一、CNN based One-Stage Detectors
所有论文综述均保持如下格式:
1、一页PPT内容总结一篇论文
2、标题格式一致:出处 年份 《标题》
3、内容格式一致:针对XX问题;提出了XX方法;本文证明了XXX
4、把握核心创新点,言简意赅
5、开源代码链接
强烈推荐:目标检测论文资源列表(各目标检测网络性能对比、论文链接、官方/非官方代码链接)
https://github.com/hoya012/deep_learning_object_detection#2014
一、ICLR 2014《Over Feat:Integrated Recognition, Localization and Detection using Convolutional Networks》
- 针对:分类任务中,卷积神经网络的特征提取用于定位检测
- 提出了:利用滑窗和规则块生成候选框,再利用多尺度滑窗增加检测结果,解决图像目标形状复杂、尺寸不一,最后用CNN、回归模型分类、定位目标
- 本文证明了:首次提出用同一卷积网络完成多个任务(分类、定位、检测)把分类过程提取到的特征同时用于定位检测,只需要改变网络的最后几层即可
二、CVPR 2016《You Only Look Once: Unified, Real-Time Object Detection》v1
- 针对:Two-stage目标检测速度问题
- 提出了:第一个one-stage检测器;完全放弃“proposal detection + verification”;将单个神经网络应用于完整图像,将图像划分为多个区域,并同时预测每个区域的边界框和概率;采用Leaky ReLU


缺点:与two-stage相比,定位精度下降,特别对于一些小目标,YOLO后续版本和SSD关注了该问题。 - 本文证明了:YOLOv1能有效地提升目标检测速度
GitHub官方源码
GitHub非官方源码(Tensorflow)
三、CVPR 2017《YOLO9000: Better, Faster, Stronger》
- 针对:检测速度和准确率之间的trade-off,重点解决召回率和定位精度的误差
- 提出了:1.在每一卷积层后面加入BN;2.High resolution classifier;3.借鉴faster R-CNN,引入Anchor机制,通过预测Anchor box的偏移值与置信度,而不是直接预测坐标值;4.维度聚类(使用K-means聚类方法类训练Bounding Boxes,自动找到更好的宽高维度的值用于先验Anchor box);5.直接位置预测;6.Fine-Grained Features;7.特征融合(将高分辨率的浅层特征连接到高层进行特征融合,提高对小目标的检测能力);8.多尺度训练(训练网络时采用随机输入32倍数的图像尺寸,使网络能在不同分辨率上检测);9.采用Darknet-19主干网络

