目标检测系列(六):YOLO v1
References:
- https://blog.csdn.net/hrsstudy/article/details/70305791
- https://blog.csdn.net/surgewong/article/details/51864859
《You Only Look Once: Unified, Real-Time Object Detection》
STAR
S: YOLO之前的物体检测方法主要是通过region proposal产生大量的可能包含待检测物体的 potential bounding box,再用分类器去判断每个 bounding box里是否包含有物体,以及物体所属类别的 probability或者 confidence,如R-CNN,Fast-R-CNN,Faster-R-CNN等.总之就是一个分类的问题。
T: 是否可以看作是回归的问题?
A: 将物体检测任务当做一个regression问题来处理,使用一个神经网络,直接从一整张图像来预测出bounding box 的坐标、box中包含物体的置信度和物体的probabilities。因为YOLO的物体检测流程是在一个神经网络里完成的,所以可以end to end来优化物体检测性能。
R: 检测物体速度很快,不容易出现FP(考虑到YOLO用的是全图作为输入,而且更能学到更加抽象的特征,方便进行迁移), 但是定位容易出现错误。
1. Introduction
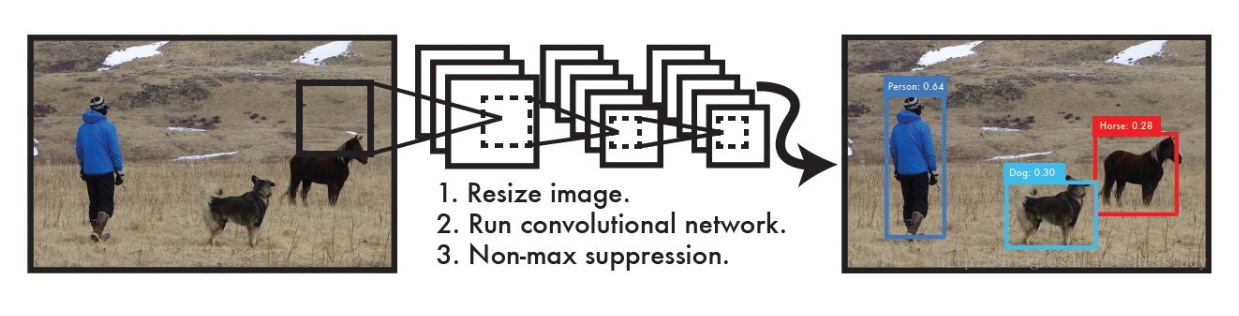
如图所示,使用YOLO来检测物体,其流程是非常简单明了的:
1、将图像resize到448 * 448作为神经网络的输入
2、运行神经网络,得到一些bounding box坐标、box中包含物体的置信度和class probabilities
3、进行非极大值抑制,筛选Boxes
截止至今各物体检测系统的检测流程与性能对比:
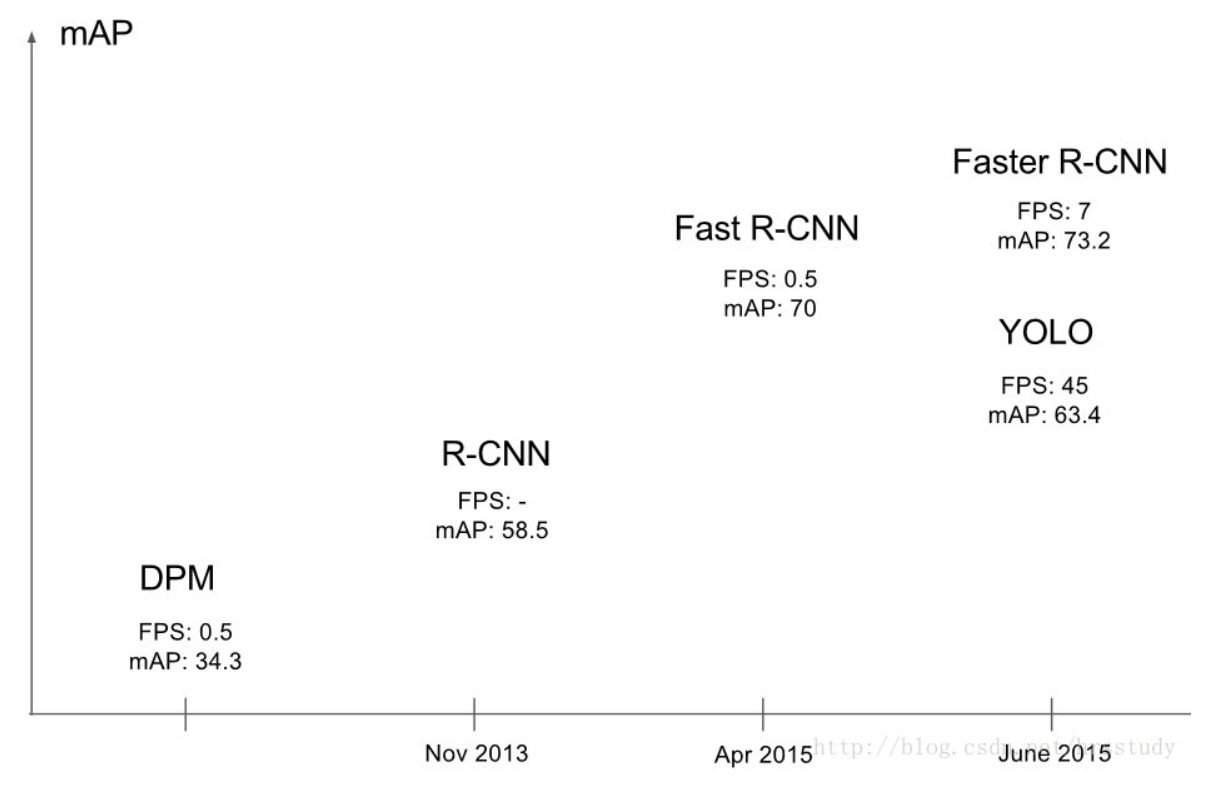
注:不是所有的物体检测系统都可以满足实时性要求!!!
YOLO VS 之前物体检测方法
优点
-
YOLO检测物体非常快。
因为没有复杂的检测流程,只需要将图像输入到神经网络就可以得到检测结果,YOLO可以非常快的完成物体检测任务。标准版本的YOLO在Titan X 的 GPU 上能达到45 FPS。更快的Fast YOLO检测速度可以达到155 FPS。而且,YOLO的mAP是之前其他实时物体检测系统的两倍以上。(意思指的是虽然一些检测系统的MAP比较高,但是仍不能满足实时性要求,此时在满足实时性需求的系统内,YOLO的MAP相对较高) -
YOLO可以很好的避免背景错误,产生false positives。
