Yolo(You Only Look Once)是一个end-to-end的目标检测算法。作者在论文中提出,人类的视觉系统是快速和准确的, 人们瞥一眼图像,立即知道图像中的物体是什么,它们在哪里以及它们如何相互作用。而对于Rcnn系列的方法,都是需要先找到有可能有物体的框(anchor box),然后进行前背景分类,nms消除重叠框,重新进行坐标回归和分类,这个流程就比较复杂,并且每个步骤的组件的优化都比较麻烦,无论是训练还是最终的测试,速度都非常慢。
因此,yolo的作者提出,将目标检测的问题转化为一个回归问题,只通过一个步骤就能找到目标的位置。
Yolo的检测步骤:
- 将图像划分成 的网格,如果一个目标物体的中心点落在一个网格中,那么这个网格就负责预测这个目标。
- 每个网格预测B个边框和置信度分数。
- 边框用 表示, 表示目标边框的中心相对于网格的位置(论文里没说是相对于网格的中心还是左上角之类的,实际情况两种应该没什么差别),而 是相对于整个图像的大小。
- 置信度表示预测框与实际框之间的IOU。
- 每个网格还预测 个类的概率 ,也就是在这个网格有物体的情况下,是某个类的概率。值得一提的是,一个网格只预测一组类的概率,和预测的框的数量 没有关系。
- 最终,网络的输出就为 的tensor。
一些细节的讨论:
- yolo的输出就是一个 的tensor,其实最终就是跟了一个全连接,只是人为的将输出划分为有意义的部分。
- 把输入图划分成 的网格很好理解,但是为什么每个网格预测 个框,却只预测了一组类呢?这也是我开始读yolo的时候觉得很奇怪的地方。我们可以设想一下这两种情况:(1)两个或多个同类物体的中心在同一个网格中, (2) 两个或多个不同类物体的中心在同一个网格中。这两种情况,yolo的训练是如何进行的?在参考了一些源码之后,我得出的结论是,yolo放弃了一个网格中预测多个不同类的能力,默认每个网格只能有一个类,这也导致一个网格最多预测出B个同类的框。可以看出来,这种结构也导致了yolo对于密集物体检测效果不好。还有,在训练的时候,如果有多个物体落在同一个网格中,那么yolo只能选择一个(darknet源码把yolo几个版本都杂糅进去,不太好看,但是看了几个其他版本的代码是这样的)。
