Social-STAGE: Spatio-Temporal Multi-Modal Future Trajectory Forecast
Social-STAGE:时空多模态未来轨迹预测
作者:Srikanth Malla Chiho Choi
论文地址:https://arxiv.org/abs/2011.04853
发表时间:Nov 2020
备注:提供改善思路
论文解析
代码开源
代码解析
摘要
本文考虑了具有排序的多模式未来轨迹预测问题。
在此,多模态和排序分别是指多个可能的路径预测以及这些预测中的置信度。
我们提出了 Social-STAGE,具有社交互动意识的时空多注意图卷积网络,并对多模态进行了新颖的评估。
我们的主要贡献包括分析和制定多模式,并使用交互作用和多注意进行排名,并引入新的指标来评估多模式预测的多样性和相关的置信度。
我们对现有的公共数据集ETH和UCY评估了我们的方法,并证明了所提出的算法优于这些数据集上的最新技术。
1 引言
预测动态场景中智能体的轨迹是一个重要的研究问题,涉及诸如自动导航,监视和人机交互等一系列应用。解决该问题的挑战在于对人类行为(即多模式)的变异性和不确定性以及相关的社会和文化规范进行建模,特别是在高度结构化的环境中,其中涉及到主体之间复杂的相互作用(即社会相互作用)。
交互建模和多模态的重要性已通过对交互感知的多模态轨迹预测的研究得到强调[1],[2],[3],[4],[5]。
他们从过去的观察结果中提取交互编码的特征表示,并训练一个深度神经网络以生成将来轨迹的特定分布。
尽管学习了不同类型的分布1,但预测输出可能是具有高方差的单一模式[10]或模式崩溃,从而提供了有限的模式多样性[7]。
另外,大多数现有的多模式方法没有考虑每种模式的可能性及其等级,这对它们在安全关键型应用(例如机器人技术或驾驶辅助系统的自动导航)中的实际使用设置了严格的限制。
例如,考虑一种情况,其中预测算法会为机器人导航生成代理的多个未来轨迹。大多数现有的多模态方法无法指定最佳预测,因为它们无法测量单个模态的概率或排名轨迹。
这种局限性使得系统很难根据给定的多模式预测结果做出正确的决策。
在这项工作中,我们提出了具有新颖性的多模态评估的Social-STAGE,可感知社交交互的时空多注意图卷积网络。
考虑到代理之间的时空交互作用,我们的模型可以预测未来可能发生的变化。
图2说明了我们的方法。
首先,我们使用时空图卷积网络对人与人之间的社交互动进行建模[14]。
观察到行动者的运动历史后,我们将同时探索各个实体及其时空变化的空间影响,从而创建时空相互作用。
然后,在接下来的多注意模块中,我们重点介绍了空间和时间上更重要的交互。
所得到的交互特征被解码为一组具有相应概率的合理确定性轨迹。
平均距离误差(ADE)和最终距离误差(FDE)度量是在轨迹预测中使用的标准评估度量。尽管他们清楚地量化了预测位置与地面真相之间的距离误差,但我们认为无法正确评估多模式方法的预测能力。
从这些指标中观察到的问题如下:
(i)已在一组预测样本上使用了Oracle错误,仅考虑了最佳的预测结果。由于根本没有评估其余的预测结果,因此该过程忽略了多模态轨迹的多样性。
(ii)标准ADE和FDE度量标准不考虑任何类型的预测置信度,例如每个轨迹的概率或等级。但是,实际上,应该在推理过程中没有地面真值的应用中提供并评估这种置信度。考虑到这些限制,我们还引入了基于ADE和FDE的新误差度量,以正确评估多模式预测的多样性以及相关联的置信度。
2 相关工作
A. Deep Learning on Trajectory Forecast(轨迹预测中的深度学习)
在以数据驱动的方式对人与人之间的交互进行建模时,深层神经网络已获得巨大成功。
递归神经网络(RNN)已广泛用于编码行人的运动历史[6],[1],[2],[15],[16]。
RNN使用汇总机制通过汇总不同个体的编码运动特征来提取交互信息。