不像其他物体检测系统使用了滑窗或region proposal,分类器只能得到图像的局部信息。YOLO在训练和测试时都能够看到一整张图像的信息,因此YOLO在检测物体时能很好的利用上下文信息,从而不容易在背景上预测出错误的物体信息。和Fast-R-CNN相比,YOLO的背景错误不到Fast-R-CNN的一半。 -
YOLO可以学到物体的泛化特征。
当YOLO在自然图像上做训练,在艺术作品上做测试时,YOLO表现的性能比DPM、R-CNN等之前的物体检测系统要好很多。因为YOLO可以学习到高度泛化的特征,从而迁移到其他领域。(我觉得这个很牵强,可能是因为其他的检测系统都在抽取特征后,在ROI区域进行了Fine-tuning)
缺点
- YOLO的物体检测精度低于其他state-of-the-art的物体检测系统。
- YOLO容易产生物体的定位错误。
- YOLO对小物体的检测效果不好(尤其是密集的小物体,因为一个栅格只能预测2个物体)。
2. Unified Detection

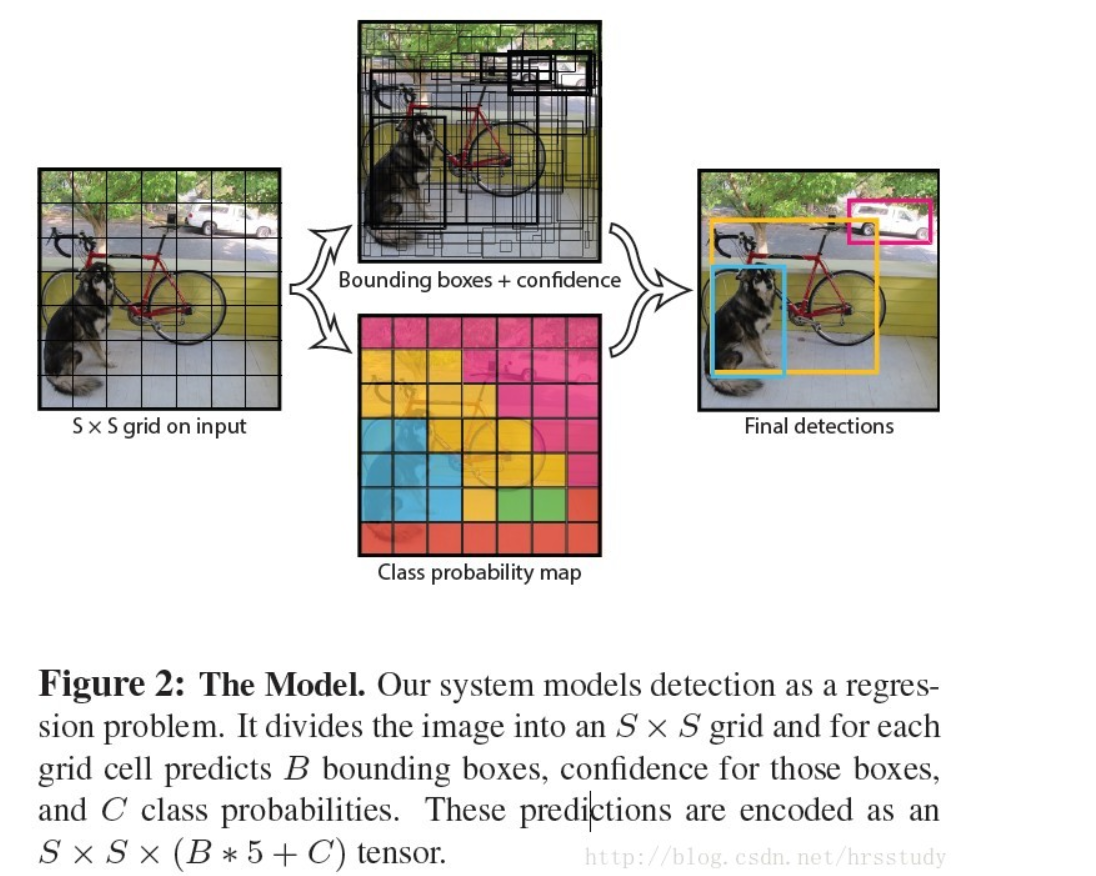
如上图所示,YOLO将输入图像划分为SS的栅格,每个栅格负责检测中心落在该栅格中的物体(也就是该栅格对应回原图的话,ground truth 与之对应)。每一个栅格预测**B个bounding boxes***,以及这些***bounding boxes的confidence scores***。

