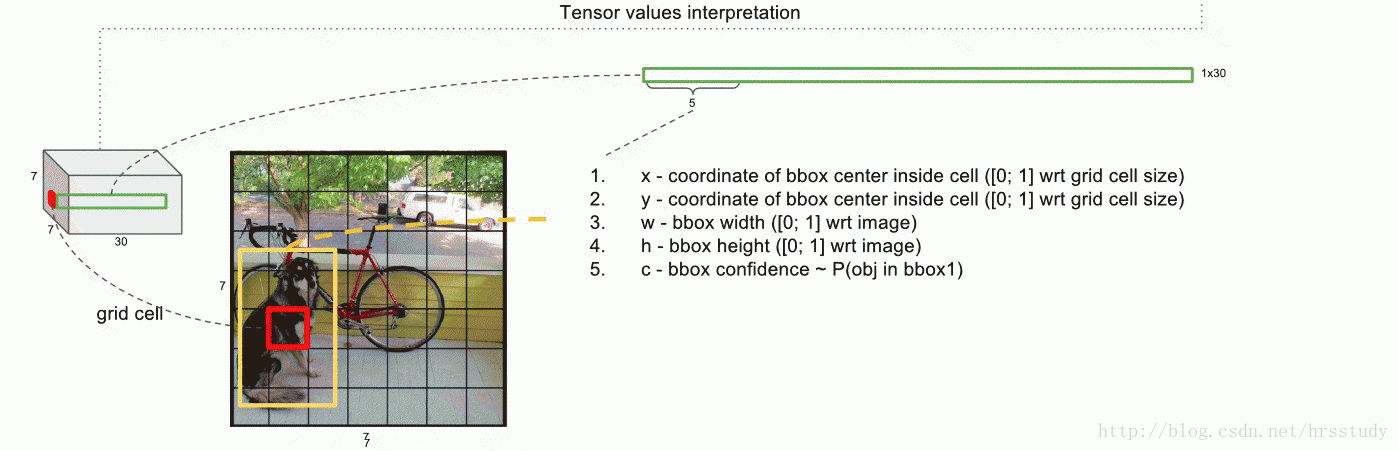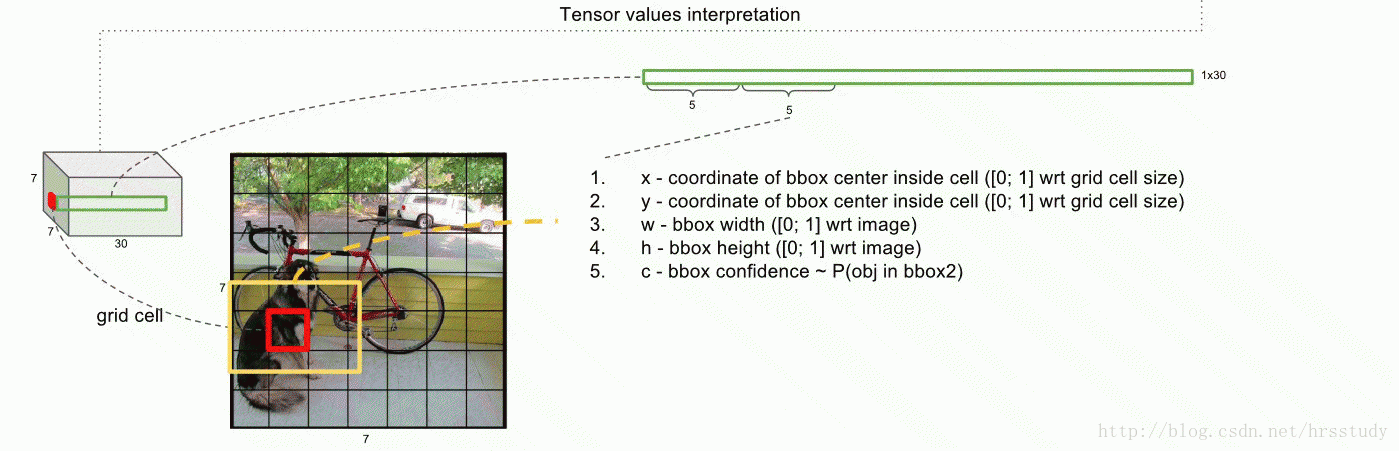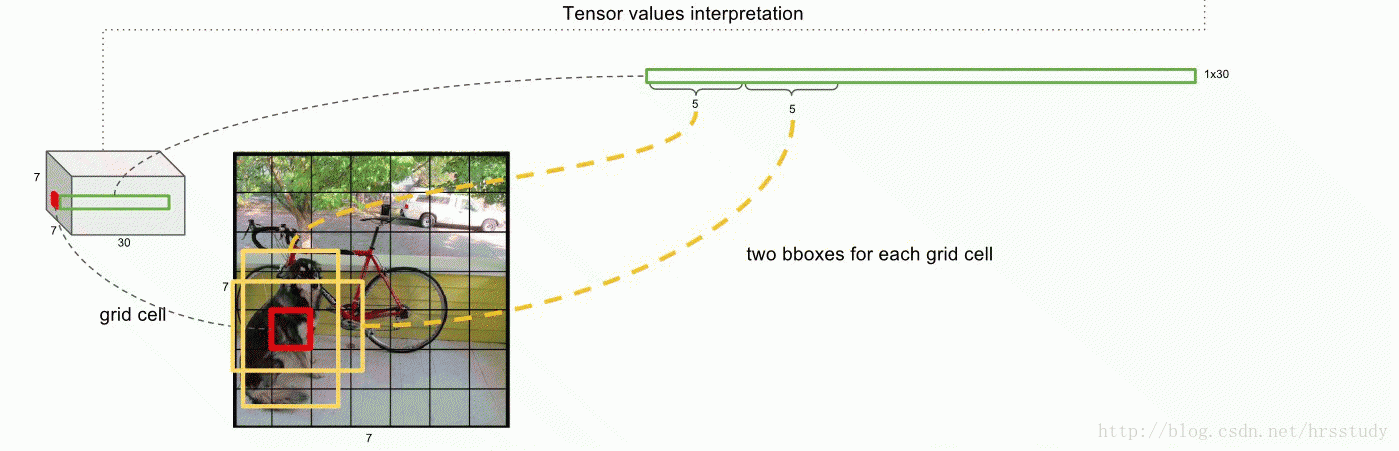
注:本图来源于一篇博客文站,感觉对于理解yolo非常有帮助,就粘贴过来了。
上图展示的是那个“红色的grid”预测的两个不同的“黄色边框”,每一个边框所携带的信息是5维,故而产生了10维向量。
