1 摘要
基于地点的移动端服务商,譬如Yelp、Uber,要从大量的用户签到和轨迹信息中学习用户的行程习惯,对用户下一个访问地点进行预测,并以此为用户的下一步行程需求进行规划和推荐。然而,现有模型对时空信息的利用存在局限性,譬如只利用前后一步的时间和空间差[1,2],人为划分空间区域[3]或者只聚合距离较近的地点[4],并对访问地点的频率不加考虑。本文旨在提出一种基于注意力机制的神经网络架构,考虑用户访问轨迹中每个访问点相较于整个过往访问轨迹的时空关系,以此对不相邻非连续但功能相近的访问点进行关联,打破以往仅仅关联连续、相邻访问点的限制。
2 问题背景
地点序列推荐任务过去主要依赖于马尔可夫模型和循环神经网络。最近两年,随着神经网络的发展,注意力机制和图模型逐渐被用在地点序列推荐任务中,其预测精度和召回率相较于过去的模型获得显著的提高。
然而,当下的模型仍有以下三个局限:
1)空间上不相邻且时间上非连续的访问点可能是功能相关的,然而过去的绝大多数模型只考虑空间上处于一个区域且时间上前后邻近的访问点的时空关联;
2)空间上划分区域的方法使得模型对空间距离不敏感,不可避免地丢失了空间差信息和不相邻点的关联信息;
3)过去模型没有充分考虑用户访问频率。
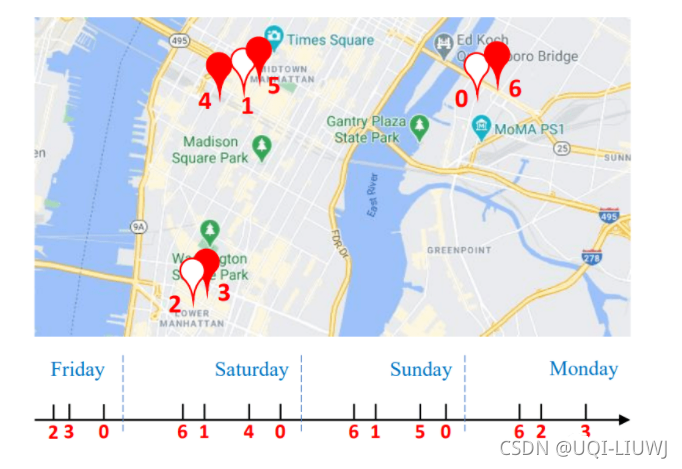
我们不妨截取真实数据中一位用户的轨迹片段进行可视化,以说明为何不相邻非连续的访问却有可能是时空和功能上高度相关的。
在上图中,我们用0-6这7个阿拉伯数字分别表示7个地点,用一个时间轴将该用户访问的顺序和时间表示出来;
其中,虚心坐标0、1、2分别代表家、公司、商场(根据GPS定位查找得出),而实心坐标代表餐馆。可以看到,这位用户总在周末逛商场、在工作日去公司,并且有就近就餐的习惯。显然,在这里,用户总在餐点去餐馆打卡,而不同的餐馆虽然相互地理位置和时间上不相邻,却反映类似的功能,因此在时空上呈现明显的关联性。这种关联性可以有效地帮助我们推断用户在某个具体的时空点如何规划下一步访问计划。
3 主要贡献
本文提出一种新的地点序列推荐的模型,STAN,即时空注意力网络:

- STAN是第一个将用户访问轨迹中每个访问点相较于过往访问轨迹的直接时空差纳入地点序列推荐的模型,让STAN具备从全局轨迹层面上聚合时空不相邻访问点的能力。
- 离散化嵌入空间与时间差值时,STAN建立单位时间空间向量,使用插值方法替换空间网格划分区域的方法,对时空关联差值大小更加敏感。
- STAN采用一种双层注意力架构:前一层聚合轨迹内相关访问点以更新地点表示;后一层根据当前时空点和轨迹内访问点的时空关联召回候选集中的地点。相同的地点可能在轨迹内重复出现,因此重复召回考虑了用户的访问频率。
- STAN使用了平衡的样本采集器,缓解了正负样本不均衡问题。
- STAN与其他State-Of-The-Art模型在四个真实数据集上的对比和消融实验表明,STAN可以有效提升召回率9-17%左右,并且提出的每一个架构改进均有提升效果。
4 问题定义
4.1 历史轨迹
在我们考虑的问题中,每一个用户 的轨迹 是由一连串的访问点 组成的,其中每个访问点包含有用户、地点序号、时间,即U,L,T 。我们可将用户、地点和时间的集合表示为
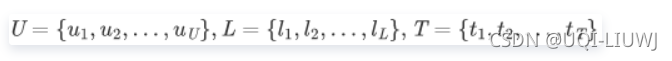
每个地点对应一个单独的经纬度坐标,因此我们可以直接求得每两个地点之间的地理距离 由于每个用户的到访记录序列均不相同,且长短不一,数据预处理阶段我们截取一个最大长度为Len的序列 ;如果到访记录序列长度大于Len,则截取最近的Len个访问点,如果到访记录序列长度小于Len,则向原序列右边补零。
4.2 轨迹时空关联矩阵
我们可以将两点之间的时间差和地理距离作为直接时空关联信息,其中序列中第i个点和第j个点之间的时间差和空间距离分别表示为

