Learning Deformable Kernels for Image and Video Denoising
作者: Xiangyu Xu 商汤科技SenseTime Research
论文思想:一是将传统的双边滤波算法与CNN结合起来,二是用变形卷积来做多帧对齐的问题,三还是在raw上进行处理的。
主要贡献:
- 将传统降噪算法和变形卷积结合起来,使用变形卷积来显示学习传统算法中挑选和平均的过程。
- 将2D变形卷积扩展到了3D中,可以进一步地提升大幅运动的视频降噪的性能和减小artifact。还提出了3D变形卷积的正则项。
- 对于变形卷积是如何起作用给出了可视化的分析。
-
利用基于聚合的方法和深度神经网络的优势,并提出一种新算法来显式学习图像去噪的像素聚合过程。
-
将空间像素聚合扩展到时空域,以更好地处理视频去噪中的大运动,从而进一步减少伪影并提高性能。
-
引入了一个正则化项来帮助训练视频去噪模型。在基准数据集上进行的大量实验表明,我们的方法在单个图像和视频输入上都优于最先进的方法。
摘要
- 现有去噪方法通过
by selecting and averaging pixels恢复,本文建议使用NN,不依赖于手工制作和平均策略 - 本文提出
deformable 2D kernels for image denoising应用图像去噪,自适应图像结构,有效降低过度平滑和伪影 - 再提出
3D deformable kernels for video denoising引用视频去噪,有效采用空间时间像素,解决大运动的misalignment问题 - 引入新的
regularization term和the trilinear sampler进行训练视频去噪模型。
介绍
图像和视频捕获系统通常会因噪声(包括光子的散粒噪声和传感器的读取噪声)而退化 [1]。对于在弱光场景或小光圈手机摄像头拍摄的图像和视频,这个问题会更加严重。大多数去噪方法的成功源于这样一个事实,即对同一信号的多个独立观察进行平均会导致方差低于原始观察。在数学上,这被表述为:

(1)现有的去噪算法 [2]-[4]、[6]、[7] 通常从输入图像中采样相似的像素,并通过加权平均对它们进行聚合。采样网格 N 和平均权重 F 通常是数据相关和空间变化的,因为相似像素的分布取决于局部图像结构。决定 N 和 F 的策略是区分不同去噪方法的关键因素。这些方法通常使hand-crafted schemes进行sample and weigh pixels,在复杂场景中并不总是表现良好,如图 1© 和 (h) 所示。
(2)基于CNN的方式被提出,其使用的是空间不变和数据独立的convolution kernels,然而去噪过程却是使用的空间变化和数据依赖的。因此,这些方法需要非常深的结构来实现高非线性以隐式逼近空间变化和数据相关的过程,这不如基于聚合的公式高效和简洁。此外,基于CNN 的方法没有明确地操纵输入像素来限制输出空间,并且可能会产生损坏的图像纹理和过度平滑的伪影,如图 1(d) 所示。
(3)因此,本文提出 a pixel aggregation network用于将像素聚合过程与数据驱动的图像去噪方法显式集成。