再参考一个图片如下:

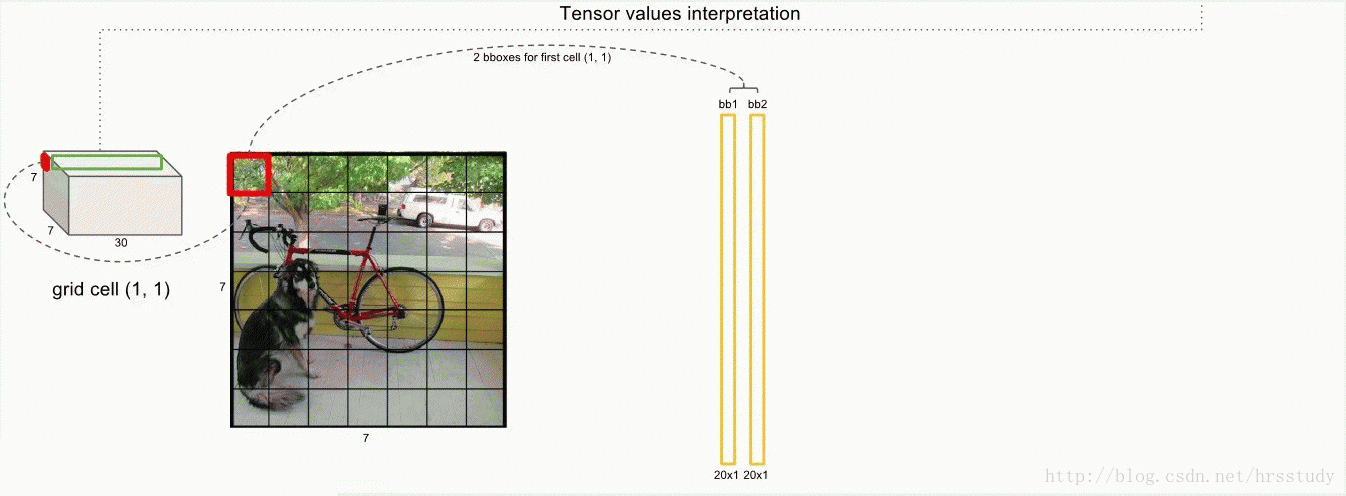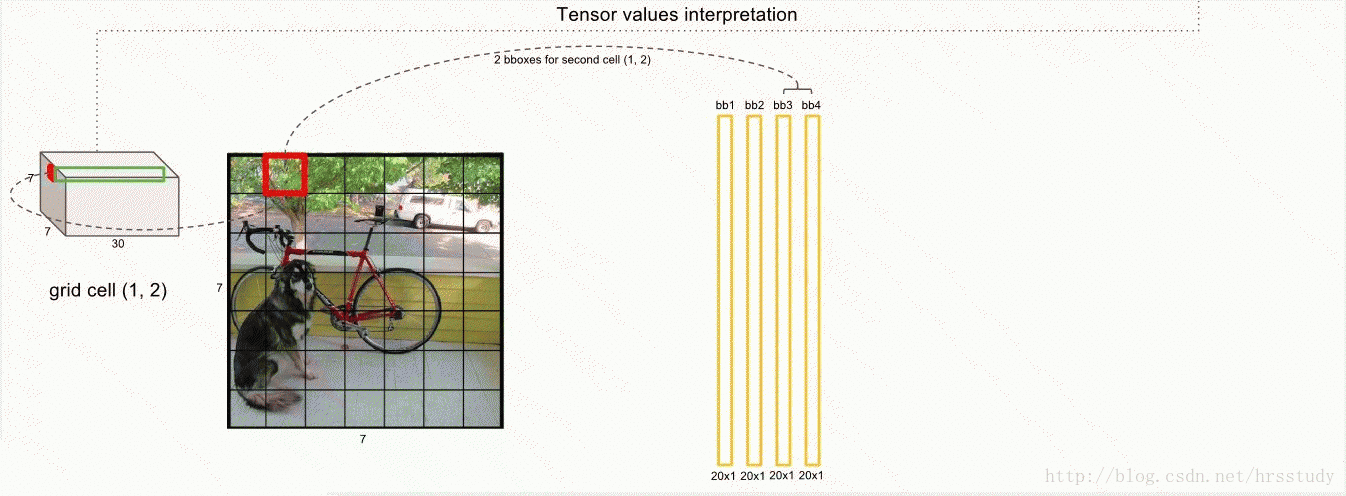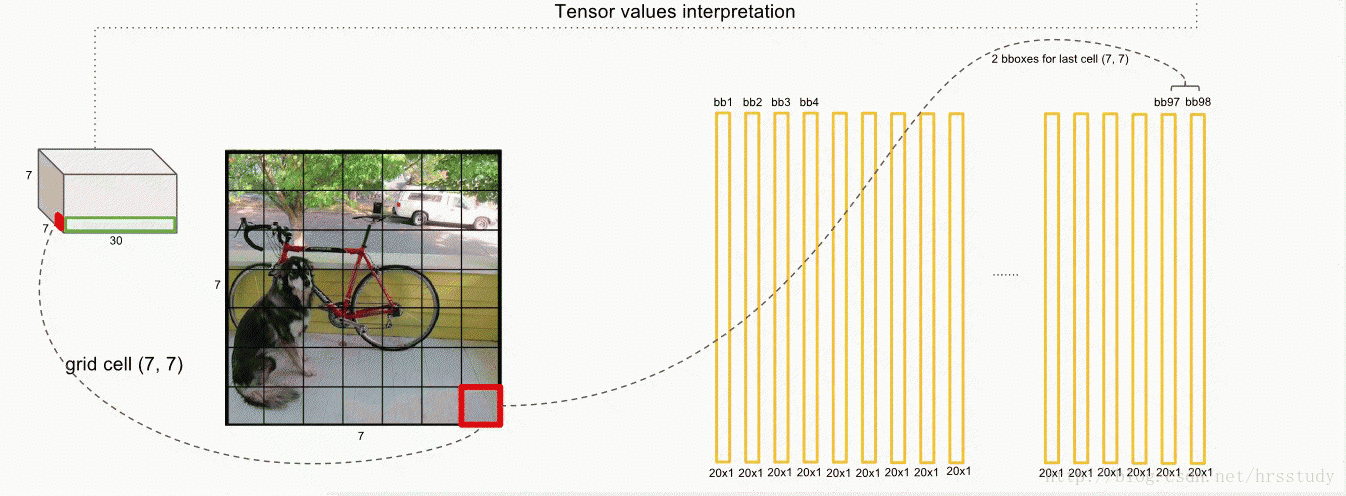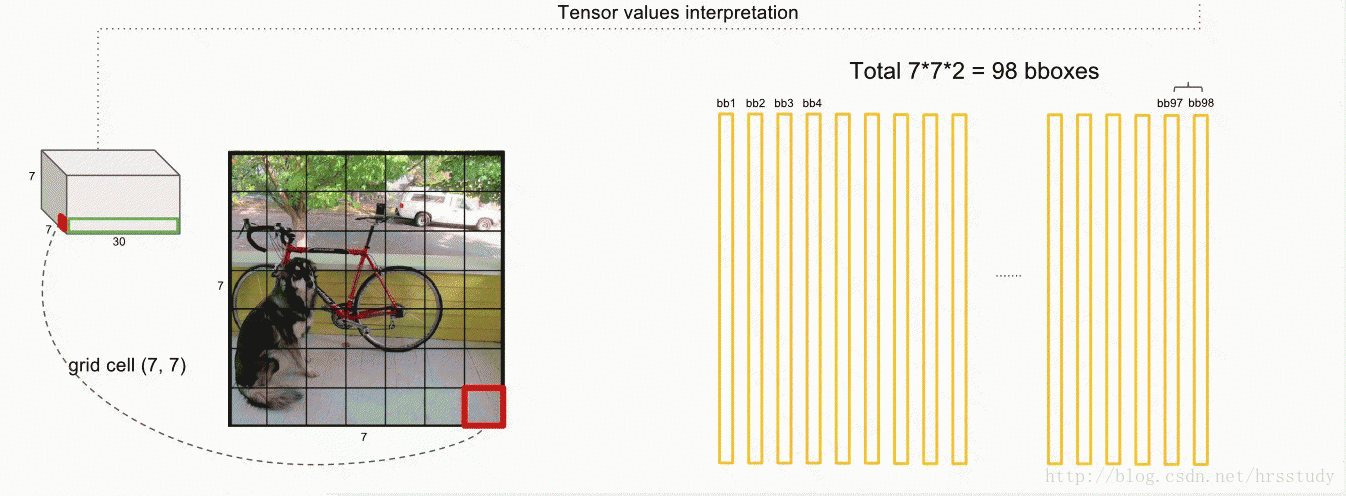
上图中前面的两个红色圈圈就不说了,表示的每一个grid预测的两个box的信息,共10维,后面的20维是每一个类别的概率,最后一共组成30维的向量。
那么整张图片下来,运算过程如下:
注意:在原始论文中将YOLO用于PASCAL VOC数据集时:
论文使用的 S=7,即将一张图像分为7×7=49个栅格grid,每一个栅格grid预测B=2个boxes(每个box有 x,y,w,h,confidence,5个预测值),同时C=20(PASCAL数据集中有20个类别)。
则一张图片的输出数据维度为:S*S*{B*5+C}
即7*7*(2*5+10)=49*30 维度
这里的5指的是(x,y,w,h,confidence)。
最后,大致的实现过程是这样子的:

3.2 yolo网络的设计架构
上面介绍了理论上的设计思想,但是yolo网络的结构究竟是怎么样的,到底是如何实现的呢?