- 按照作者的说法,预测 个框,可以让每个predictor变得“专业化”,简单来说,每个predictor “擅长”预测特定的大小,方向,或者类别的物体,这有助于提高整体的recall。
- yolo在优化框的时候,坐标使用平方和误差,对于宽和高同样使用平方和误差,但是优化的目标从 改为 ,作者的解释是,对于同样小的误差来说,小的框有这种误差远比大的框有这种误差要更糟糕一些,所以取了平方根,期望能够在框的size小的时候能有相对较大的loss。
- 关于置信度, 给出的置信度包含了两部分,一个是该box包含物体的可能性,另一个是这个box框的有多准。用公式来描述就是: 。
- 最后测试的时候,用置信度乘分类概率,一个框就可以得到一个特定的置信度分数,这个分数代表了某类在框中的概率以及框的准确率。用公式描述就是:
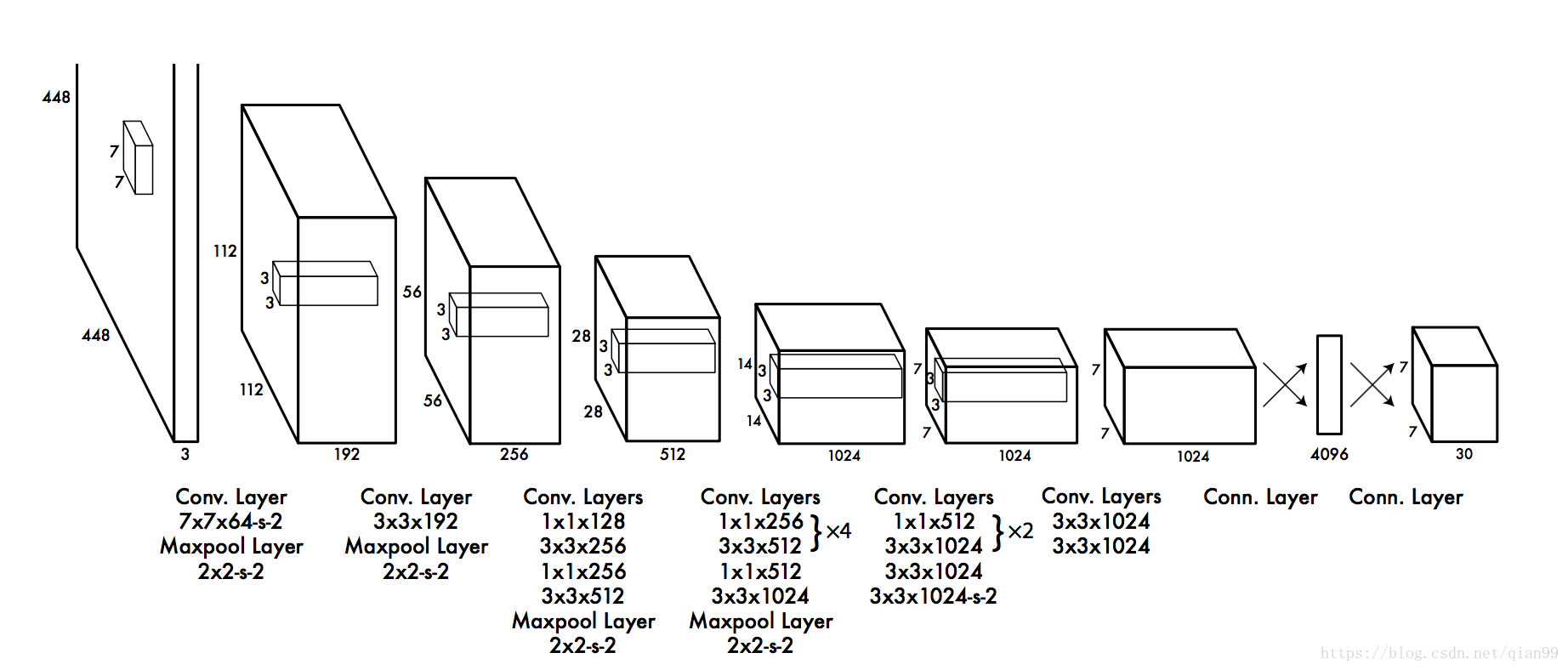
网络结构与训练
下图就是yolo的网络结构,其中
在训练yolo的时候,作者发现,大部分的网格中是没有物体的,这就导致了,训练中,这些网格的梯度“主导”了整个训练,导致一开始,置信度都趋向于0,模型很容易就“训飞”。
因此,在训练的时候,作者对这两部分loss进行了加权,边框预测的loss,参数为 , 不包含物体的部分的loss,参数为 。
下面是训练的损失函数:
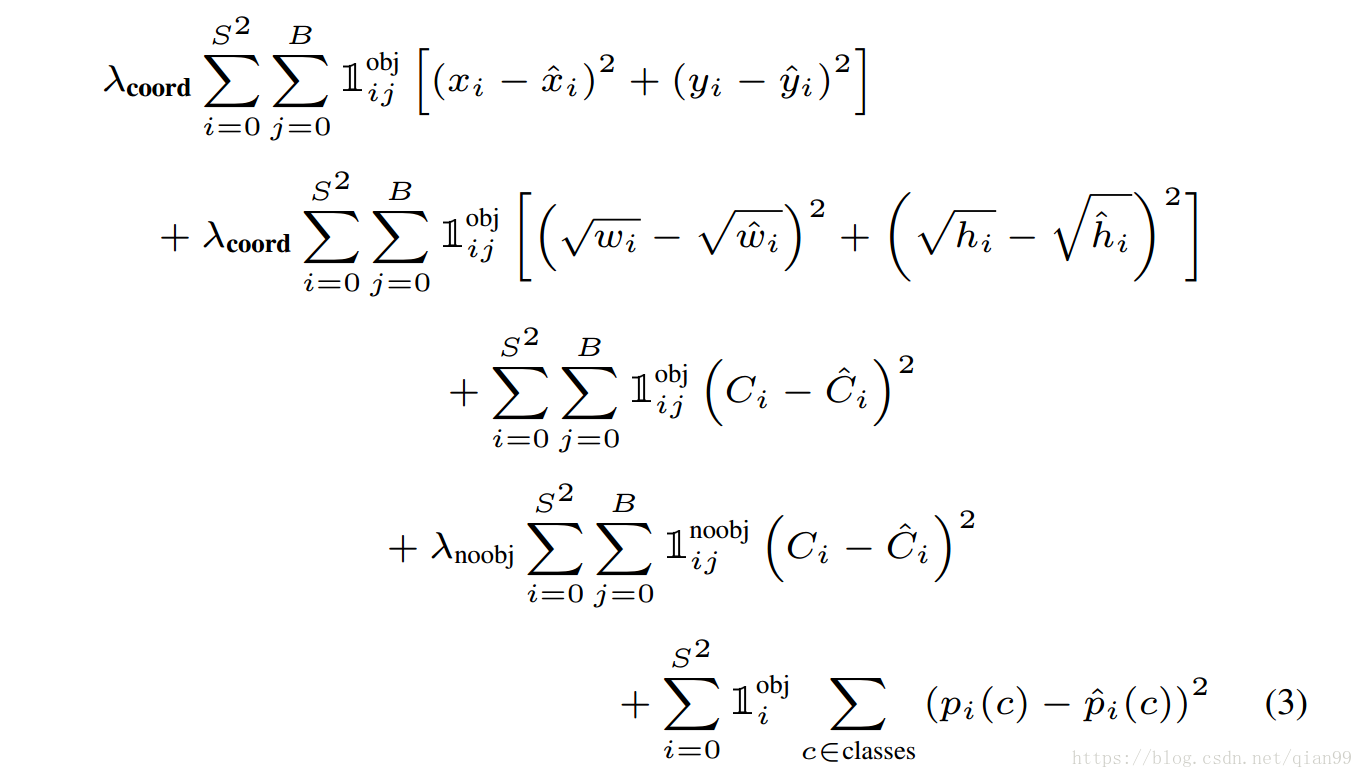
其中, 表示,在第 个网格,由 负责的框中是否有物体。 表示,在第 个网格,由 负责的框中是否没有物体。 表示,在第 个网格中是否存在物体。对于第三行,也就是在这个框内有物体的时候,预测分类没问题,但是第四行,这个框内就没有物体,这时ground truth的分类是什么呢?参考代码,我的结论是,这里的ground truth是不属于任何类,这不代表我们要把分类的数量增加一个维度。在神经网络中,分类的输出通常用one hot 编码表示,也就是一个 的向量,第 类就让 为1来表示,因此,上面说的不属于任何类,就可以让这个向量的值全为0就好了。