细节:使用 CNN 来估计噪声图像中每个位置的空间采样网格 N。为了聚合采样像素,我们预测每个样本的平均权重 F,最后,可以通过在端到端网络中将 F 和 N 与加权平均相结合来获得去噪输出。
优势:(1)聚合过程依赖于学习数据而不是手工制作(2)所提出的模型可以更好地适应图像结构并通过空间变化和数据相关的采样和平均策略保留细节。(3)直接过滤噪声输入,从而限制了输出空间(4)所提出的方法可以以动态方式对像素进行采样(不是通过卷积核这种位置固定等性质的刚性采样),以更好地适应图像结构并在不采样更多位置的情况下增加感受野。
(4)应用到视频:直接将2D pixel aggregation分别应用到每个帧,最后逐帧融合
——缺点:面对大规模运动不可靠;相邻帧之间几乎没有可靠的采样信息
——解决:为所输出的每个位置开发一个a spatio-temporal pixel aggregation network,用于自适应选择相邻帧中信息量最大的像素点。
——优势:能够解决由于动态场景引起的错位问题;减少伪影现象;
相关工作
1、图像和视频去噪
- 基于像素聚合的显示或者隐式方法(在局部窗口进行采样像素块、计算平均权重后进行聚合),或者非局部均值方法(全局聚合)
- 由于视频中的时间和空间信息,VBM3D/VBM4D等通过对相似像素进行分组,然后再聚合)流行
- 基于深度学习:基于残差连接的CNN和循环神经网络RNN
2、突发去噪brust denoising
- 现有方法其卷积核采用的多是精确的采样网格不能很好地利用局部图像结构
3、learning dynamic filtering
- 多数方法只考虑来自固定区域的像素,这通常会导致感受野有限,并且很容易受到不相关的采样位置的影响。
- 使用明确的权重方法,可能会产生过度平滑的伪影。类似于
Gaussian filters
提出的方法
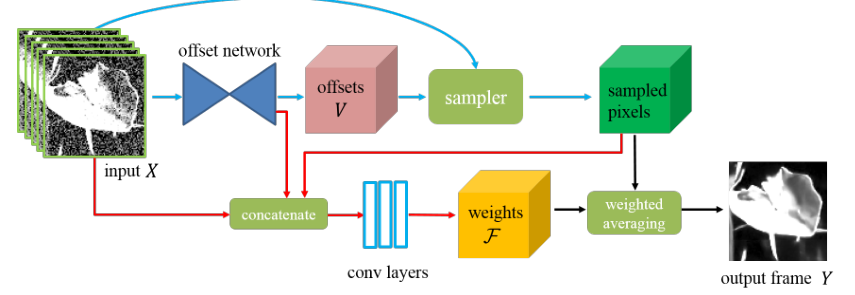
We first train a deep CNN for estimating the offsets of the sampling grid.
Next, we sample pixels from the noisy input** according to the predicted offsets, and estimate the weights by concatenating the sampled pixels, the noisy input andthe features of the offset network.
Finally, we generate the denoised output by averaging the sampled pixels with the learned weights.
具体来说,我们使用神经网络来预测噪声输入的每个像素的采样位置