计算轨迹内每个访问点之间的时空关联,分别得到时间矩阵 和空间矩阵 。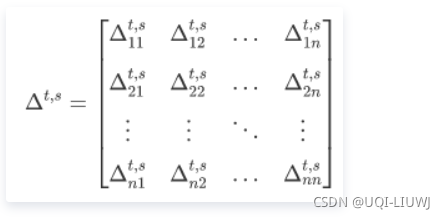
4.3 候选时空关联矩阵
除了轨迹内部的时空关联,我们还可以将轨迹中每个访问点与候选集中可能的下一点间的时空关联信息用于下一点预测,其中轨迹中第i个点和候选集中第j个点之间的时间差和空间距离分别表示为

计算轨迹内每个访问点之间的时空关联,可以分别得到时间矩阵 和空间矩阵

4.4 下一地点预测
给定用户轨迹![]() ,地点集合
,地点集合 ![]() ,轨迹时空关联矩阵
,轨迹时空关联矩阵![]() 和候选时空关联矩阵
和候选时空关联矩阵![]() ,我们的目标是精准预测下一个访问点的地点序号 。
,我们的目标是精准预测下一个访问点的地点序号 。
5 模型与方法
模型总共由四个模块组成:嵌入模块,自注意力聚合层,注意力匹配层,平衡采样器。
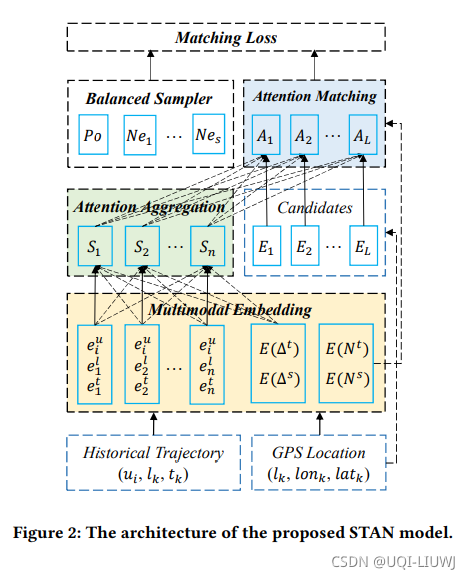
5.1 嵌入模块
5.1.1用户轨迹嵌入层

我们用三个独立的嵌入层将用户、地点、时间转换为潜表示![]() 。
。
用户和地点的嵌入输出维度都由超参数d决定,而输入维度由集合的尺寸决定。
时间的嵌入输入维度是由其一周中的具体小时时间戳决定的;由于一周有7x24=168小时,所以时间输入维度是168。
用户轨迹嵌入层的最终输出是三个嵌入层结果的求和,即 ![]() 。
。
对每个用户序列![]() ,我们将其嵌入表示写为
,我们将其嵌入表示写为![]() 。
。
5. 1.2 时空嵌入层
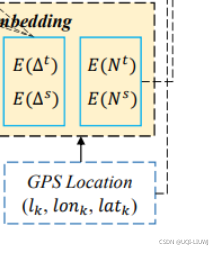
我们提出时间和空间差的单位嵌入层 ,将每个小时和每一百米作为基本单元,映射到一个维度为d的欧氏空间。
回想一下,如果我们将最大的空间或时间间隔视为嵌入的维度,并将所有间隔离散化,就很容易得到稀疏关系编码。
因此 对于每两个访问点之间的时间差和空间差的嵌入表示,我们可以计算其真实差值乘以单位嵌入表示,而不是对每一个的时间差和空间差单独作为嵌入维度。这样做的好处是,在时空嵌入的过程中,我们仍然可以保持对差值的敏感度,大大减少计算量(输入维度仅为2,时间和空间距离的【标量】)。
![]()

每一对点的时间和空间距离分别被embed成d维向量,所以经过嵌入得到:

再经过求和,可以得到最终的轨迹嵌入 和候选嵌入 。
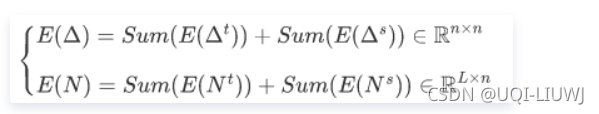
5.2 自注意力聚合层
受到自我注意机制的启发,我们提出了一个扩展模块来考虑不同的空间距离和时间间隔之间的轨迹访问。
该模块旨在聚合相关的访问地点,并更新每次访问的表示。
自我注意层可以捕捉长期依赖性,并为轨迹内的每次访问分配不同的权重。
这种轨迹内的点对点交互允许层为相关访问分配更多的权重。此外,我们可以很容易地将显式的时空间隔纳入相互作用中。
给定一个用户的embedding矩阵E(u) 【其中有示数(也就是可以看到的访问数量)为m‘】。时空关联矩阵E(Δ),自注意力层首先创建一个mask 矩阵(其中左下方的m’*m'个元素是是1,其他元素是0)
然后自注意层计算一个新的序列S,这个S是通过参数矩阵来求得。
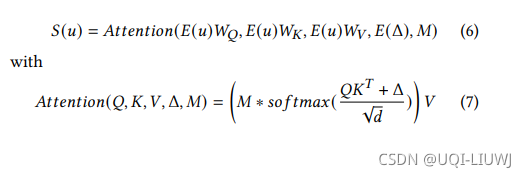
attention模块最终得到的是一个n*d维度的向量(每个visit一个)
5.3 注意力匹配层
该模块的作用是从候选地点集合L中召回最有可能下一步访问的地点。给定用户轨迹更新后的表示 ,地点集合的嵌入表示
,以及5.1.2 计算的