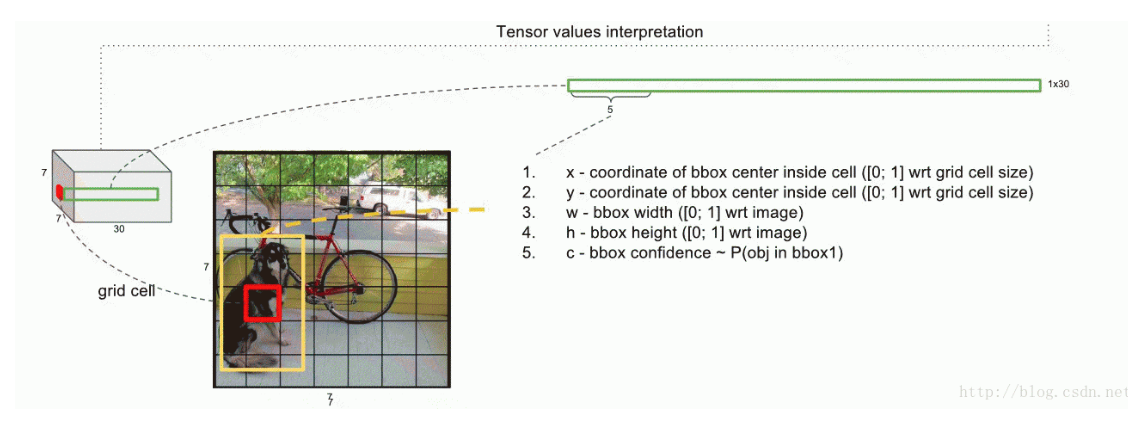
每一个栅格还要预测***C个 conditional class probability***(条件类别概率):Pr(Classi|Object)。即在一个栅格包含一个Object的前提下,它属于某个类的概率。 我们只为每个栅格预测一组(C个)类概率,而不考虑框B的数量。
在测试阶段,将每个栅格的conditional class probabilities与每个 bounding box的 confidence相乘:
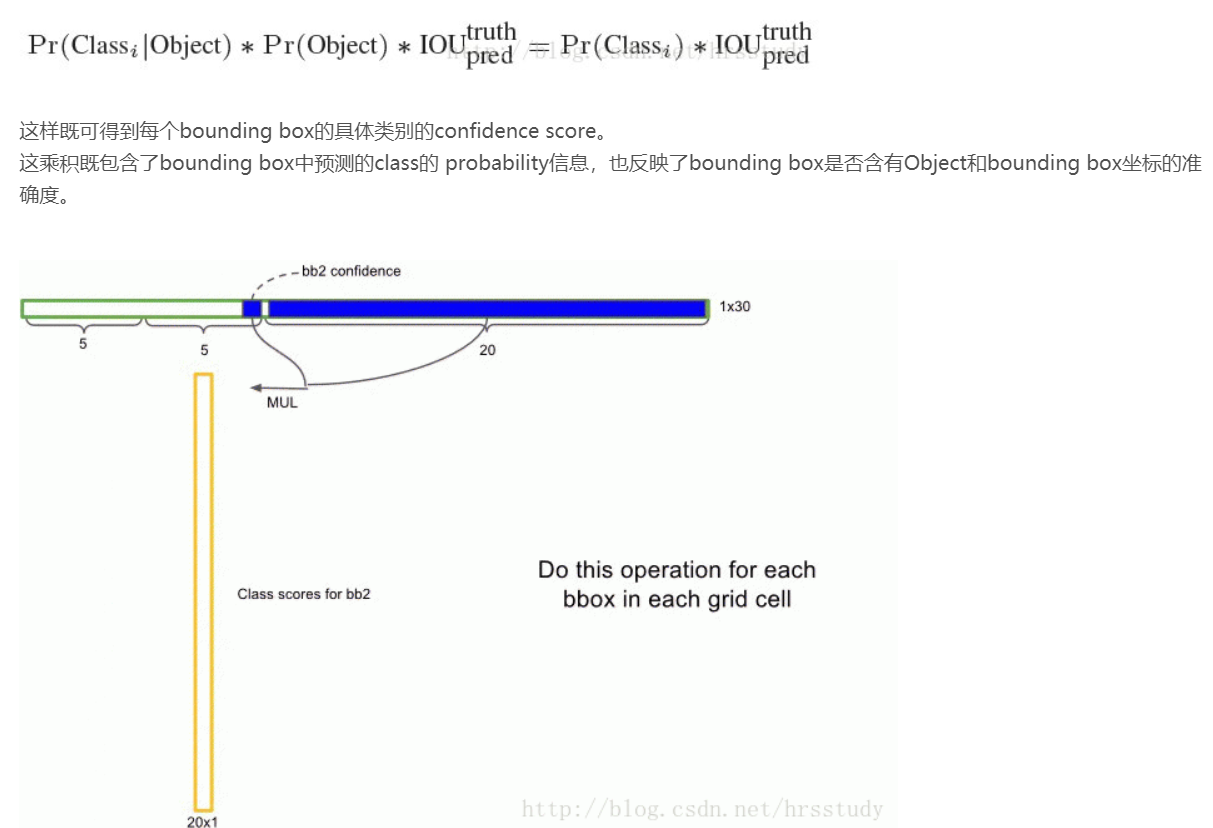
举例:
将YOLO用于PASCAL VOC数据集时:
论文使用的 S=7,即将一张图像分为7×7=49个栅格每一个栅格预测B=2个boxes(每个box有 x,y,w,h,confidence,5个预测值),同时C=20(PASCAL数据集中有20个类别)。
因此,最后的prediction是7×7×30 { 即S * S * ( B * 5 + C) }的Tensor。
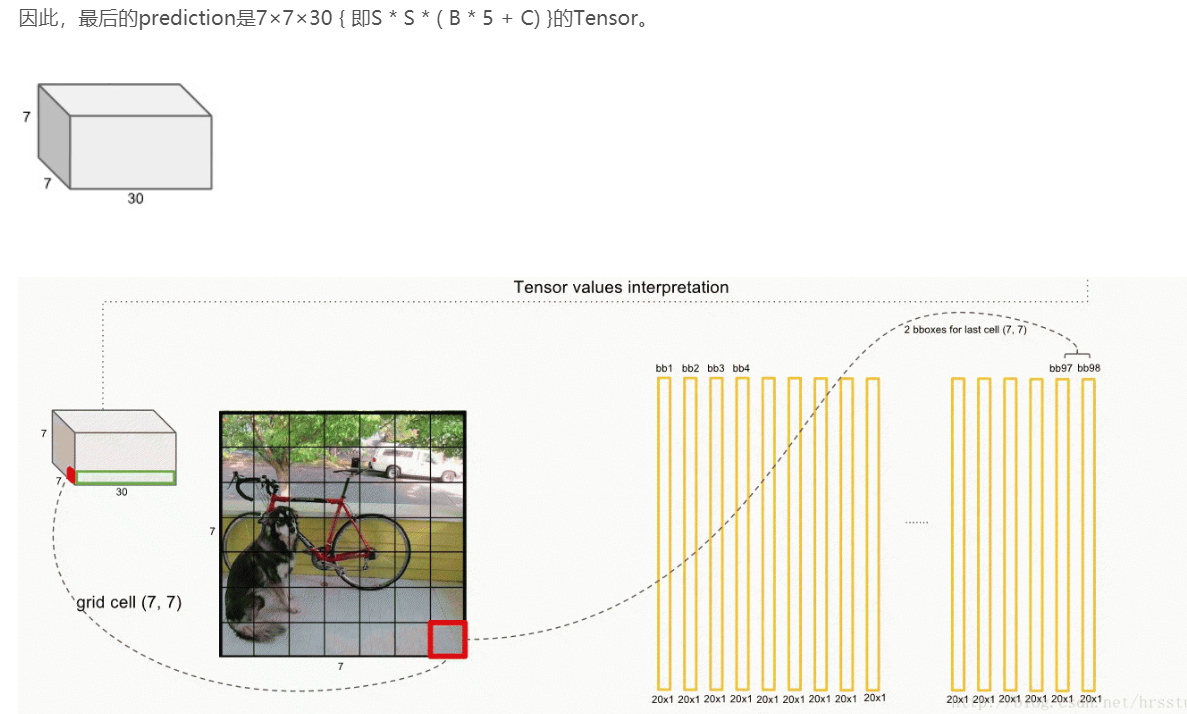
整体流程如下图所示:
3. Network Design
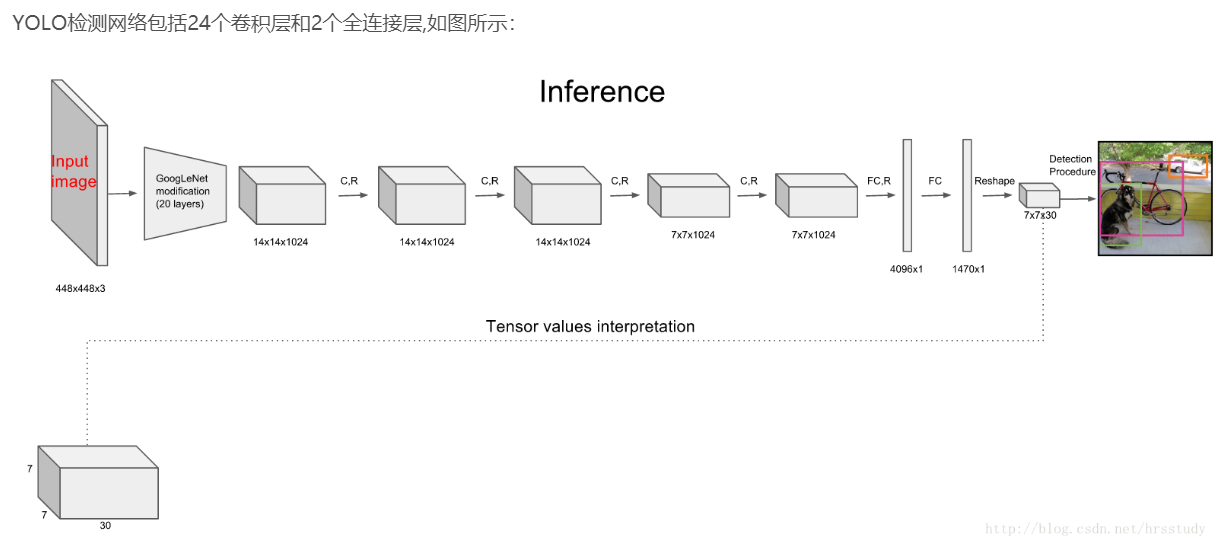