但是,这样的手工或任意聚合方法可能会阻碍获取重要表示以用于将来的轨迹生成。
为了解决这个限制,在这一领域引入了图神经网络。
图的固有节点边缘拓扑有助于建模人类之间更直观,自然的交互[3],[17],[13],[7]。
这些方法不是汇总信息,而是找到代理之间的交互,对应于更新的边缘。
但是,由于它们对循环单元的结构依赖性[3],[17],在空间和时间上对交互作用进行建模受到限制[13],或者无法正确地捕捉到交互作用的重要性,因此它们很容易在时间范围内积累错误。
在时空空间[7]。相比之下,我们在这项工作中的目的是提出一种可以利用图神经网络[18]克服这种局限性的方法,这种方法在空间和时间上具有多重关注。
B. Multi-Modal Trajectory Forecast(多模态轨迹预测)
近年来,多模态在轨迹预测中的重要性已得到越来越广泛的认可。
考虑到在给定的信息下可能存在多个合理的轨迹,一些著作[6],[3],[7],[5]生成了双变量高斯分布,并依次对行人的未来位置进行了采样。
其他工作使用混合模型[19],[20],[21],[8],[9],[4]解决了未来预测的多模态问题。然而,他们的预测往往是具有高方差的单一模式[10]。
还有一些方法可以扩展深度生成模型,以了解数据上未来轨迹的分布。这些方法使用变分自动编码器(VAE)[1],[11],[12]或生成对抗网络(GAN)[2],[22]。尽管预期它们会产生多模式人类行为,但这种基于随机采样的策略易于出现模式崩溃[7]或后崩溃[12]的问题。
更重要的是,这些工作无法衡量各个模式的概率,因此,它们的多模式预测在许多实际应用中都有实际的局限性。
**[23]最近通过提供每个轨迹输出的概率来解决多模态的更实用的功能。**但是,使用预定义的轨迹集来表示未来运动的不同模式,这很难在不同的环境类型中进行概括。
在这项工作中,我们的模型不仅会生成具有多样性的特定于交互的多模式未来轨迹,而且还会输出与各个模式相关联的概率。
C. Evaluation Metrics for Trajectory Forecast(轨迹预测的评估指标)
通过计算每个未来时间步长上的预测位置与地面真实位置之间的欧几里得距离(L2),可以对未来轨迹进行评估。
通过测量指定时间间隔内的平均距离误差(ADE)和指定时间的最终距离误差(FDE)来报告该误差。
由于这些指标是直观的,可以直接量化预测算法的性能,因此在以前的方法[6],[3]中,它们通常用于评估性能。
对于多模式评估,[1]通过评估误差最小的简单方式,以预言方式扩展了相同的度量。
他们的方法计算性能上限,而不是评估多种模式的多样性或合理性。
[24],[25]引入了基于核密度估计的负对数似然性(KDE NLL)度量,该度量针对采样的轨迹分布计算了地面对数的对数似然。
KDE函数通常会低估输出分布,近似为高斯核。
当预测了多种轨迹模式时(例如,相交处的不同轨迹),由于核近似,它不能正确地捕获多模态。相反,所提出的度量标准避免了这种潜在问题,无需进行近似计算,而是直接评估具有相关概率的多模态轨迹的多样性。
3 METHODOLOGY
A. Problem Formulation

B. Spatio-Temporal Multi-Attention Graph Convolutions(时空多注意力图卷积)
我们在每个时间步: t ∈ { 1 , … , T i n } t \in\left\{1, \ldots, T_{i n}\right\} t∈{
1,…,Tin}
创建一个图形表示: G t = ( V t , E t ) G_{t}=\left(V_{t}, E_{t}\right) Gt=(Vt,Et)
其中:
V t = { v t k ∣ ∀ k ∈ { 1 , … , K } } V_{t}=\left\{v_{t}^{k} \mid \forall k \in\{1, \ldots, K\}\right\} Vt={