- 本文证明了:YOLOv2能有效提升检测速度和精度;此外,通过目标分类与检测的联合训练方法,可以检测多达9000种物体
GitHub非官方源码(PyTorch)
GitHub非官方源码(Tensorflow)
四、CVPR 2018《YOLOv3: An Incremental Improvement》
- 针对:保证实时性基础上追求高检测精度
- 提出了:1. bounding box中只有和ground truth的IOU最大的bounding box才是用来预测该object;2.多标签分类,每个候选框可预测多个分类,将softmax换成逻辑回归层;3.多尺度预测,类似FPN;4.更好的基础分类网络darknet-53
- 本文证明了:YOLO系列的最强版本
GitHub非官方源码(PyTorch)
GitHub非官方源码(Tensorflow)
五、ECCV 2016《SSD:Single Shot MultiBox Detector》
- 针对:多尺度物体检测
- 提出了:引入多参考和多分辨率检测技术,采用多尺度特征图做预测;采用卷积进行检测;设置先验框;SSD中的数据增广可以多学习
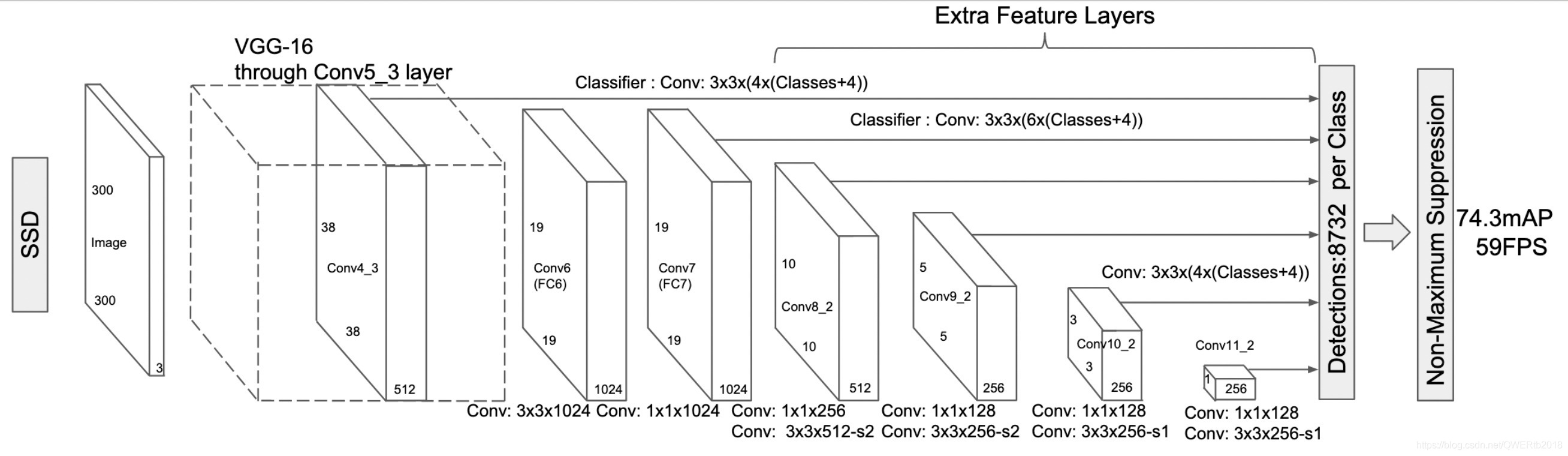
- 本文证明了:该技术显著提高了one-stage的检测精度,尤其对于某些小物体
GitHub非官方源码(PyTorch)
GitHub非官方源码(Tensorflow)
六、ICCV 2017《RetinaNet:Focal Loss for Dense Object Detection》
- 针对:One-stage检测精度不如two-stage,极端前景-背景(正负样本)类别不均衡导致
- 提出了:交叉熵损失基础上,提出focal loss(只能说非常好用!),以便检测器在训练过程中将更多的注意力放在困难、分类错误的示例上
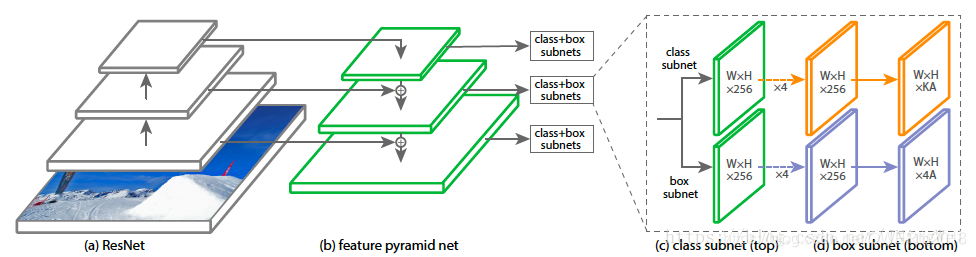
- 本文证明了:Focal Loss使one-stage达到two-stage相当的精度,同时保持非常高的检测速度
GitHub非官方源码(PyTorch)
GitHub非官方源码(Tensorflow)
二、说明
- 博客内容只是总结每篇论文的主要创新点,针对什么问题,提出了什么方法,没有翻译论文,也没有详细阐述论文中提出的网络结构,实验方法。原因在于:网上有很多关于各种论文的详细翻译、理解,但读者很难集中时间去消化理解每一篇论文内容,往往都是看完一篇过几天就忘记了,所以本文采用这种总结方式,简洁明了,使其对基于One-stage的目标检测网络有一整体的认识。
- 以上内容均基于本人看论文的理解,可能在某些总结上存在错误或者理解不够,恳请大家能在留言提出来,我会及时修改,我希望通过写博客的方式,加深对论文的理解,并期望得到提高,谢谢大家!