Yolo采用卷积网络来提取特征,然后使用全连接层来得到预测值。网络结构参考GooLeNet模型(灵感来源于GoogLeNet,但是并没有采取其inception的结构),包含24个卷积层和2个全连接层,如下图所示:
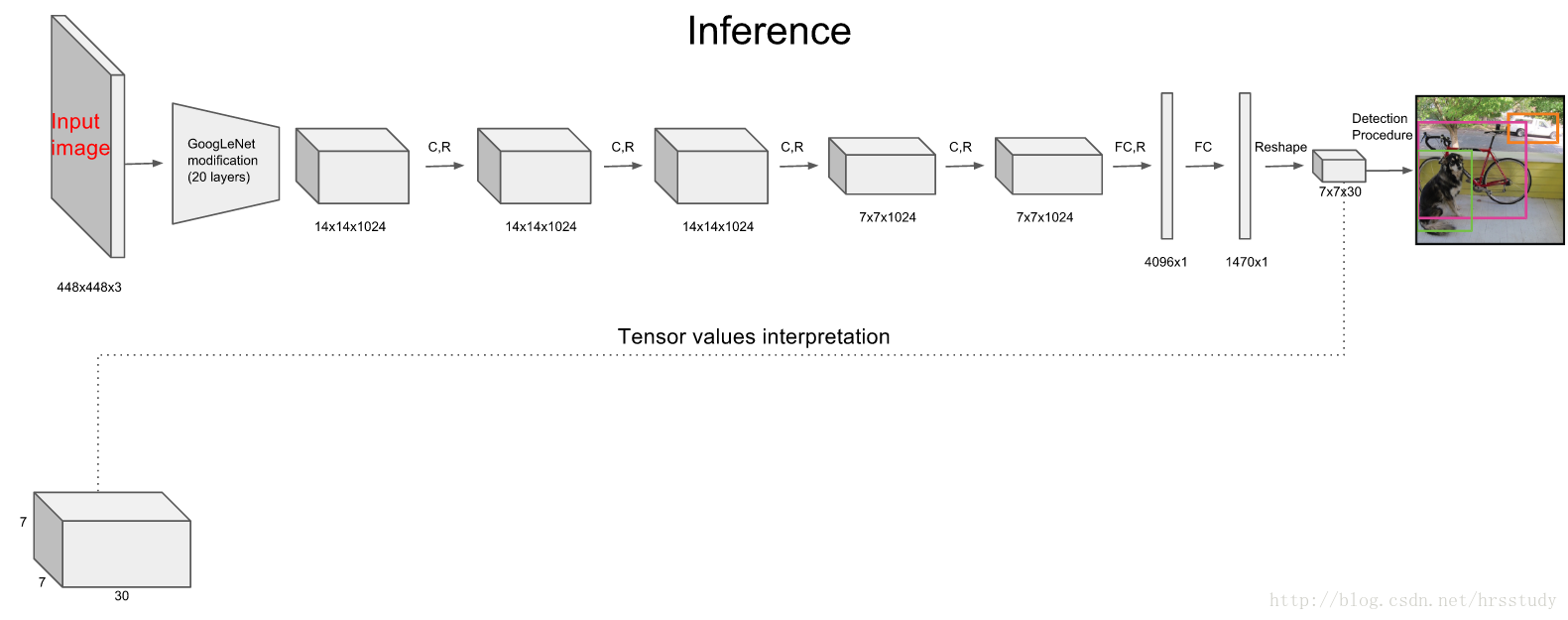
对于卷积层,主要使用1x1卷积来做channle reduction,然后紧跟3x3卷积。对于卷积层和全连接层,采用Leaky ReLU激活函数,但是最后一层却采用线性激活函数。网络的参数如下:

yolo网络的创新设计点:
(1)yolo的基础网络灵感来源于GoogLeNet,但是并没有采取其inception的结构,而是简单的使用了1×1的卷积核。基础模型中l共有24个卷积层,后面接2个全连接层;
(2)yolo并没有使用Relu激活函数,而是使用了leaky rectified linear激活函数;
补充:除了上面这个结构,文章还提出了一个轻量级版本Fast Yolo,其仅使用9个卷积层,并且卷积层中使用更少的卷积核。
3.3 yolo损失函数的设计