vtk∣∀k∈{
1,…,K}}是一组节点
E t = { e t i j ∣ ∀ i , j ∈ { 1 , … , K } } E_{t}=\left\{e_{t}^{i j} \mid \forall i, j \in\{1, \ldots, K\}\right\} Et={
etij∣∀i,j∈{
1,…,K}}是一组边
v t k = x t k − x t − 1 k v_{t}^{k}=x_{t}^{k}-x_{t-1}^{k} vtk=xtk−xt−1k:表示代理k的相对运动的节点属性,该属性还编码每个时间步的航向。
同样, e t i j e_{t}^{i j} etij是边缘属性,其中 e t i j e_{t}^{i j} etij表示两个节点属性之间的连通性。
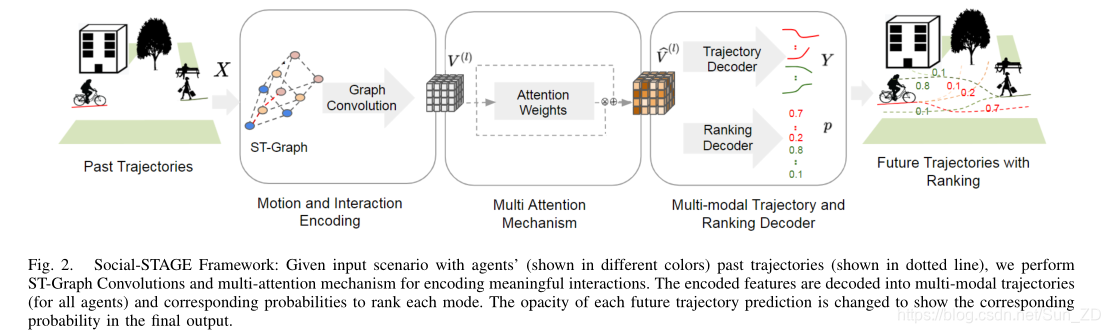
Social-STAGE框架:
给定输入场景,其中有代理人(以不同颜色显示)过去的轨迹(以虚线显示),我们执行ST-Graph卷积和多注意机制来编码有意义的交互。
编码后的特征被解码为多模式轨迹(针对所有代理)和相应的概率,以对每种模式进行排名。
更改每个未来轨迹预测的不透明度,以在最终输出中显示相应的概率。
我们遵循[18],[14]
([18]Semi-supervised classification with graph convolutional networks
[14]Spatial temporal graph convolutional networks for skeleton-based action recognition)中的过程来实现图卷积。
我们定义邻接矩阵,其中元素 a t i j a_{t}^{i j} atij表示两个节点属性 v t i and v t j v_{t}^{i} \text { and } v_{t}^{j} vti and vtj之间的边缘的重要权重。
权重使用类似于7的核函数表示:
if i ≠ j i \neq j i=j
a t i j = 1 / ∥ v t i − v t j ∥ 2 a_{t}^{i j}=1 /\left\|v_{t}^{i}-v_{t}^{j}\right\|_{2} atij=1/∥∥∥vti−vtj∥∥∥2
else
a t i i = 0 a_{t}^{i i}=0 atii=0
为了简化训练,我们采用了重归一化技巧。
因此,邻接矩阵对称归一化为
A t = λ t − 1 / 2 A ^ t λ t − 1 / 2 A_{t}=\lambda_{t}^{-1 / 2} \hat{A}_{t} \lambda_{t}^{-1 / 2} At=λt−1/2A^tλt−1/2
where:
λ t \lambda_{t} λt:是 A t A_{t} At的对角节点度矩阵
A ^ t = A t + I \hat{A}_{t}=A_{t}+I A^t=At+I:使用单位矩阵 I I I ( identity matrix)将自连接添加到At。
对于时空扩展,所有观察时间步骤中我们堆叠邻接矩阵 A = { A t ∣ ∀ t ∈ { 1 , … , T i n } } A=\left\{A_{t} \mid \forall t \in\left\{1, \ldots, T_{i n}\right\}\right\} A={ At∣∀t∈{ 1,…,Tin}}和节点 V = { V t ∣ ∀ t ∈ { 1 , … , T i n } } V=\left\{V_{t} \mid \forall t \in\left\{1, \ldots, T_{i n}\right\}\right\} V={ Vt∣∀t∈{ 1,…,Tin}}。
另外, A ^ \hat{A} A^是 A ^ t \hat{A}_{t} A^t的堆栈,λ是λt的堆栈。因此,使用邻接矩阵按如下方式更新第 l 层的节点属性 V ( l ) V^{(l)} V(l):
