YOLO v1
网络结构:VGG16 + YOLO检测头
[ [conv + leaky_relu]*n + maxPooling ]*n + FC -->> 7×7×30

1次下采样通过conv s=2实现,5次下采样通过maxpooling实现,感受野2^ (1+5) = 64×64。
VGG16结构如下图第C列:
 输出形状的理解:7×7代表映射到输入图像后,分为7×7个格子;30代表20+5+5;两个5代表一个grid预测两个bounding box,5代表预测出的xywhc,xywh即box信息,c为置信度;若该bounding box负责预测物体则理想的c为该框与gt框的iou,若该框不预测物体理想值为0;20代表该grid的预测类别(可以当成one-hot形式),不难看出每个grid的两个框共用一个类别,因此对于靠的比较近的不同类别的物体检测效果不行(其实相同类别也不行,后面会解释)。损失函数:包含三部分,分别是 坐标回归损失、置信度损失、分类损失。都是直接暴力计算均方损失,直接搬运子豪兄的过来
输出形状的理解:7×7代表映射到输入图像后,分为7×7个格子;30代表20+5+5;两个5代表一个grid预测两个bounding box,5代表预测出的xywhc,xywh即box信息,c为置信度;若该bounding box负责预测物体则理想的c为该框与gt框的iou,若该框不预测物体理想值为0;20代表该grid的预测类别(可以当成one-hot形式),不难看出每个grid的两个框共用一个类别,因此对于靠的比较近的不同类别的物体检测效果不行(其实相同类别也不行,后面会解释)。损失函数:包含三部分,分别是 坐标回归损失、置信度损失、分类损失。都是直接暴力计算均方损失,直接搬运子豪兄的过来
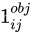
关于上面这个东西的意义:若第i个grid的第j个bouding box负责预测物体,则为1,否则为0;
bouding box负责预测物体的定义:若gt框的中心落在了一个grid cell内,则该grid的两个bounding box中有一个负责预测该物体,分别计算两个预测出的bounding box与该gt框的iou,iou大的框负责预测,则该符号值为1,否则为0。(即一个grid的两个框最多只有一个会预测物体,所以同类别的两个目标比较近的时候(两个gt框的中心落在一个grid cell中),对不起v1只能检测出一个)
网络特点:
- 使用了dropout,没用BN层;(模型太老了)
- 除了最后一层的conv使用普通relu,之前的层都是用leaky_relu;
- 通过maxpooling实现下采样;
- 后面通过又笨又慢的FC层实现特征融合
- backbone使用的是VGG-16或者GoogleNet(v2才有自家的darkent)
优点: 快!!
缺点:
- mAP低于RCNN系列
- 精确定位性能较差
- 对小目标、密集目标检测效果差(最多检测49个目标)->recall低