该网络结构包括 24 个卷积层,最后接 2 个全连接层。文章设计的网络借鉴 GoogleNet 的思想,在每个 1∗1 的 归约层(Reduction layer) 之后再接一个 3∗3 的卷积层的结构替代 Inception结构。其中,卷积层用来提取特征, 全连接层用来预测图像位置和类别概率值。
4. YOLO 训练
- 首先利用 ImageNet 的数据集 Pretrain 卷积层。使用上述网络中的前 20 个卷积层,外加一个全连接层,作为 Pretrain 的网络,训练大约一周的时间,使得在 ImageNet 2012 的验证数据集 Top-5 的准确度达到 88%,这个结果跟 GoogleNet 的效果相当。
- 将 Pretrain 的结果应用到 Detection 中,将剩下的 4 个卷积层及 2 个全连接成加入到 Pretrain 的网络中。同时为了获取更精细化的结果,将输入图像的分辨率由 224224 提升到 448448。
- 将所有的预测结果都归一化到 0~1, 使用 Leaky RELU 作为激活函数。
- 对比 localization error 和 classification error,加大 localization 的权重
- 在 Pascal VOC 2007 和 2012 上训练 135 个 epochs, Batchsize 设置为 64, Momentum 为 0.9, Decay 为 0.0005.