f ( V ( l ) , A ) = σ ( λ − 1 / 2 A ^ λ − 1 / 2 V ( l ) W ( l ) ) f\left(V^{(l)}, A\right)=\sigma\left(\lambda^{-1 / 2} \hat{A} \lambda^{-1 / 2} V^{(l)} \mathbf{W}^{(l)}\right) f(V(l),A)=σ(λ−1/2A^λ−1/2V(l)W(l))
where,σ是激活函数,W(l)是层l的可训练权重。
因此,将所得的节点属性公式化为用于时空交互的图卷积特征。
我们进一步使用时间卷积和softmax运算来获得注意力权重。
这些权重对应于交互作用的相对重要性,描述了应捕获交互作用的时间和应识别的代理。
我们使用术语“多注意”,因为各个主体可以同时在空间和时间维度上保持注意力。
请注意,此过程与以前的工作[3](Social attention),17不同,在先前的工作中,单个注意权重以循环的方式在空间中局部生成。
结果,我们可以捕获跨不同时空位置激活的社交互动。
多注意权重由类似于[26](Attention is all you need)的剩余连接更新。
这使我们进行以下操作:
V ^ ( l ) = ( ϕ ( V ( l ) ) ⊗ V ( l ) ) ⊕ V ( l ) \hat{V}^{(l)}=\left(\phi\left(V^{(l)}\right) \otimes V^{(l)}\right) \oplus V^{(l)} V^(l)=(ϕ(V(l))⊗V(l))⊕V(l)
where:
ϕ \phi ϕ:表示用于计算注意力权重的卷积运算,
⊗表示逐元素相乘,
⊕表示逐元素相加运算。
更新后的特征 V ^ ( l ) \hat{V}^{(l)} V^(l)是多注意特征,具有时空交互的注意权重。
图3中显示了该过程,第五节介绍了详细的网络体系结构。
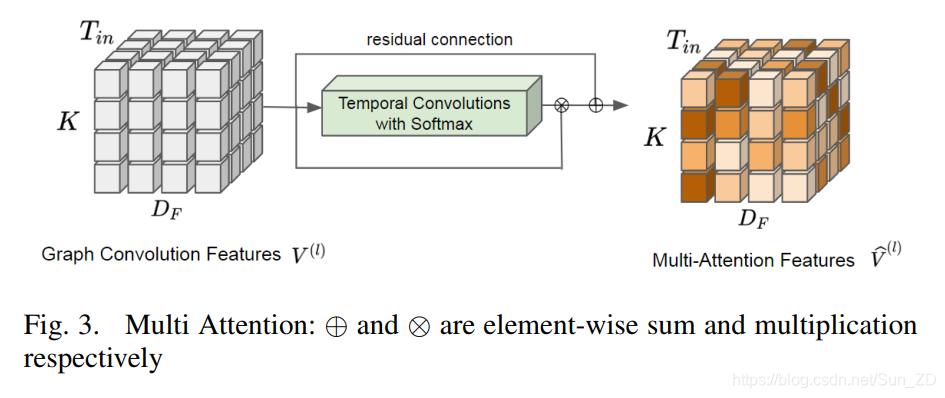
图3所示 多注意:⊕和⊗分别是元素的相加和乘法
C. Ranking and Decoding(排序和解码)
为了解决多模式的实际使用问题,我们针对每种输出轨迹模式引入了概率测度,以对我们的预测进行置信。
此步骤如图4所示。
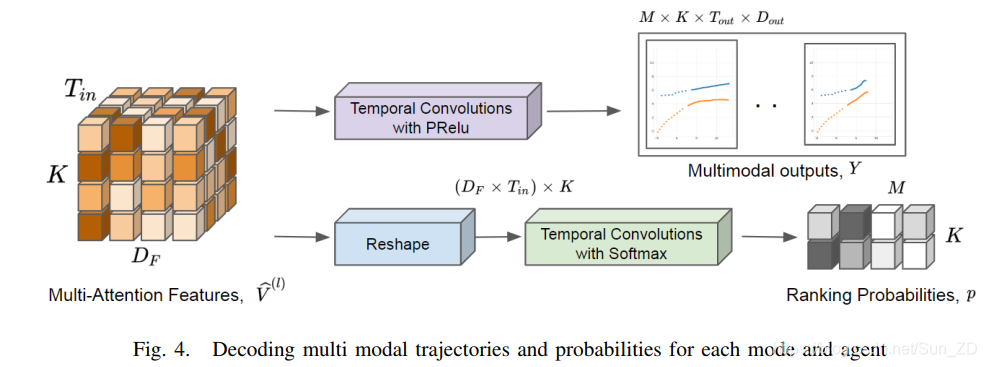
解码每个模态和agent的多模态轨迹和概率
在解码器中,通过使用PRelu操作的时间卷积构造第一个流,以针对Tout时间步长生成K个代理的M条未来轨迹。
因此,每个输出轨迹与模式之一匹配。
由于在我们的实现中,多注意特征DF的尺寸与输出轨迹Dout的尺寸相同,因此无需其他操作即可匹配尺寸。
第二个流生成对应于各个输出模式的概率。
我们通过组合前两个维度(DF,Tin)来重塑张量,然后使用跨输出模式维度M的softmax操作在组合的维度上执行时间卷积,如图4所示。
总损失如式4所示。
Lce是根据模式的预测概率对模式进行排序所产生的交叉熵损失。
L reg min L_{\text {reg }}^{\min } Lreg min是预测轨迹的重建损失。
L = L c e + L r e g min L=L_{c e}+L_{r e g}^{\min } L=Lce+Lregmin
在训练期间,我们预测所有M个输出模式。
但是,每个代理人只有一条地面真实轨迹,因此使用 L reg min L_{\text {reg }}^{\min } Lreg min。
类似于[2](Social gan)中对多模式输出进行惩罚的品种损失,我们对所有输出模式的最小错误模式 L reg min L_{\text {reg }}^{\min } Lreg min进行惩罚,以保留所有主体的多模式,如等式5所示.
