算法发展史
近几年来,目标检测的算法取得了很大突破。比较流行的算法可以分为 2 类:
一类是基于 Region Proposal 的 R-CNN 系列算法,属于 two-stage 算法,也就是流水线算法,先使用启发式方法(Selective Search)或者 CNN 网络(RPN) 产生 Region Proposal,然后在对 Region Proposal 进行分类和回归;
另一类是 Yolo、SSD 算法,属于 one-stage 算法,也就是端到端算法,使用一个 CNN 网络直接预测类别和位置;
第一类算法速度慢,准确度高,第二类算法速度快,准确度低

Yolo 系列算法分为 Yolo v1、v2、v3,Yolo v1 是 Yolo 和 SSD 的基础,本文会花大量篇幅讲述 Yolo v1,其余算法从简;
Yolo v1 算法性能低于 SSD,后面的 v2 和 v3 是对 v1 的改进;
Yolo 全称 You Only Look Once:Unified ,Real-Time Object Detection;
You Only Look Once 意思就是只看一眼就知道,算法很简单,只需要一次 CNN 运算,Unified 是指一个统一的框架,即 end-to-end,Real-Time 即实时检测,速度快;
滑动窗口
滑动窗口是最原始的目标检测算法,它的思想有助于理解 Yolo。
滑动窗口把检测问题转换成了图像分类问题,基本原理是采用多个不同大小和比例(宽高比)的窗口在整张图片上以一定步长进行滑动,然后对窗口进行图像分类,这样就实现了对整张图片的检测;
这样做的缺点是显而易见的:
1. 无法确定合适的窗口尺寸和步长
2. 产生大量窗口,计算量很大,这样分类器就不能太复杂,因为要保证速度
优化方法之一就是减少窗口,R-CNN 就是这种思路,采用 Selective Search 找到最有可能包含目标的子区域,提升效率;
设计理念
Yolo 其实是进一步减少了 窗口,并且把 分类和检测 结合起来,用一个网络实现

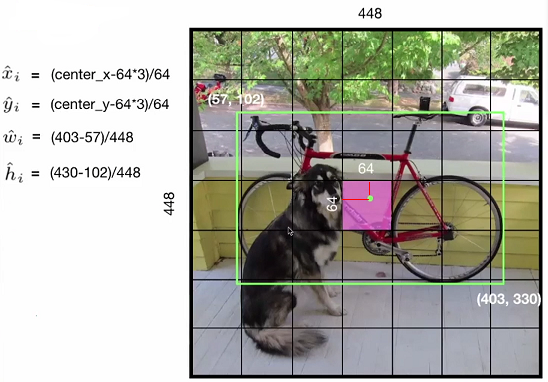
1. 图像被分割成 S x S 个网格,论文中 S=7;每个网格称为 grid cell 或者 cell;
2. 每个 cell 负责预测 object 中心点落在该 cell 内的 object;如上图,虽然很多 cell 都有狗,但是狗的中心只落在了一个 cell,那么只有该 cell 负责预测狗;
3. 每个 cell 生成 B 个 bounding box,简称 bbox,论文中 B=2; 【思考:如何生成 bbox?后续解答】
每个 bbox 需要计算它的 置信度 confidence,选择 confidence 高的 bbox 作为 object 的预测框,即 负责预测的 bbox;
confidence
置信度 confidence 包括两个方面,一是 bbox 含有目标的可能性,记为 Pr(object),当该 cell 包含 object 中心时,Pr(object)=1,否则Pr(object)=0,
bbox 含有目标表示只有包含目标就行,不管是哪个目标;
另一个是 bbox 的准确度,记为 IOUpred thuth ,它表示 bbox 和 ground truth 的 IOU; 【IOU概念不再赘述】
图像中有多个object,每个object有 类别和边框,边框称为 ground truth,代表实际的边框,如上图的红色框;
confidence = 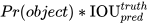
bounding box
bbox 的大小和位置用 4 个值表示 (x,y,w,h) ,(x,y) 代表 bbox 的中心,(w,h) 代表 bbox 的宽和高,
注意,(x,y) 是相对于 cell 左上角坐标的偏移量,并且用 cell 大小做归一化;(w,h) 是相对于整个图片的宽和高的比例;这样 (x,y,w,h) 的大小都在 [0,1] 内
如下图
4. 每个 bbox 的预测值包括 5 个元素,(x,y,w,h,c),c 为置信度;
5. 对于分类问题,每个 cell 需要给出 C 个类别的概率值,论文中 C=20,即共20个类别;
注意,它代表该 cell 中有 object 中心点的条件概率,即 Pr(classi|object);
Pr(classi|object)
他与 bbox 无关,只与 cell 中是否存在 object 中心点有关;
如果 cell 中不存在 object 中心点,那么无需概率;
如果 cell 中有多个 object 的中心点呢?只输出一个 object 的 概率,这是 Yolo v1 的缺点,无法处理 object 密集的目标检测,后面的版本有所改进;
同时我们可以计算边界框类别置信度
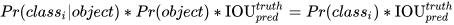
================ 扩展 ================
一张图片最多预测 SxS 个目标
一张图片生成 SxSxB 个 bbox,远远少于 R-CNN
总结
每个图像分为 S x S 个 cell,每个 cell 需要预测 (B*5+C) 个值,最终预测值为 SxSx(B*5+C) 大小的张量
SxSx(B*5+C)

