You Only Look Once
yolo的思想
Yolo算法采用一个单独的CNN模型实现end-to-end的目标检测, 整个系统如图所示: 首先将输入图片resize到448x448, 然后送入CNN网络,最后处理网络预测结果得到检测的目标。 相比R-CNN算法, 其是一个统一的框架, 其速度更快。具体如下:
将输入图像按照模型的输出网格(比如7x7大小)进行划分,划分之后就有很多小cell了。我们再看图片中物体的中心是落在哪个cell里面,落在哪个cell哪个cell就负责预测这个物体。比如下图中,狗的中心落在了红色cell内,则这个cell负责预测狗。

实际上,“物体落在哪个cell,哪个cell就负责预测这个物体” 要分两个阶段来看,包括训练和测试。
yolo整体检测框架
图像输入为448x448,取S=7,B=2,一共有20个类别(C=20)。则输出就是7x7x30的一个tensor。

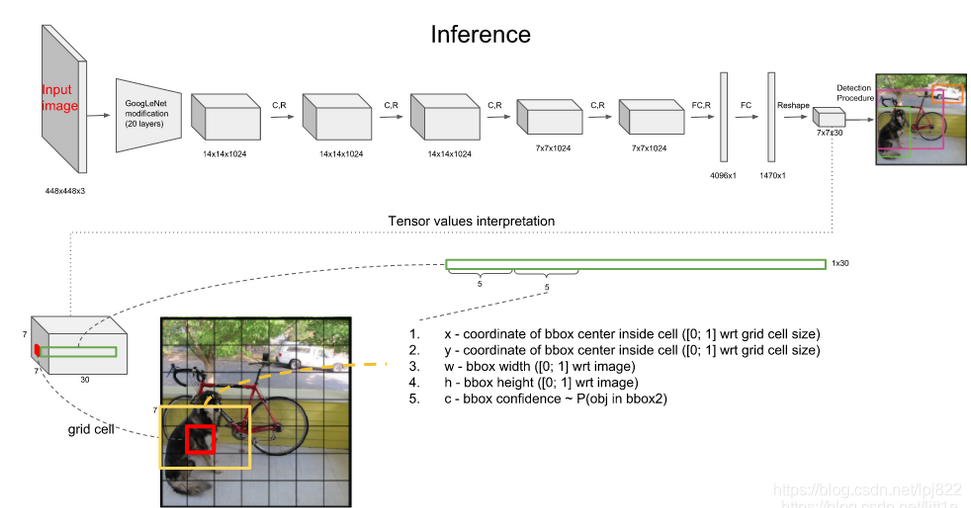
yolo模型架构
 网络结构借鉴了 GoogLeNet 。24个卷积层,2个全链接层。(用1×1 reduction layers 紧跟 3×3 convolutional layers 取代Goolenet的 inception modules )。
网络结构借鉴了 GoogLeNet 。24个卷积层,2个全链接层。(用1×1 reduction layers 紧跟 3×3 convolutional layers 取代Goolenet的 inception modules )。
从图中可以看到,yolo网络的输出的网格是7x7大小的,另外,输出的channel数目为30。一个cell内,前20个元素是类别概率值,然后2个元素是边界框confidence,最后8个元素是边界框的 (x, y,w,h) 。
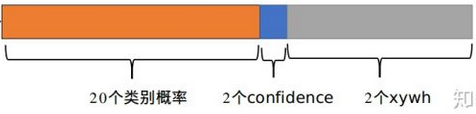
这里为什么有两个边界框,这在训练的时候会在线地计算每个predictor预测的bounding box和ground truth的IOU,计算出来的IOU大的那个predictor,就会负责预测这个物体,另外一个则不预测。这么做有什么好处?我的理解是,这样做的话,实际上有两个predictor来一起进行预测,然后网络会在线选择预测得好的那个predictor(也就是IOU大)来进行预测。通俗一点说,就是我找一堆人来并行地干一件事,然后我选干的最好的那个。
yolo loss
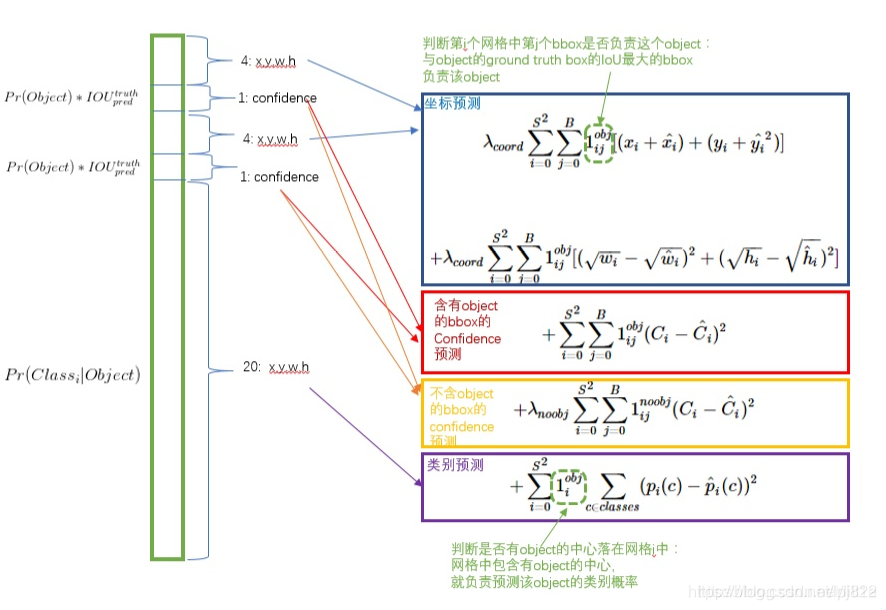
Confidence预测
首先看cell预测的bounding box中condifence这个维度。confidence表示:cell预测的bounding box包含一个物体的置信度有多高并且该bounding box预测准确度有多大,用公式表示为:
Bounding box预测
bounding box的预测包括xywh四个值。xy表示bounding box的中心相对于cell左上角坐标偏移,宽高则是相对于整张图片的宽高进行归一化的。
我们通常做回归问题的时候都会将输出进行归一化,否则可能导致各个输出维度的取值范围差别很大,进而导致训练的时候,网络更关注数值大的维度。因为数值大的维度,算loss相应会比较大,为了让这个loss减小,那么网络就会尽量学习让这个维度loss变小,最终导致区别对待。

类别预测
物体类别是一个条件概率
, 论文中的公式是这样的:
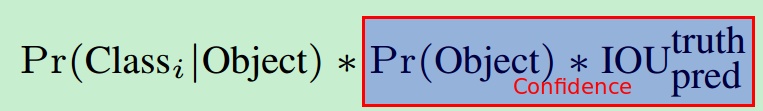 也就是说我们预测的条件概率还要乘以confidence。为什么这么做呢?举个例子,对于某个cell来说,在预测阶段,即使这个cell不存在物体(即confidence的值为0),也存在一种可能:输出的条件概率
,但将confidence和
乘起来就变成0了。这个是很合理的,因为你得确保cell中有物体(即confidence大),你算类别概率才有意义。
也就是说我们预测的条件概率还要乘以confidence。为什么这么做呢?举个例子,对于某个cell来说,在预测阶段,即使这个cell不存在物体(即confidence的值为0),也存在一种可能:输出的条件概率
,但将confidence和
乘起来就变成0了。这个是很合理的,因为你得确保cell中有物体(即confidence大),你算类别概率才有意义。