m min m_{\min } mmin是最小误差模式,Yk是地面真相的未来轨迹,而 Y ^ m k \hat{Y}_{m}^{k} Y^mk则是智能体k的预测模式(m)。
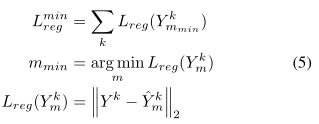
由于没有与每个模式相关的概率的真实性,因此我们以无监督的方式对每个模式进行惩罚,如式(6)所示。
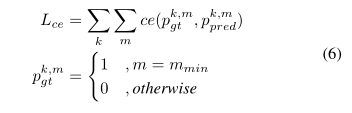
where,
p g t k , m p_{g t}^{k, m} pgtk,m是地面真值,而 p pred k , m p_{\text {pred }}^{k, m} ppred k,m则是对代理k的模式m的预测概率。
使用最小误差标准生成 p g t k , m p_{g t}^{k, m} pgtk,m。
我们根据每种预测模式与地面真实轨迹的接近程度找到其真实性概率。最后, c e ce ce是用于分类的交叉熵。
D. Evaluation Metrics(D.评估指标)
通过计算预测位置与地面位置之间的欧氏距离(L2)进行未来轨迹的评估。
标准误差度量是平均位移误差(ADE),单模态预测的最终位移误差(FDE),最小平均位移误差(ADEmin),
M模式输出的多模态预测的最小最终位移误差(FDEmin):
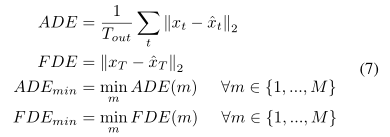
尽管这些指标量化了预测算法的性能,但Oracle使用此类指标评估多模态具有以下固有局限性:
(i)仅考虑误差最小的一条轨迹,这些指标计算性能上限,而只是忽略了多种模式的多样性;
(ii)如果相关联的概率可用,则这些度量标准不会考虑预测置信度。
为了解决这些局限性,我们引入了新的误差指标,可以通过相关联的置信度评估多模式预测的多样性。
对于任何选定的模式 m ^ \hat{m} m^(使用诸如平均或最大概率等标准),我们发现其他模式造成的误差 M = E ( e i ) − p ^ ∗ e ^ \mathcal{M}=\mathrm{E}\left(e_{i}\right)-\hat{p} * \hat{e} M=E(ei)−p^∗e^,排除了由模式的概率ˆ p引起的误差 ( m ^ ) (\hat{m}) (m^)来自所有模式误差 E ( e i ) \mathrm{E}\left(e_{i}\right) E(ei)的期望。
基于此,我们引入了两个新的度量标准,这些度量标准不对方法的输出分布进行任何假设:
(i)M1度量标准可以直接计算相对于地面真实性的轨迹多样性,因为我们减去了最佳误差。通过为所有模式(包括最佳模式) ( p ^ = 1 / M ) (\hat{p}=1 / M) (p^=1/M)分配相等的概率(1 / M),从所有模式的错误期望中选择模式(e)。因此,我们将看到给定测试数据集的预测样本平均有多大差异。
(ii)M2度量旨在评估其他模式相对于其置信度的错误贡献。我们使用预测的概率从所有模式的误差加权期望中减去最佳模式的加权误差 ( e ^ = e p max \left(\hat{e}=e_{p_{\max }}\right. (e^=epmax,最大概率模式误差,其中 p ^ = p max ) \left.\hat{p}=p_{\max }\right) p^=pmax)。
因此,我们测量预测样本相对于其概率的分布程度。
如果值较低,则预测模型可能会确定其高精度的输出。
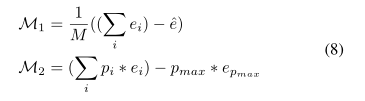
当概率不可用(Social-stgcnn)时,我们选择 e ^ \hat{e} e^(最佳模式误差)作为 e μ e_{\mu} eμ(由其输出分布的均值所贡献的误差)[7].