- 在第一个 epoch 中 学习率是逐渐从 10−310−3 增大到 10−210−2,然后保持学习率为 10−210−2,一直训练到 75个 epochs,然后学习率为 10−310−3 训练 30 个 epochs,最后 学习率为 10−410−4 训练 30 个 epochs。
- 为了防止过拟合,在第一个全连接层后面接了一个 ratio=0.5ratio=0.5 的 Dropout 层。并且对原始图像做了一些随机采样和缩放,甚至对调节图像的在 HSV 空间的饱和度。
5. 损失函数
两个目标:
(1)坐标(x,y,w,h),confidence,classification 这个三个方面达到很好的平衡;
(2)不同大小的bbox预测中,相比于大bbox预测偏一点,小box预测偏相同的尺寸对IOU的影响更大。
解决方案(1):
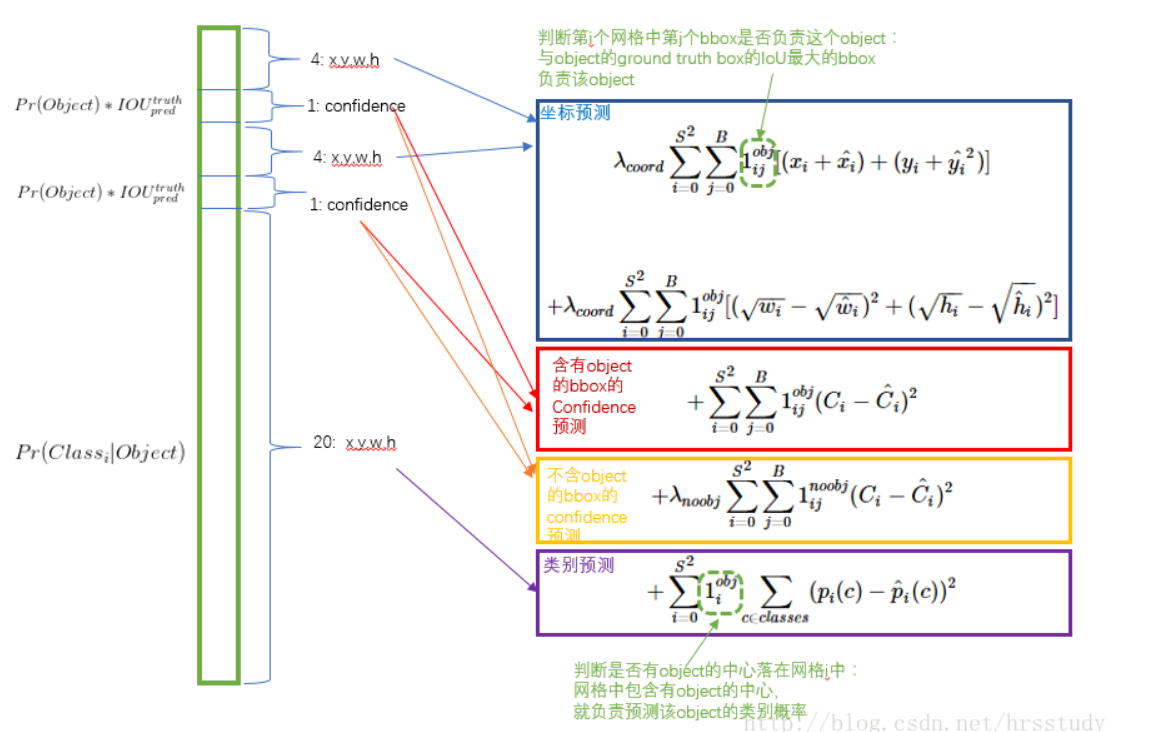
- 更重视8维的坐标预测,给这些损失前面赋予更大的loss weight, 记为 λcoord ,在pascal VOC训练中取5。(上图蓝色框)
- 对没有object的bbox的confidence loss,赋予小的loss weight,记为 λnoobj ,在pascal VOC训练中取0.5。(上图橙色框)
- 有object的bbox的confidence loss (上图红色框) 和类别的loss (上图紫色框)的loss weight正常取1。