(B*5+C)
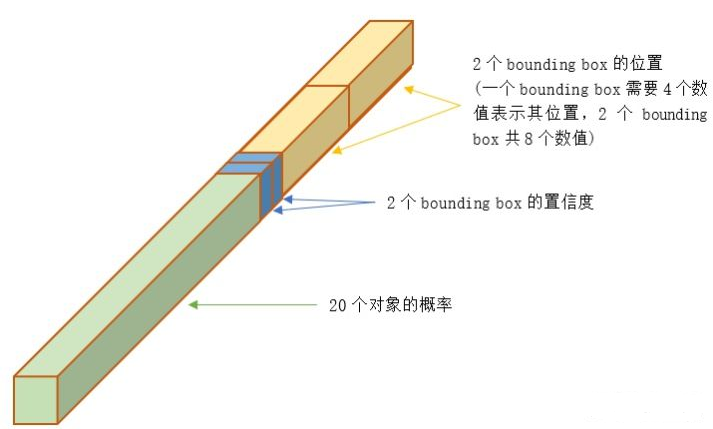
前面 20 个为概率值,中间是 2 个边界框置信度,二者相乘可得到 边界框类别置信度,
后接 8 个 位置元素;
这样排布只是为了方便计算,便于批量提取元素,假设网络输出为 [batch,7x7x30],那么 [:,0:7x7x20] 即为类别概率值,[:,7x7x20:7x7x22] 为边界框置信度,[:,7x7x22:] 位边界框位置
网络设计
Yolo 将目标检测当做回归问题来处理,并且用一个 CNN 网络实现的回归算法;
Yolo 采用卷积提取特征,然后使用全连接得到预测;
网络结构参考 GoogleNet,包括 24 个卷积层和 2 个全连接层;
卷积和全连接的激活函数为 Leaky_Relu,但最后一层采用 线性激活函数
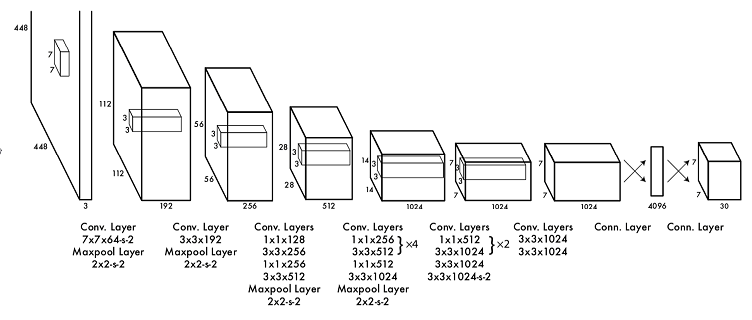
网络主要使用小卷积,1x1,3x3
网络最后的 7x7x30 的张量是为了方便理解,实际网络中是全连接层,7x7x30=1470 个神经元
要注意的是,并不是说仅仅网格内的信息被映射到一个30维向量。经过神经网络对输入图像信息的提取和变换,网格周边的信息也会被识别和整理,最后编码到那个30维向量中。
损失函数
损失函数的设计是 Yolo 算法的核心,公式如下

类别与 bbox 无关,只要 cell 存在 object,无论 bbox 什么样,类别都一样
================ 扩展 ================
bbox 如何生成
在 R-CNN 系列中,网络总是采用各种手段去生成 bbox,而且生成策略非常明确,在 Yolo 中也说要生成 bbox,如何生成却只字未提,很是费解;
首先我一句话回答这个问题,回归出来的,即 wx+b 算出来的,即通过网络算出来的,
实际上在整个算法过程中,并没有像 R-CNN 那样生成 bbox,或者说根本没有 bbox,只是虚构的,bbox 只存在于逻辑上,
在输出层强行虚构出 B 个 bbox,通过 卷积-全连接 权重算出来的,当权重初始化时,bbox 就是瞎猜,最终通过回归算法调整参数得到正确的 bbox;
在 loss 中遍历虚构出的 bbox,计算相关损失
 代表什么
代表什么
i 表示第 i 个 cell,j 表示第 j 个 bbox,obj 表示存在目标,即目标的中心点在 cell 中,
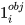 就表示第 i 个 cell 存在目标;
就表示第 i 个 cell 存在目标;
就表示 第 i 个 cell 存在目标,且 它的第 j 个 bbox 负责预测位置;
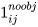 就表示第 i 个 cell 的 第 j 个 bbox 不存在目标;
就表示第 i 个 cell 的 第 j 个 bbox 不存在目标;
有目标为 1, 无目标为 0,