当概率与每种模式(例如我们的方法Social-STAGE)相关联时,则 e ^ \hat{e} e^作为为 p max p_{\max } pmax(由 p max p_{\max } pmax最大概率模式产生的误差)。
4. EXPERIMENTAL RESULTS
我们对在行人轨迹预测中广泛使用的公开可用的ETH [28] -UCY [29]数据集评估了5种不同的场景。为了公平比较,我们使用与[2],[7]中相同的训练,验证和测试集拆分。
A. Quantitative results
在表I,II,III中,通过与其他最新基准进行比较,我们显示了对ETH-UCY数据集的框架进行不同类型的定量评估。
所有基线的误差和我们的社交阶段(为简单起见,为S-STAGE)均以米为单位报告,未来有8个时间步长的观测值和12个预测时间步长的值。
在表I中,我们显示了单模式比较。
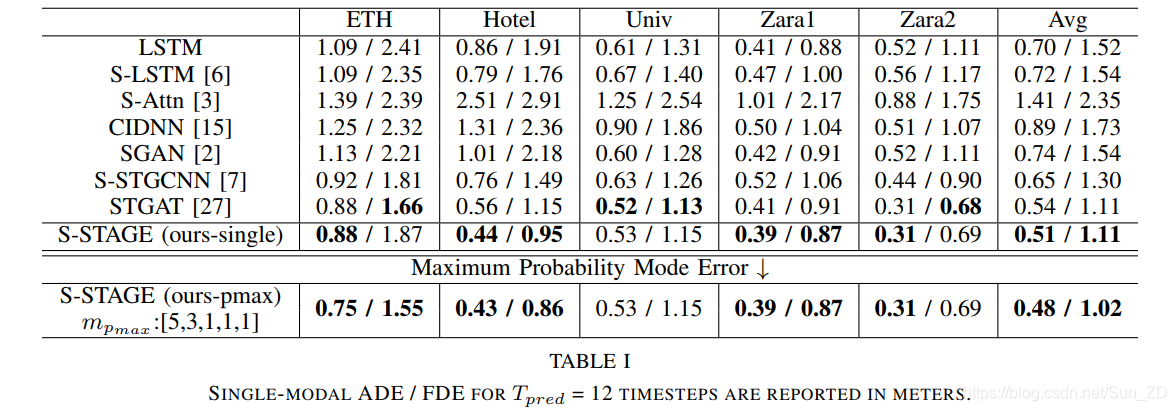
我们的带有图卷积模块和多注意的S-STAGE(单模态)优于类似的基于图的方法,例如S-STGCNN [7]和STGAT [27]。
请注意,S-STGCNN论文未报告单模态比较。
因此,我们的评估基于他们公开提供的经过训练的模型和代码。
我们将高斯预测的均值用于S-STGCNN单模态评估基线。
我们另外报告了使用最佳轨迹模式(可能性最高)进行评估的S-STAGE(ours-pmax)。与所有其他基准相比,此模型的整体效果更好。它强调了我们排名能力的功效。
我们还报告了根据经验计算的最佳模式数,如图5所示。

图5.模式与度量:对于所有5组不同的ETH-UCY,我们在x轴上绘制模式数,在y轴上绘制不同的误差(以米为单位)。虚线显示了该组和度量中相应的最佳最新基线。星号表示代表该数据集的最佳模式数。
在这里,我们在Y轴上绘制度量,在X轴上绘制模式,并以虚线对应相应的最佳基线。
我们观察到在图5(c-d)中,随着模式数量的增加,pmax 误差不会降低。
从ETH的5个模式和Hotel的3个模式可以看出最佳性能。但是,在Univ,Zara1,Zara2的情况下,最大概率误差mpmax = 1与S-STAGE(ours-single)相同,这似乎与这些集合的运动复杂度一致。
对于多模式比较,如图5(a-b)所示,ADE的最佳性能模式与FDE不同。我们基于最小ADEmin选择最佳模式数(mmin)来报告ADEmin和FDEmin。