总而言之:对坐标预测赋予更大权重,让不包含物体的bbox的confidence赋予更小权重,其他保持不变(已经通过相对值实现了目的)
解决方案(2):
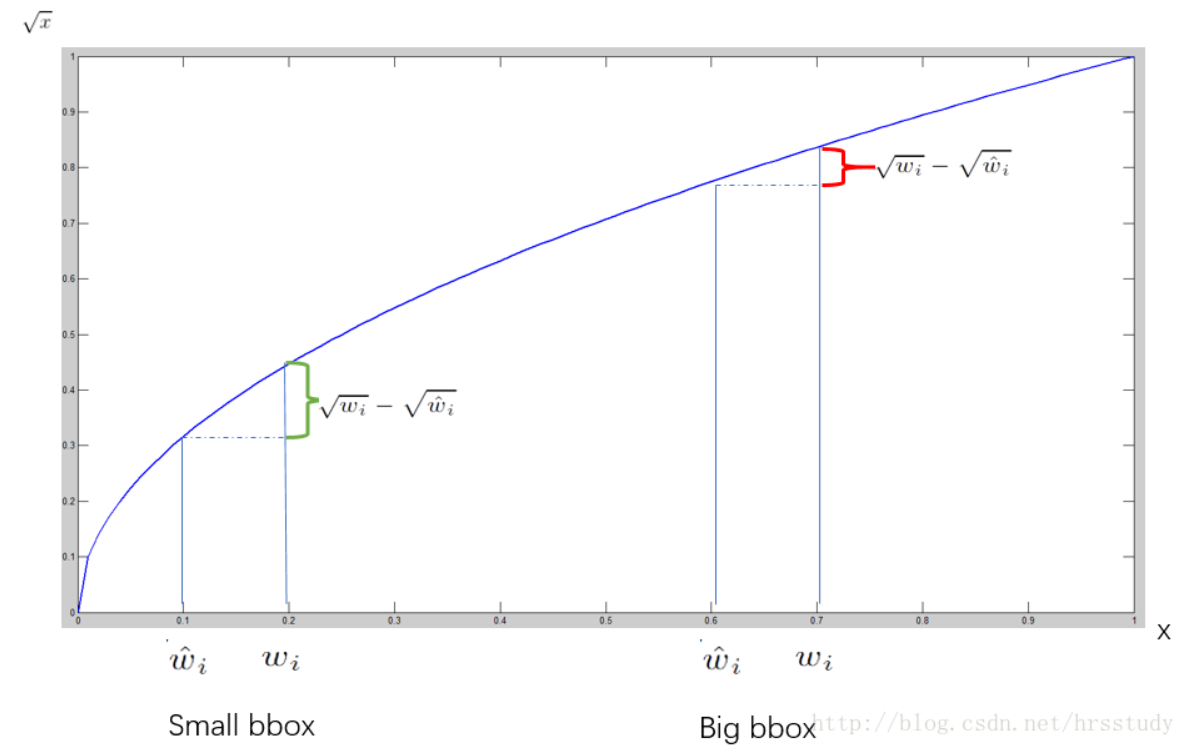
- 如果只是简单的相减取平方的话,大box 与小box 偏差对IOU的影响则一致,因此为了实现小box 产生更大影响的目的,作者用了一个巧妙的办法,就是将box的width和height取平方根代替原本的height和width。 如上图所示:small bbox的横轴值较小,发生偏移时,反应到y轴上的loss(绿色)比big box(红色)要大。
在 YOLO中,每个栅格预测多个bounding box,但在网络模型的训练中,希望每一个物体最后由一个bounding box predictor来负责预测。
因此,当前哪一个predictor预测的bounding box与ground truth box的IOU最大,这个 predictor就负责 predict object。
这会使得每个predictor可以专门的负责特定的物体检测。随着训练的进行,每一个 predictor对特定的物体尺寸、长宽比的物体的类别的预测会越来越好。(难道不应该是随着用各种各样的图片[即物体在该图片的不同位置]训练后,每一个predictior 都不特定嘛?)
