目录
0 引言
两阶经典检测器(Faster RCNN)利用两阶结构,先实现感兴趣区域的生成,再进行精细的分类与回归,虽出色地完成了物体检测任务,但也限制了其速度。
YOLO v1算法利用回归的思想,使用一阶网络直接完成了分类与位置定位两个任务,速度极快。
YOLO v2与v3在检测精度与速度上有了进一步的提升。
1 YOLO v1
2015年诞生的YOLO v1(无锚框)使用一阶结构完成了物体检测任务,直接预测物体的类别与位置,没有RPN网络,也没有类似于锚框(Anchor)的预选框,因此速度很快。
1.1 网络结构
YOLO v1网络结构如图所示,该结构与GoogLeNet模型类似。首先利用卷积神经网络进行特征提取,其输入图像的尺寸固定为448×448,经过24个卷积层与两个全连接层后,最后输出的特征图大小为7×7×30。


注:
(1)在3×3的卷积后通常会接一个通道数更低的1×1卷积,这种方式既降低了计算量,同时也提升了模型的非线性能力。
(2)除了最后一层使用了线性激活函数外,其余层的激活函数为Leaky ReLU。
(3)在训练中使用了Dropout与数据增强的方法来防止过拟合。
1.2 特征图
YOLO v1的网络结构精髓主要在最后7×7×30大小的特征图中。
YOLO v1将输入图像划分成7×7的区域,每一个区域对应于最后特征图上的一个点,该点的通道数为30,代表了预测的30个特征。
YOLO v1在每一个区域内预测两个边框,这些边框大小与位置各不相同,基本可以覆盖整个图上可能出现的物体。
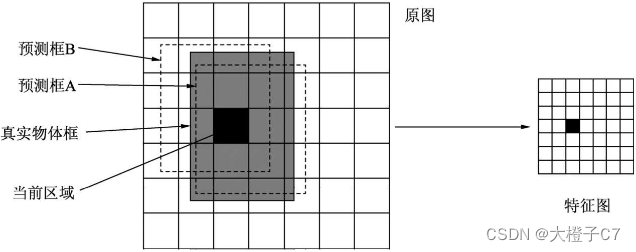
检测原理:如果一个物体的中心点落在了某个区域内,则该区域就负责检测该物体。具体是将该区域的两个框与真实物体框进行匹配,IoU更大的框负责回归该真实物体框。
注:
(1)YOLO v1没有先验框,而是直接在每个区域预测框的大小与位置,是一个回归问题。能够成功检测的原因在于,区域本身就包含了一定的位置信息,另外被检测物体的尺度在一个可以回归的范围内。
(2)YOLO v1采用了物体类别与置信度分开的预测方法
(3)在训练时选取与物体IoU更大的一个边框,在测试时选取置信度(表示该区域内是否包含物体的概率)更高的一个边框。
1.3 损失函数
YOLO v1的损失使用均方差。公式中:
i代表第几个区域,一共有S平方个区域,在此为49; j代表某个区域的第几个预测边框,一共有B个预测框,在此为2; obj代表该框对应了真实物体;noobj代表该框没有对应真实物体。
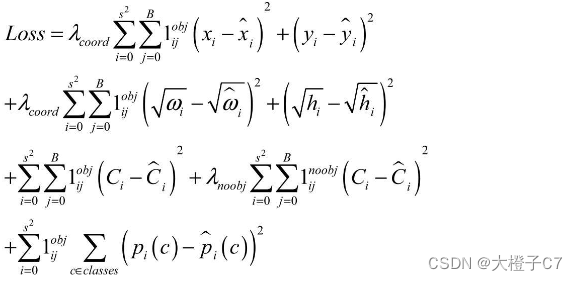
公式中各项的含义:
第一项为正样本中心点坐标的损失。λcoord的目的是为了调节位置损失的权重,YOLO v1设置λcoord为5,调高了位置损失的权重。
第二项为正样本宽高的损失。由于宽高差值受物体尺度的影响,因此这里先对宽高进行了平方根处理,在一定程度上降低对尺度的敏感,强化了小物体的损失权重。
第三、四项分别为正样本与负样本的置信度损失,正样本置信度真值为1,负样本置信度为0。λnoobj默认为0.5,目的是调低负样本置信度损失的权重。
第五项为正样本的类别损失。
1.4 YOLO v1缺点
(1)模型对于小物体,以及靠得特别近的物体检测效果不好。
(2)无锚框导致模型对于新的或者不常见宽高比例的物体检测效果不好。
(3)由于下采样率较大,边框的检测精度不高。
(4)在损失函数中,大物体与小物体的位置损失权重是一样的,会带来物体定位的不准确。
2 YOLO v2
2016年诞生了YOLO v2(依赖锚框),在网络结构的改善、先验框的设计及训练技巧等方面做了改进,使其预测更加精准、速度更快、识别的物体类别也更多。
2.1 网络结构的改善
YOLO v2提出了一个全新的网络结构DarkNet。原始的DarkNet拥有19个卷积层与5个池化层,在增加了一个Passthrough层后一共拥有22个卷积层,精度与VGGNet相当,但浮点运算量只有VGGNet的1/5左右,因此速度极快,其网络结构如图所示。