the sampling locationsN 和平均权重averaging weightsF。这两个组件被集成用于空间和时空像素聚合。我们不是直接回归 N 的空间坐标the spatial coordinates,而是学习刚性采样网格的偏移量offsetsV 并相应地变形刚性网格。简单的说:通过offset network 某个像素点 在其周围 信息量很大的位置 的偏移位置信息V,通过采样获取偏移的像素,将原图、偏移位置信息、偏移的像素同时输入,然后通过卷积层获得平均权重F,对采样的像素点进行平均学习输出。
A 学习聚合像素的过程(图像)
对于噪声图像来说X是其中一个像素,属于$ R^{h*w}$ h和w代表长和宽
聚合噪声表示为
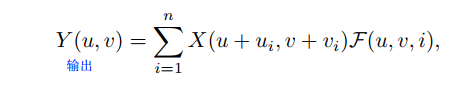
其中(u,v)表示其中一个输入去噪的像素,F表示平均像素的权重,N表示具有n个位置的采样网格。
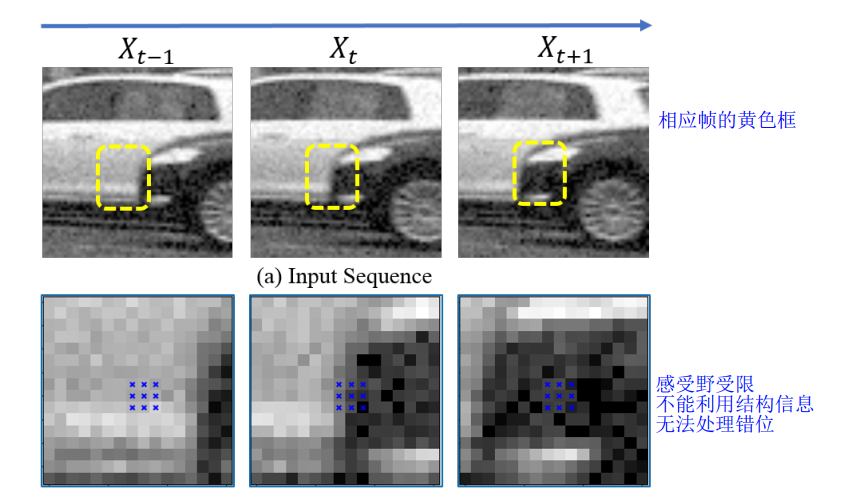
上图其视频序列中其中相邻三针,黄色框 为 下图待框选的 需要采样区域
上图蓝色区域表示使用a rigid sampling grid进行刚性采样:即网格区域固定,类似卷积核
仅使用此方式并且后续只学习平均权重,通常造成感受野有限,不能有效利用图像的结构信息
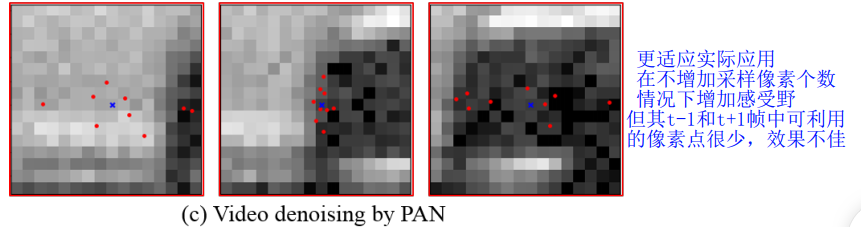
本文提出pixel aggregation network (PAN) ,the adaptive sampling grid根据网络的预测偏移量V进行网格设计。
使用此方式,效果较好,比如点的区域在车头附近(黑影的左侧),这样能大概根据附近 自适应调节采样像素位置
- 时空像素聚合
所提出的方法可以很容易地扩展到视频去噪。假设我们有一个嘈杂的视频序列 {Xt−τ , . . . , Xt, . . . , Xt+τ },其中 Xt 是参考系。处理此输入的一种直接方法是将 PAN 模型分别应用于每个帧,然后将输出与加权和融合,如上图c。然而,这种简单的 2D 策略在处理大运动视频时无效,因为在相邻帧的区域(例如图 4 中帧 Xt-1 和 Xt+1 的中心区域)几乎没有可靠的像素。
为了解决这个问题,我们需要在可靠性更高的帧(例如参考帧 Xt)上分配更多的采样位置,并避免出现剧烈运动的帧。一个有效的解决方案应该能够在输入视频的时空空间中搜索像素。
本文提出 a spatio-temporal pixel aggregation network (ST-PAN)用于视频去噪, adaptively selects the most informative pixels in the spatio-temporal space. (自适应地选择时空空间中信息量最大的像素)
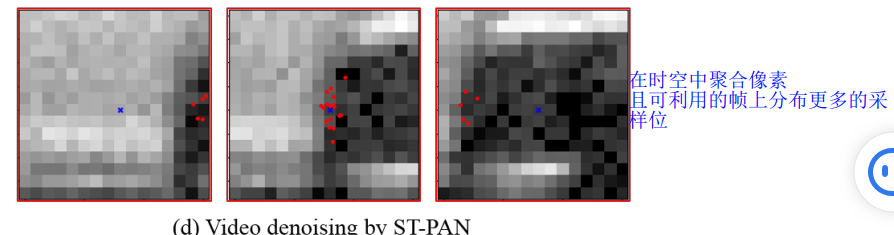
通过捕获 3D 位置之间的依赖关系并在更可靠的帧上进行采样可以解决 the large motion issues ,同时高效处理 reduce cluttered boundaries and ghosting artifacts generated by existing video denoising approaches [7], [9].