在实现中,最主要的就是怎么设计损失函数,作者简单粗暴的全部采用了sum-squared-error loss(即平方损失)来做这件事。 但是需要注意的是对不同的部分采用了不同的权重值。首先区分定位误差和分类误差。
对于定位误差,即边界框坐标预测误差,采用较大的权重。 另外一点时,由于每个单元格预测多个边界框(即文中的B,B取值为2)。但是其对应类别只有一个。那么在训练时,如果该单元格内确实存在目标,那么只选择与ground truth的IOU最大的那个边界框来负责预测该目标,而其它边界框认为不存在目标。这样设置的一个结果将会使一个单元格对应的边界框更加专业化,其可以分别适用不同大小,不同高宽比的目标,从而提升模型性能。(这就是为什么要对每一个grid预测B个(x,y,w,h,confidence)的原因了)。综上所述,最终的损失函数如下所示:

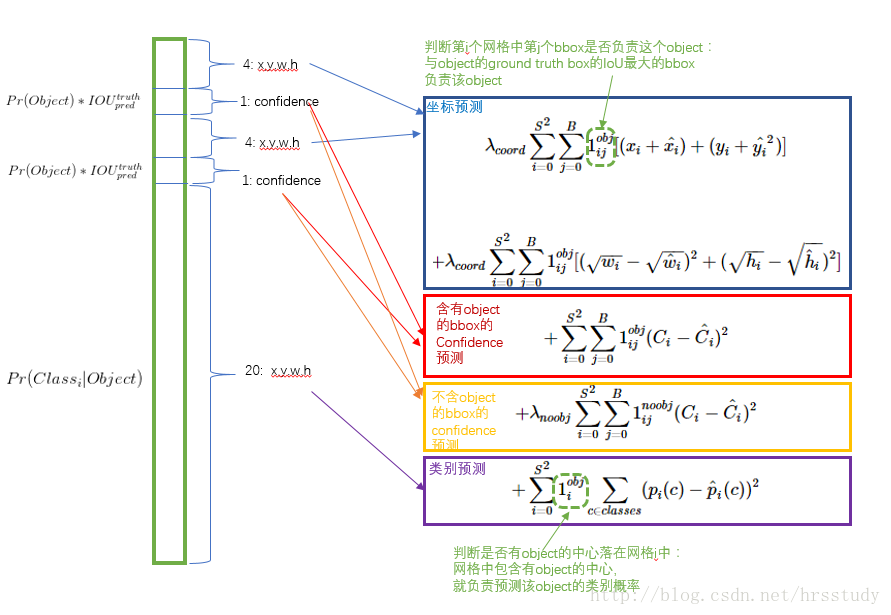
注意:这个损失函数的设计是有讲究的,主要需要注意一下几个点:
(1)为什么w、h那个地方要加一个根号?