表II中显示了用于多峰预测的最小误差度量。有趣的是,我们观察到与基线模型相比,即使在所有集合中模式数量较少的情况下,S-STAGE仍表现最佳,这证明了所提出框架的鲁棒性。
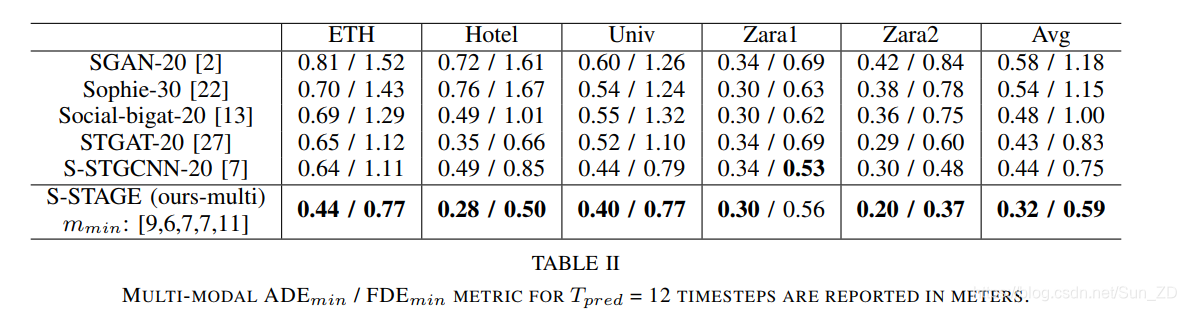
我们还在表III中报告了我们的新指标M1和M2,以评估不同模式(M1)的多样性以及其置信度(M2)。
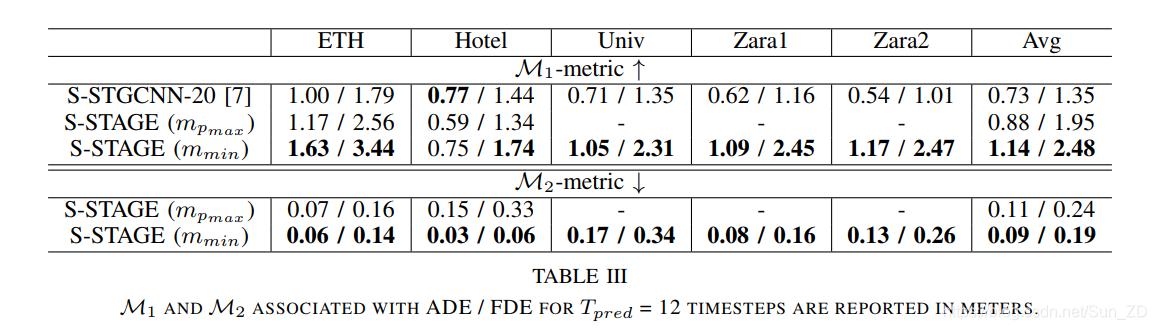
对于M1,我们将 e ^ = e μ \hat{e}=e_{\mu} e^=eμ作为其最佳模式误差与S-STGCNN-20进行比较。
我们在M1中观察到,针对最大概率模式 m p max m_{p_{\max }} mpmax训练的模型(对于ETH有5种模式)比从S-STGCNN采样的20种模式具有更好的多样性。
当我们比较训练用于该度量的多模态评估的 m min m_{\min } mmin([9,6,7,7,11])模型时,它显示了预测轨迹之间更高的多样性。
对于M2的评估,请注意,我们比较了 m p max m_{p_{\max }} mpmax和 m min m_{\min } mmin模型基线,因为比较的最新技术无法提供与预测样本相关的概率。
我们观察到,这两个基准在ETH集中的执行情况相似。但是对于酒店而言,我们发现更多模式给出的错误更少。
总体而言,我们发现 m min m_{\min } mmin基线可以预测高置信度。
B. Qualitative results
我们在图6中显示了模型的多模式预测和排名的定性结果。
*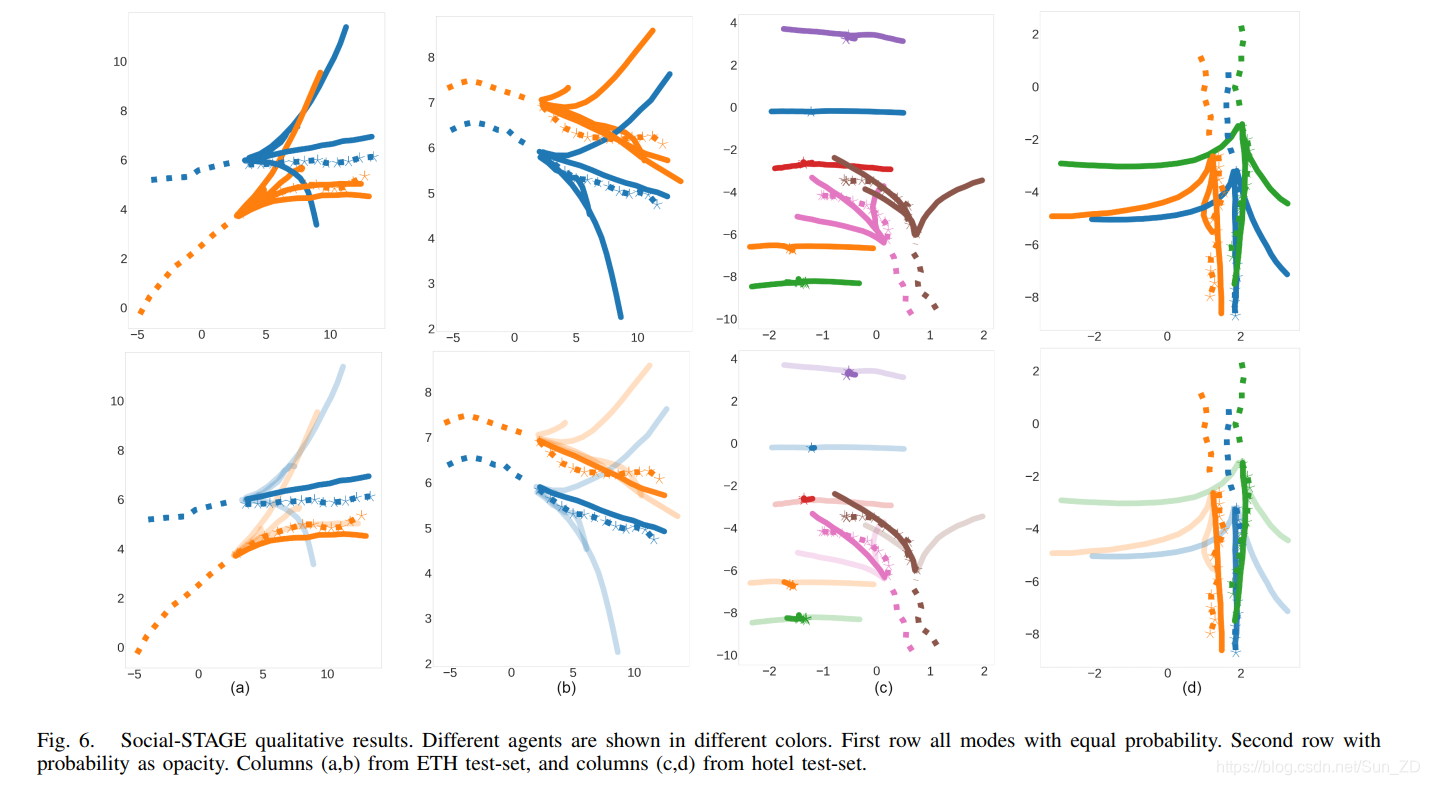
Social-STAGE的定性结果。不同的代理以不同的颜色显示。第一行所有模式均等。第二行,可能性为不透明度。 ETH测试集中的列(a,b)和酒店测试集中的列(c,d)。
不同的行人使用不同的颜色可视化。
第一行显示了来自ETH集(模式数M = 5)的多模式预测场景(a,b)和来自酒店集合(模式数M = 3)的(c,d)。
在场景(a,b)中,当两个行人靠近行走时,根据运动线索和交互作用线索以接近地面真相的最大概率进行预测。
在方案(c)中,有许多行人站着不动。根据他们的运动线索,预测的最大概率模式将在将来产生“站立”状态。另外,其他模式预测它们可以在两个相反的方向移动,这证明了我们提出的模型的多样性。