图片上的采样点不够(右侧),说明不仅在相邻两帧有采样,在其他帧中由于信息量更大, 也会采样部分信息点
- Gamma correction 伽玛校正
由于噪声在 sRGB 空间 [33]、[34] 中是非线性的,我们在线性原始空间中训练去噪模型。使用线性输出 Y ,我们进行 Gamma 校正 5 以生成最终结果以获得更好的感知质量
B Network Architecture网络结构

将单帧作为图像去噪的输入,将 2τ + 1 个相邻帧的序列用于视频去噪。如图 3(b) 所示,
采用了 U-Net 架构 [35],其中编码器将输入帧顺序转换为较低分辨率的特征嵌入,解码器相应地将特征扩展回全分辨率估计。我们使用编码器和解码器中相同分辨率层之间的跳跃连接执行逐像素求和,以共同使用低级和高级特征进行估计任务。由于预测的权重将应用于采样像素,因此将这些像素馈送到权重估计分支是有益的,这样权重可以更好地适应采样像素。因此,我们将来自偏移网络最后一层的采样像素、噪声输入和特征连接起来,并将它们馈送到三个卷积层以估计平均权重。设计细节参数看原文
C Loss Function 损失函数设计
use an L1 loss to train our network for single image denoising

- Regularization term for video denoising
由于 ST-PAN 模型对视频帧中的像素进行采样,因此训练过程可能会停留在local minimum 局部最小值,即所有样本位置仅位于参考帧周围。为了缓解这个问题并鼓励网络利用更多的时间信息,我们引入了一个正则化项,让subsets of the sampled pixels 采样像素的子集单独学习 3D 聚合过程。
将采样网格 进行分组,分成S组,每组N/s个组成,类似[6],可以参考考
实验
数据集
we collect 27 high-quality long videos from the Internet, We use 23 long videos for training and the other 4 for testing, we extract 20K sequences for training where each sequence consists of 2τ + 1 consecutive frames Similar to [9], we generate the noisy input for our models by performing inverse Gamma correction and adding signal dependent Gaussian noise
Training and Parameter Settings
训练一些参数的基本设置
合成数据集上的测试
我们在不同噪声水平的合成数据集上针对最先进的图像和视频去噪方法 [3]、[4]、[7]、[9]、[10] 评估所提出的算法。我们对 NLM [3]、BM3D [4] 和 VBM4D [7] 方法(包括盲模型和非盲模型)进行详尽的超参数微调,并选择最佳结果。同时为了比较,我们使用相同的设置在我们的数据集上训练 KPN [9] 和 DnCNN [10] 方法。虽然 KPN [9] 方案最初是为多帧输入设计的,但我们通过改变网络输入将其调整为单幅图像以进行更全面的评估。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tiSsPDBW-1689334096676)(C:/Users/dell/AppData/Roaming/Typora/typora-user-images/image-20220319095027284.png)]


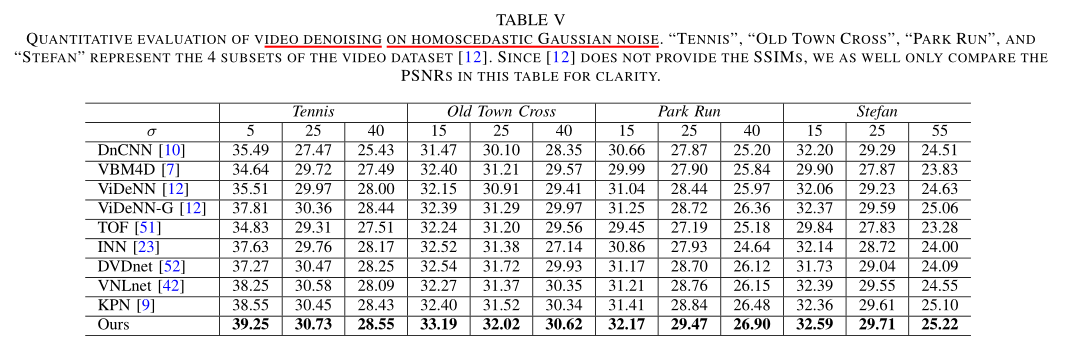
Homoscedastic Gaussian Noise 评估
虽然现实世界中的噪声主要是信号相关和异方差的 [1]、[13]、[53],但现有方法通常在同方差高斯上评估其去噪算法噪声 [10]、[12]、[42]、[45]–[49]、[52]。为了进行更全面的研究,我们在具有同方差高斯噪声的图像和视频去噪数据集上评估了所提出的 PAN 和 ST-PAN 模型
时间一致性验证Temporal Consistency

视频去噪算法通常希望生成时间一致的视频帧。在图 7 中,我们展示了一些视频去噪结果,用于评估所提出模型的时间一致性。具体来说,我们通过 60 个连续帧收集由垂直红线(如图 7(a) 所示)突出显示的 1D 样本,并将这些 1D 样本连接成 2D 图像以表示去噪视频的时间分布。与基线方法的结果(图 7(c)和(d))相比,所提出的 ST-PAN 模型(图 7(e))的时间分布具有更平滑的结构和更少的抖动伪影,这表明更好的时间一致性我们的模型。
真实输出结果比较

讨论和分析
样本连接成 2D 图像以表示去噪视频的时间分布。与基线方法的结果(图 7(c)和(d))相比,所提出的 ST-PAN 模型(图 7(e))的时间分布具有更平滑的结构和更少的抖动伪影,这表明更好的时间一致性我们的模型。
真实输出结果比较