对宽高都进行开根是为了使大小差别比较大的边界框差别减小。例如,一个同样将一个100x100的目标与一个10x10的目标都预测大了10个像素,预测框为110 x 110与20 x 20。显然第一种情况我们还可以失道接受,但第二种情况相当于把边界框预测大了一倍,但是从绝对数值上来看,他们都是只扩大了10个像素嘛,但是前者之扩大0.1倍,后者却扩大了1倍,解决方法就是使用根号函数,那么损失相同,都为200。但把宽高都增加根号时:
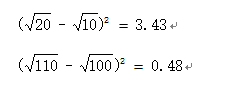
从上面的式子可以看出,显然,对小框预测偏差10个像素带来了更高的损失。通过增加根号,使得预测相同偏差与更小的框产生更大的损失。但根据YOLOv2的实验证明,还有更好的方法解决这个问题,这就后面的文章再说吧。
(2)另外一个问题就是由于损失函数是由几部分组成的,如果每一个的权重都是一样的,这是不合理的。更重要的是,对于一个grid而言,
- 若有物体落入边界框中,则计算预测边界框含有物体的置信度Ci真实物体与边界框IoUCi的损失,我们希望两差值越小损失越低。
- 若没有任何物体中心落入边界框中,则 IoUCi为0,此时我们希望预测含有物体的置信度Ci越小越好。然而,大部分边界框都没有物体,积少成多,造成loss的第3部分与第4部分的不平衡
这里的两个问题会导致网络不稳定甚至发散 ,解决方法就是:
更重视8维的坐标预测,给这些损失前面赋予更大的loss weight, 记为,在pascal VOC训练中取5。对没有object的box的confidence loss,赋予小的loss weight,记为
,在pascal VOC训练中取0.5。有object的box的confidence loss和类别的loss的loss weight正常取1。对不同大小的box预测中,相比于大box预测偏一点,小box预测偏一点肯定更不能被忍受的,而sum-square error loss中对同样的偏移loss是一样。
3.4 yolo网络的训练
yolo的训练过程是分为几个过程实现的
(1)预训练分类网络。 在 ImageNet 1000-class competition dataset上预训练一个分类网络,这个网络是前面yolo网络结构中的前20个卷机网络+average-pooling layer+ fully connected layer (此时网络输入是224*224)。它是作为Pretrain 的网络。训练大约一周的时间,使得在ImageNet 2012的验证数据集Top-5的精度达到 88%,这个结果跟 GoogleNet 的效果相当。
(2)训练检测网络。转换模型去执行检测任务,《Object detection networks on convolutional feature maps》提到说在预训练网络中增加卷积和全链接层可以改善性能。在他们例子基础上添加4个卷积层和2个全链接层,随机初始化权重。

上面的中间的用大括号括起来的是新增加的网络结构。由于检测任务一般需要更高清的图片,检测要求细粒度的视觉信息,所以将网络的输入从224x224增加到了448x448,
训练的超参数设置:
data : VOC2007以及VOC2012
epoch : 135
batchsize:64
momentum:0.9
decay:0.0005
learning rae schedule: 前75个epoch 10e-2,然后30个epoch 10e-3,最后30个epoch 10e-4