以上图为例 ,在所有 cell 中,只有 3 个粉红色的 cell 存在 object,ΣΣ只有 3 项参与计算,其余全为 0,
ΣΣ 也只有 3 个 cell 参与计算,以自行车对应的 cell 为例,横着的红框 iou 明显大,它就是那个 j,只有这个 bbox 参与计算;
为什么 x y 没有 开方,而 w h 却开方
二者都是以 mes 来计算误差,w h 的特点在于,object 可能有大有小,不同大小的 object 的 bbox w h 尺度就不同,如果一个 object 很小,bbox 稍微大一点小一点,就会显得误差很大,开方就是为了让 w h 变大,因为 w h 都是 归一化的,开方会变大;
0.1 开方为 0.3;0.2 开方为 0.4;0.3 开方为 0.54
C 的真实值如何取,为什么没有目标有需要 C
如果 cell 中不存在目标,Pr(object)=0,C=0;
noobj 项的 C 为 0,但是在训练阶段 所有的 cell 可都是有 bbox 的,我们的目标就是让他的 bbox 尽量小;

如果 cell 中存在目标,Pr(object)=1, IOU=1,C=1,此时是希望预测到最好的的 bbox,当然我们可以设置的稍微小一点,表示预测框差不多就行了;

lambda 如何取值
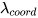 = 5,它代表 坐标误差的权重,之所以它的权重大于 置信度和类别,我的理解是 框对了是前提,框对了才可能正确分类,框错了啥都没了;
= 5,它代表 坐标误差的权重,之所以它的权重大于 置信度和类别,我的理解是 框对了是前提,框对了才可能正确分类,框错了啥都没了;
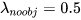 ,它代表 不存在目标的 bbox,之所以 它的权重小于 存在目标的 bbox【1】,是因为大部分 bbox 是不存在目标的,也就是负样本远远多于正样本,类别不均衡,需要降低负样本的权重;
,它代表 不存在目标的 bbox,之所以 它的权重小于 存在目标的 bbox【1】,是因为大部分 bbox 是不存在目标的,也就是负样本远远多于正样本,类别不均衡,需要降低负样本的权重;
靠一个 CNN 真的能预测新目标吗
在训练集上通过 回归 得到 bbox 或许还能理解,但是它真的能泛化到测试集吗?这是一个很感性的问题,其实 Yolo 是一个学习如何画框并把物体框出来的网络,想想人类是如何做的,先看看图像上的实际物体,对应 卷积 的特征提取识别物体,然后开始画框,对应全连接得到边框
模型训练
作者训练的一些细节如下:
1. 预训练:利用 ImageNet 1000 的分类任务预训练卷积层,使用该网络前 20 个卷积层,加上一个 avg_pooling 层,加上一个全连接,对网络进行预训练
卷积层越靠前提取的特征越细,如图像纹理、边缘,越靠后提取的特征越全面,如狗尾巴等,故我们需要的是前面的卷积层参数
2. 将预训练的参数应用到 Yolo 中,并接上 4 个卷积和 2 个全连接;【论文中是这么做的,也可自行设定】
3. 将输入图像的尺寸 resize 到 448 x 448
4. 所有的预测结果都归一化到 [0,1]
5. 使用 Leaky Rule 作为激活函数,只有最后的全连接采用 线性激活函数,因为最后输出有 坐标,为数值型
6. 在第一个全连接后面接了一个 ratio = 0.5 的 Dropout 层
7. 学习率:
模型预测
请注意,在预测时我们可没有什么 ground truth,我们只是得到了一个 SxSx(5*B+C) 的张量,它可能对同一目标有多个预测框,如下图
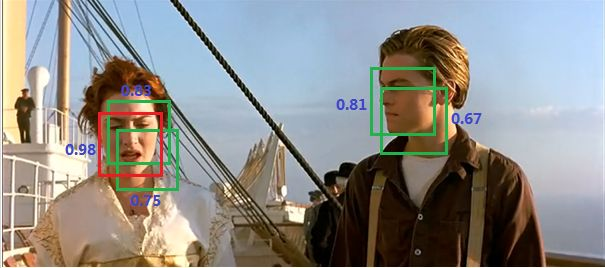
我们需要通过 非极大值抑制 选择最佳 bbox 【非极大值抑制不再赘述】
模型效果

Yolo v1 优缺点
优点
1. 最大的优点就是快
2. one-stage,end-to-end
3. 同时预测多个 物体和 bbox
4. 直接选用整图训练模型,更好的区分目标和背景
缺点
1. 密集物体检测效果不好,或者说 一个 cell 只能预测一个 目标
2. 小物体检测效果不好
3. 检测精度低于 R-CNN
4. 输入尺寸需固定
参考资料:
https://zhuanlan.zhihu.com/p/32525231