论文:《 Inverted Residuals and Linear Bottlenecks Mobile Networks for Classification, Detection and Segmentation 》
链接:https://128.84.21.199/abs/1801.04381
论文代码:https://github.com/shicai/MobileNet-Caffe(非官方)
1、概述:
MobileNet-V2是对MobileNetV1的改进,同样是一个轻量化卷积神经网络。
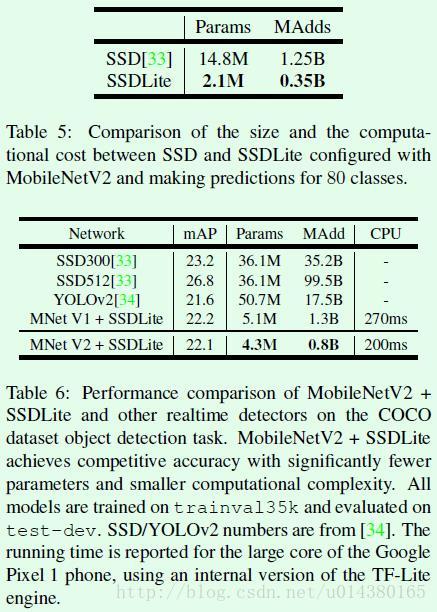
Google 团队在 MobileNet 基础上提出 MobileNetV2,实现分类/目标检测/语义分割多目标任务:以 MobileNetV2 为基础设计目标检测模型 SSDLite(相比 SSD,YOLOv2 参数降低一个数量级,mAP 无显著变化)。
MobileNet-V1 最大的特点就是采用depth-wise separable convolution来减少运算量以及参数量,而在网络结构上,没有采用shortcut的方式。 ResNet及DenseNet等一系列采用shortcut的网络的成功,表明了shortcut是个非常好的东西,作者希望引入shortcut到MobileNet中。
MobileNet的特点就是depth-wise separable convolution,但是直接把depth-wise separable convolution应用到 residual block中,会碰到如下两个问题:
1.DWConv layer层提取得到的特征受限于输入的通道数,若是采用以往的residual block,先“压缩”,再卷积提特征,那么DWConv layer可提取得特征就太少了,因此一开始不“压缩”,MobileNetV2反其道而行,一开始先“扩张”,本文实验“扩张”倍数为6。 通常residual block里面是 “压缩”→“卷积提特征”→“扩张”,MobileNetV2就变成了 “扩张”→“卷积提特征”→ “压缩”,因此称为Inverted residuals。
2.当采用“扩张”→“卷积提特征”→ “压缩”时,在“压缩”之后会碰到一个问题,那就是Relu会破坏特征。为什么这里的Relu会破坏特征呢?这得从Relu的性质说起,Relu对于负的输入,输出全为零;而本来特征就已经被“压缩”,再经过Relu的话,又要“损失”一部分特征,因此这里不采用Relu,实验结果表明这样做是正确的,这就称为Linear bottlenecks。
卷积网络中的feature map被认为在channel维度存在冗余,常利用1x1卷积进行channel数的压缩后再进行3x3可分离卷积的运算。演化过程如下:

观察和设计一个网络时,隐含的会有“状态层”和“变换层”的划分。当上图中c和d的结构堆叠起来时,其事实上是等价的。在这个视角下,我们可以把channel数少的张量看做状态层,而channel数多的张量看做变换层。这种视角下,在网络中传递的特征描述是压缩的,进行新一轮的变换时被映射到channel数相对高的空间上进行运算(文中称这一扩张比例为扩张系数,实际采用的数值为6),之后再压缩回原来的容量。
2、创新点:
创新点:
1、 Inverted residuals,通常的residuals block是先经过一个1*1的Conv layer,把feature map的通道数“压”下来,再经过3*3 Conv layer,最后经过一个1*1 的Conv layer,将feature map 通道数再“扩张”回去。即先“压缩”,最后“扩张”回去。
而 inverted residuals就是 先“扩张”,最后“压缩”。
2、Linear bottlenecks,为了避免Relu对特征的破坏,在residual block的Eltwise sum之前的那个 1*1 Conv 不再采用Relu。
第一点是skip-connection位置的迁移,即从连接channel数多的特征表述迁移为连接channel数少的特征表述。如下图:

第二点是用线性变换层替换channel数较少的层中的ReLU,这样做的理由是ReLU会对channel数低的张量造成较大的信息损耗。我个人的理解是ReLU会使负值置零,channel数较低时会有相对高的概率使某一维度的张量值全为0,即张量的维度减小了,而且这一过程无法恢复。张量维度的减小即意味着特征描述容量的下降。

MobileNet-V1和MobileNet-V2的区别:

1、相同点:
(1)都采用 Depth-wise (DW) 卷积搭配 Point-wise (PW) 卷积的方式来提特征。这两个操作合起来也被称为 Depth-wise Separable Convolution,之前在 Xception 中被广泛使用。这么做的好处是理论上可以成倍的减少卷积层的时间复杂度和空间复杂度。由下式可知,因为卷积核的尺寸 通常远小于输出通道数
,因此标准卷积的计算复杂度近似为 DW + PW 组合卷积的
倍。
2、不同点:(Linear Bottleneck)
(1)V2 在 DW 卷积之前新加了一个 PW 卷积。这么做的原因,是因为 DW 卷积由于本身的计算特性决定它自己没有改变通道数的能力,上一层给它多少通道,它就只能输出多少通道。所以如果上一层给的通道数本身很少的话,DW 也只能很委屈的在低维空间提特征,因此效果不够好。现在 V2 为了改善这个问题,给每个 DW 之前都配备了一个 PW,专门用来升维,定义升维系数 ,这样不管输入通道数
是多是少,经过第一个 PW 升维之后,DW 都是在相对的更高维 (
) 进行着辛勤工作的。
(2)V2 去掉了第二个 PW 的激活函数。论文作者称其为 Linear Bottleneck。这么做的原因,是因为作者认为激活函数在高维空间能够有效的增加非线性,而在低维空间时则会破坏特征,不如线性的效果好。由于第二个 PW 的主要功能就是降维,因此按照上面的理论,降维之后就不宜再使用 ReLU6 了。
MobileNet-V1和MobileNet-V2的区别:

1、相同点:
(1)MobileNet V2 借鉴 ResNet,都采用了 的模式。
(2)MobileNet V2 借鉴 ResNet,同样使用 Shortcut 将输出与输入相加(未在上式画出)
2、不同点:(Inverted Residual Block)
(1)ResNet 使用 标准卷积 提特征,MobileNet 始终使用 DW卷积 提特征。
(2)ResNet 先降维 (0.25倍)、卷积、再升维,而 MobileNet V2 则是 先升维 (6倍)、卷积、再降维。直观的形象上来看,ResNet 的微结构是沙漏形,而 MobileNet V2 则是纺锤形,刚好相反。因此论文作者将 MobileNet V2 的结构称为 Inverted Residual Block。这么做也是因为使用DW卷积而作的适配,希望特征提取能够在高维进行。
可以看到 MobileNetV2 和 ResNet 基本结构很相似。不过 ResNet 是先降维(0.25 倍)、提特征、再升维。而 MobileNetV2 则是先升维(6 倍)、提特征、再降维。
创新点详解:
1、Depthwise Separable Convolutions
首先对每一个通道进行各自的卷积操作,有多少个通道就有多少个过滤器。得到新的通道 feature maps 之后,这时再对这批新的通道 feature maps 进行标准的 1×1 跨通道卷积操作。
标准卷积操作计算复杂度
![]()
,Depthwise Separable Convolutions 计算复杂度
![]()
,复杂度近似较少近似 k*k。
2、 Linear Bottlenecks
本篇文章最难理解的是这部分,论文中有两个结论:
If the manifold of interest remains non-zero volume after ReLU transformation, it corresponds to a linear transformation.
感兴趣区域在 ReLU 之后保持非零,近似认为是线性变换。
ReLU is capable of preserving complete information about the input manifold, but only if the input manifold lies in a low-dimensional subspace of the input space.
ReLU 能够保持输入信息的完整性,但仅限于输入特征位于输入空间的低维子空间中。
对于低纬度空间处理,论文中把 ReLU 近似为线性转换。
3、Inverted residuals
inverted residuals 可以认为是 residual block 的拓展。在 0<t<1,其实就是标准的残差模块。论文中 t 大部分为 6,呈现梭子的外形,而传统残差设计是沙漏形状。
3、模型结构:
论文提出的 MobileNetV2 模型结构容易理解,基本单元 bottleneck 就是 Inverted residuals 模块,所用到的 tricks 比如 Dwise,就是 Depthwise Separable Convolutions,即各通道分别卷积。表 3 所示的分类网络结构输入图像分辨率 224x224,输出是全卷积而非 softmax,k 就是识别目标的类别数目。
1、MobileNetV2:
MobileNetV2 的网络结构中,第 6 行 stride=2,会导致下面通道分辨率变成14x14,从表格看,这个一处应该有误。


这就是之前提到的inverted residuals结构,一个inverted residuals结构的Multiply Add=
h*w*d’ * 1*1*td’ +
h*w*td’ * k*k*1 +
h*w*t d’ * 1*1*d” =
h*w*d’*t(d’+ k*k + d”)
2、MobileNetV1、MobileNetV2 和 ResNet 微结构对比:

可以看到 MobileNetV2 和 ResNet 基本结构很相似。不过 ResNet 是先降维(0.25 倍)、提特征、再升维。而 MobileNetV2 则是先升维(6 倍)、提特征、再降维。
4、实验与总结:
这篇文章提出的MobileNet V2是之前MobileNet V1的改进版。MobileNet V1中主要是引入了depthwise separable convolution代替传统的卷积操作,相当于实现了spatial和channel之间的解耦,达到模型加速的目的,整体网络结构还是延续了VGG网络直上直下的特点,具体可以参考博客:MobileNet。和MobileNet V1相比,MobileNet V2主要的改进有两点:1、Linear Bottlenecks。也就是去掉了小维度输出层后面的非线性激活层,目的是为了保证模型的表达能力。2、Inverted Residual block。该结构和传统residual block中维度先缩减再扩增正好相反,因此shotcut也就变成了连接的是维度缩减后的feature map。