相比v1的基础网络,DarkNet进行的改进:
(1)BN层:DarkNet使用了BN层,这一点带来了2%以上的性能提升。BN层有助于解决反向传播中的梯度消失与爆炸问题,可以加速模型的收敛,同时起到一定的正则化作用。BN层的具体位置是在每一个卷积之后,激活函数LeakyReLU之前。
(2)用连续3×3卷积替代了v1版本中的7×7卷积,既减少了计算量,又增加了网络深度。此外,DarkNet去掉了全连接层与Dropout层。
(3)Passthrough层:DarkNet还进行了深浅层特征的融合,具体方法是将浅层26×26×512的特征变换为13×13×2048,这样就可以直接与深层13×13×1024的特征进行通道拼接。这种特征融合有利于小物体的检测,也为模型带来了1%的性能提升。
(4)YOLO v2在每一个区域预测5个边框,每个边框有25个预测值,因此最后输出的特征图通道数为125。其中,一个边框的25个预测值分别是20个类别预测、4个位置预测及1个置信度预测值。
2.2 先验框的设计
YOLO v2吸收了Faster RCNN的优点,设置了一定数量的预选框,使得模型不需要直接预测物体尺度与坐标,只需要预测先验框到真实物体的偏移,降低了预测难度。
YOLO v2使用聚类的算法来确定先验框的尺度,并且优化了后续的偏移计算方法。先验框的设计使得召回率提升。
(1)聚类提取先验框尺度
YOLO v2通过在训练集上聚类来获得预选框,只需要设定预选框的数量k,就可以利用聚类算法得到最适合的k个框。
(2)优化偏移公式
有了先验框后,YOLO v2不再直接预测边框的位置坐标,而是预测先验框与真实物体的偏移量。
图中实线框代表预测框,虚线框代表先验框:
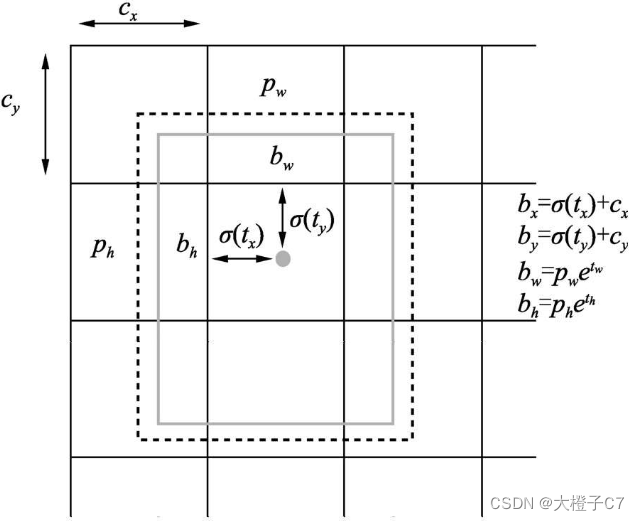
pw与ph表示当前先验框的宽高;cx与cy表示中心点所处区域左上角的坐标;σ(tx)与σ(ty)代表预测框中心点与中心点所处区域左上角坐标的距离;bx与by表示预测框的中心坐标;tw与th为预测的宽高偏移量。
σ代表Sigmoid函数,作用是将坐标偏移量化到(0, 1)区间,这样得到的预测边框的中心坐标bx、by会限制在当前区域内,保证一个区域只预测中心点在该区域内的物体,有利于模型收敛。
2.3 损失函数
由于利用了先验框,YOLO v2的损失函数也相应的进行了改变。