在相同的情况(c)中,有两个行人彼此并排行走。基于运动提示,网络预测左转轨迹为主导模式。
在情况(d)中,三名行人彼此并排走近。我们的模型预测直行将是一个更占优势的未来,但是与此同时,我们还预测左转或右转的其他可能性,这在实际场景中是普遍且合理的。
5. IMPLEMENTATION AND MODEL DETAILS(实施和模型系节)
我们在下面提供具有以下设置的模型实现的详细信息:示例批量大小为1;示例批量大小为1。
代理数K = 4;输出模式数M = 2;输入时间步数Tin = 8;输出时间步长Tout = 12。
我们训练了100个时期,M的范围从0到20。
我们报告了最佳时期和最佳模式M的结果。
我们使用的学习率为0.0001,并在Quadro RTX 6000 GPU上训练了我们的模型。我们使用PyTorch框架进行实施。

由于ETH-UCY数据集由行人的2D运动 D i n D_{i n} Din = 2组成,因此在每个时间步长上输入轨迹的维数。如果预测是每种模式的高斯分布(高斯混合),则不应该轨迹的输出维。如果预测是直接轨迹回归,则 D out D_{\text {out }} Dout 为5(包含方差和相关输出), D out D_{\text {out }} Dout 应该为2。在此工作中,我们给出 D out D_{\text {out }} Dout = 2,因为我们观察到 D out D_{\text {out }} Dout = 5的多模态设置的对数可能性为负,表现不佳比 D out D_{\text {out }} Dout = 2时,rmse是训练混合物分布时模式崩溃的常见问题[19,20,21,8,9,4]。
6. CONCLUSION
我们提出了一个轨迹预测框架,该框架旨在考虑代理的时空交互作用,以产生具有多样性的未来合理轨迹。
根据agent的运动历史,我们探索了各个特工的空间影响及其时间变化。
然后,我们发现了使用多注意力互动的相对重要性,可以沿着空间和时间维度同时捕获多注意力。
生成的特征用于生成具有相应概率的多个未来轨迹,以对每种模式进行排名。
为此,我们使用公共基准数据集评估了我们的方法,并显示了对标准ADE和FDE指标以及本工作中新引入的M1和M2的单模式和多模式预测的显着改进,以评估多样性以及相关的多概率模态预测。