6. YOLO 输出后的检测流程
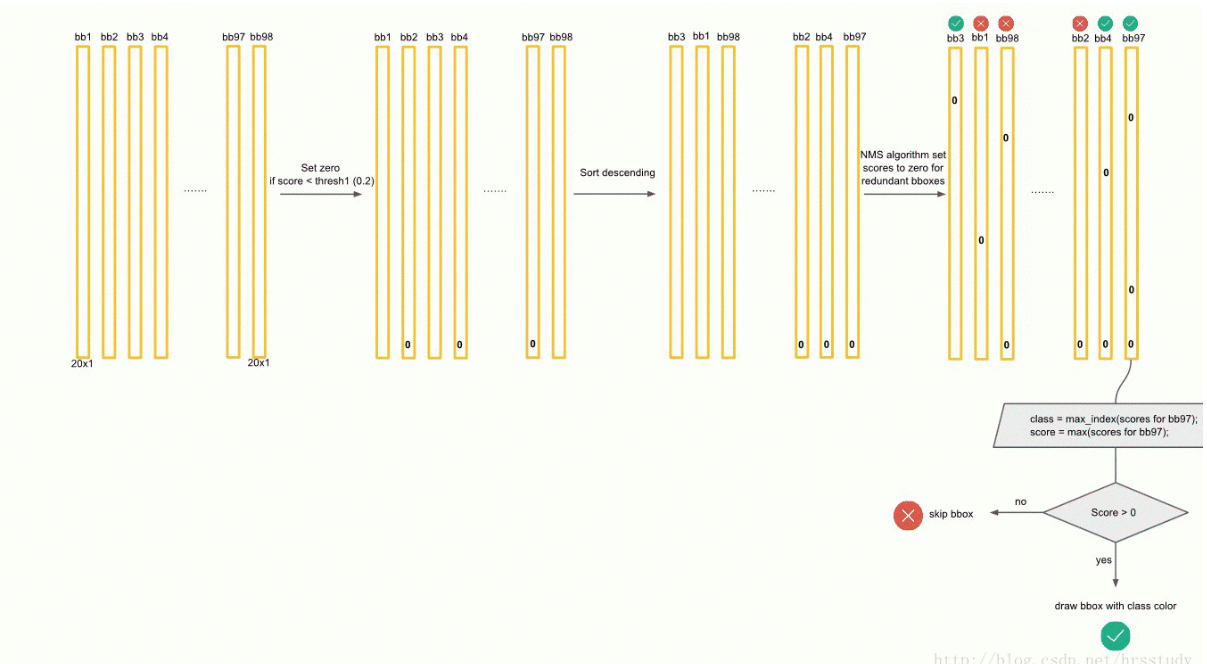
仍然伴随着非极大值抑制(NMS)。
7. YOLO性能评价
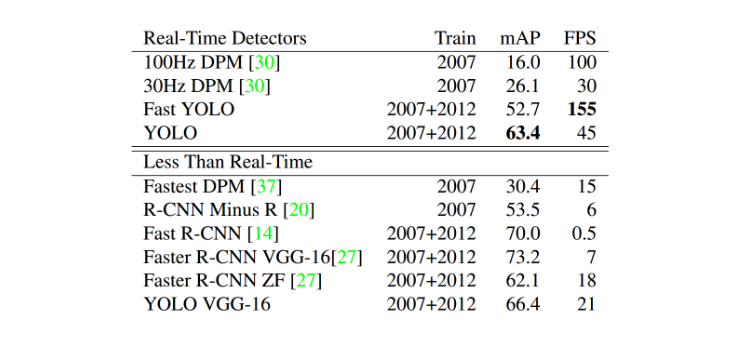
从实验结果上来看,Yolo在速度上有很大的优势,在 mAP 与 state of art 的结果还有不少差距。
8. YOLO的问题
- 每个 grid 只预测一个类别的 Bounding Boxes,而且最后只取置信度最大的那个 Box。这就导致如果多个不同物体(或者同类物体的不同实体)的中心落在同一个网格中,会造成漏检。
- 预测的 Box 对于尺度的变化比较敏感,在尺度上的泛化能力比较差。
如需转载请注明出处,谢谢!