2.4 训练技巧
(1)多尺度训练
由于移除了全连接层,因此YOLO v2可以接受任意尺寸的输入图片。在训练阶段,为了使模型对于不同尺度的物体鲁棒,YOLO v2采取了多种尺度的图片作为训练的输入。训练出的模型可以适应多种不同的场景要求。
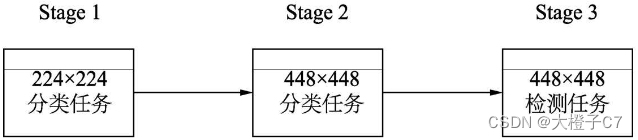
(2)多阶段训练
a.利用DarkNet网络在ImageNet上预训练分类任务,图像尺度为224×224。
b.将ImageNet图片放大到448×448,继续训练分类任务,让模型首先适应变化的尺度。
c.去掉分类卷积层,在DarkNet上增加Passthrough层及3个卷积层,利用尺度为448×448的输入图像完成物体检测的训练。
2.5特点
(1)使用了先验框、特征融合等方法,同时利用了多种训练技巧,使得模型在保持极快速度的同时大幅度提升了检测的精度。
(2)没有很好地解决小物体的检测问题。
3 YOLO v3
2018年推出的YOLO v3(多尺度与特征融合),在网络结构、网络特征及后续计算做出了改进,在保持速度优势的前提下,进一步提升了检测精度,尤其是对小物体的检测能力。(注:YOLO v3的速度并没有之前的版本快,而是在保证实时性的前提下追求检测的精度。)
3.1 YOLO v3网络结构
YOLO v3引入残差网络和特征融合等检测框架,提出了DarkNet-53网络结构。图片输入为416×416×3大小。

各模块含义:
(1)DBL:代表卷积、BN及Leaky ReLU三层的结合,在YOLO v3中,卷积层都是以这样的组件出现的,构成了DarkNet的基本单元。
(2)Res:代表残差模块。
(3)上采样:上采样使用的方式为上池化,即元素复制扩充的方法使得特征尺寸扩大,没有学习参数。
(4)Concat:上采样后将深层与浅层的特征图进行Concat操作,即通道的拼接,类似于FPN,但FPN中使用的是逐元素相加。
DarkNet-53结构的特性:
(1)残差思想:DarkNet-53借鉴了ResNet的残差思想,在基础网络中大量使用了残差连接,因此网络结构可以设计得很深,并且缓解了训练中梯度消失的问题,使得模型更容易收敛。
(2)多层特征图:通过上采样与Concat操作,融合了深、浅层的特征,最终输出了3种尺寸的特征图,用于后续预测。多层特征图对于多尺度物体及小物体检测是有利的。
(3)无池化层:之前的YOLO网络有5个最大池化层,用来缩小特征图的尺寸,下采样率为32,而DarkNet-53并没有采用池化的做法,而是通过步长为2的卷积核来达到缩小尺寸的效果,下采样次数同样是5次,总体下采样率为32。
3.2 多尺度预测
(1)YOLO v3输出了3个大小不同的特征图,从上到下分别对应深层、中层与浅层的特征。深层的特征图尺寸小,感受野大,有利于检测大尺度物体,浅层的特征图更便于检测小尺度物体,与FPN结构类似。
(2)YOLO v3沿用了预选框Anchor,使用聚类的算法得到了9种不同大小宽高的先验框,按照下表进行先验框的分配。

(3)YOLO v3默认使用了COCO数据集,一共有80个物体类别,因此一个先验框需要80维的类别预测值、4个位置预测及1个置信度预测,3个预测框一共需要3×(80+5)=255维,也就是每一个特征图的预测通道数。
3.3 特点
(1)Softmax函数输出的多个类别预测之间会相互抑制,只能预测出一个类别,而Logistic分类器相互独立,可以实现多类别的预测。因此使用Logistic函数代替Softmax函数,以处理类别的预测得分。
(2)Softmax被多个独立的Logistic分类器取代,可以实现物体的多标签分类,并且准确率不会下降。
(3)优点:速度快是YOLO系列最重要的特质,同时YOLO系列的通用性很强,由于其正样本生成过程较为严格,因此背景的误检率也较低。
(4)缺点:位置的准确性较差,召回率也不高,尤其是对于遮挡与拥挤这种较难处理的情况,难以做到高精度。
参考文献:
1.《深度学习之PyTorch物体检测实战》
2.YOLOV3 网络结构学习笔记_J ..的博客-CSDN博客_yolov3网络结构
3. YOLO v3论文原文:《YOLOv3: An Incremental Improvement》
注:
本文是学习所参考文献与资料后的整理与归纳,仅作学习记录,如有侵权请联系作者删除!欢迎大家指正与交流。