3.5 yolo网络的测试——class-specific confidence score
在测试的时候,每个网格预测的class信息( )和bounding box预测的confidence信息(
) 相乘,就得到每个bounding box的class-specific confidence score。
即:
等式左边第一项就是每个网格预测的类别信息,第二三项就是每个bounding box预测的confidence。这个乘积既了预测的box属于某一类的概率,也有该box准确度的信息。
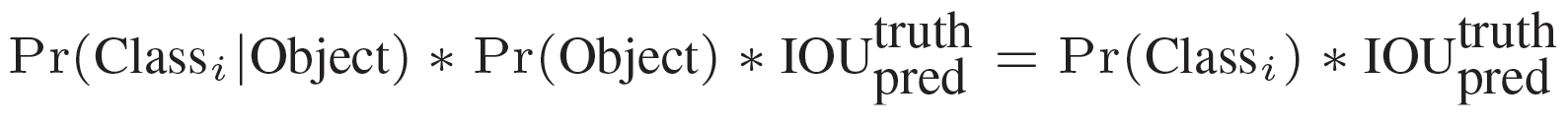
得到每个box的class-specific confidence score以后,设置阈值,滤掉得分低的boxes,对保留的boxes进行NMS处理,就得到最终的检测结果。
3.6 yolo网络的结果展示
(1)花费时间以及mAP的对比

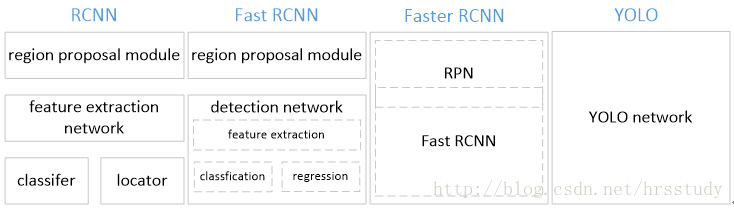
(2)网络架构的的对比
(3)综合性能对比


实验表明,YOLO的精度不高(略低于faster R-CNN)但是对于background的错检率要高于fast rcnn。
3.7 yolo的主要特点总结
(1)只看一次。划分成S*S的区域,不用大量的重复候选框,大大节省了运算效率。yolo不同于sliding window以及region proposal方法在训练和检测的时候只能看到局部图像,而yolo可以看到全局图像,(这也是导致后面实验中Fast R-CNN的将背景检测错误的概率要高于yolo的原因)
(2)end to end 。实现端到端的实现,满足实时运算的基本要求
(3)不再是分类和回归的多任务,统一成regression。不再需要分别做候选区域的分类和位置回归了,而是统一当成一个回归regression问题来做,
优点总结:
(1)yolo很快,在 Titan X GPU上训练,基础的yolo可以达到 45 frames per seconds , fast yolo 可以达到155 frames per seconds,
(2)Yolo采用一个CNN网络来实现检测,是单管道策略,其训练与预测都是end-to-end,所以Yolo算法比较简洁且速度快。
(3)由于Yolo是对整张图片做卷积,所以其在检测目标有更大的视野,它不容易对背景误判。其实我觉得全连接层也是对这个有贡献的,因为全连接起到了attention的作用。
(4)Yolo的泛化能力强,在做迁移时,模型鲁棒性高。正因为yolo具有较强的泛化能力,对于艺术品同样具有较好的检测效果
缺点总结:
(1)小物体的识别准确率低。首先Yolo各个单元格仅仅预测两个边界框,而且属于一个类别。对于小物体,Yolo的表现会不如人意。这方面的改进可以看SSD,其采用多尺度单元格。也可以看Faster R-CNN,其采用了anchor boxes。Yolo对于在物体的宽高比方面泛化率低,就是无法定位不寻常比例的物体。
(2)Yolo的定位不准确也是很大的问题。检测的位置不是特别准确。
(3)当一个单元格内存在多个目标怎么办,其实这时候Yolo算法就只能选择其中一个来训练,这也是Yolo算法的缺点之一。要注意的一点时,对于不存在对应目标的边界框,其误差项就是只有置信度,左标项误差是没法计算的。而只有当一个单元格内确实存在目标时,才计算分类误差项,否则该项也是无法计算的。