来源:2023 CVPR
题目:自动驾驶的多模态三维语义分割
原文链接:
0、摘要
激光雷达和摄像机是自动驾驶三维语义分割的两种方法。由于缺乏足够的激光点,目前流行的仅使用lidar的方法在小的和遥远的物体上严重存在分割不足的问题,而鲁棒的多模态解决方案还没有得到充分的探索,在这方面我们研究了三个关键的固有困难:模态异质性、受限的传感器视场相交和多模态数据增强。提出了一种结合模态内特征提取和模态间特征融合的多模态三维语义分割模型(MSeg3D)。MSeg3D中的多模态融合包括基于几何的特征融合GF-Phase、跨模态特征补全和基于语义的特征融合SF-Phase。通过对激光雷达点云和多摄像机图像分别进行非对称变换,使多模态数据增强得到了新的发展,从而有利于采用多种增强变换进行模型训练。MSeg3D在nuScenes、Waymo和SemanticKITTI数据集上实现了最先进的结果。在故障的多摄像机输入和多帧点云输入下,MSeg3D仍然显示了鲁棒性,并提高了LiDARonly基线。我们的代码在https: //github.com/jialeli1/lidarseg3d上公开。
1、引言
利用相机二维图像和激光雷达三维点云对每个最小的模态感知单元进行密集分类,通过语义分割实现安全自动驾驶场景理解。基于图像的二维语义分割已经得到了大量扎实的研究[12,34,61,63]。相机图像具有丰富的物体外观信息,但严重受光照、物体尺度变化和间接应用的影响。另一种模式,LiDAR点云,利用激光点驱动三维语义分割[1,3,11,37]。不幸的是,不规则的激光点太稀疏,无法捕捉物体的细节。不准确的分割尤其出现在小的和遥远的物体上。另一个有待探索的方向是利用多模态数据来提高3D语义分割的鲁棒性和准确性[67]。
尽管多模态分割模型在概念上具有优势,但其发展仍不平凡,滞后于单模态分割方法[27]。我们理性地认为,造成这种困难的原因有三个方面。
i)模式间的异质性。由于点的稀疏性和像素的稠密性,点云特征提取器[14,31]和图像特征提取器[15,44,47]得到了明显的发展。采用独立的模态内特征提取器来解决异质性[13,20,25,42,51],但由于缺乏联合优化,导致不相关的网络参数产生次优特征。
ii)传感器之间的视场(FOV)相交有限。只有落在相交视场内的点与多模态数据有几何关联,而仅仅考虑相交的多模态数据是不够实际的。仅在有限的视场交叉点(如[20,67])进行融合,整体分割效果不理想,如图1所示。
iii)多模态数据增强。例如,PMF[67]只对空间对齐的点云投影图像和相机RGB图像使用了几种2D增强。在模态对齐或点云二维表示的约束下,多模态分割的工作[20,25,67]舍弃了许多有用的和临界的点云增强变换,牺牲了感知性能[36,48]。
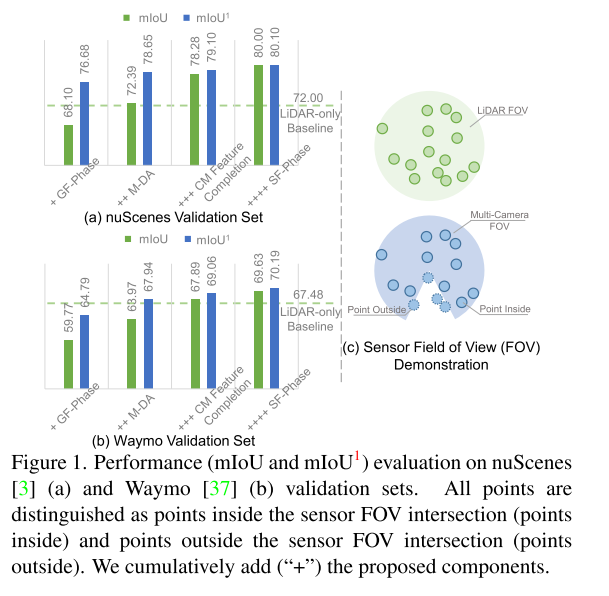
图1。nuScenes [3] (a)和Waymo [37] (b)验证集上的(mIoU和mIoU1)性能评估。所有点都可以区分为传感器视场交叉点(内部点)和传感器视场交叉点(外部点)。我们将建议的组件累加(“+”)。
因此,我们提出了一种高性能的多模态3D语义分割方法,称为MSeg3D,其内在动机是解决上述三个技术难题。
i)不同于现有方法中单独提取模态特征[13,25,42,51],我们联合优化模态内特征提取和模态间特征融合,以最大程度地驱动异质模态之间的相关性和互补性。
ii)为了克服视场交点外忽略的多模态融合[25,67],我们提出了一种跨模态特征补全和一种基于语义的特征融合阶段SF-Phase,与基于几何的特征融合阶段GF-Phase协作。对于视场交叉点以外的点,前者在交叉模态监督的明确指导下,利用预测的伪摄像机特征来完成缺失的摄像机特征。对于视场交叉点内外的所有点,后一阶段SFPhase利用多头注意[41]对点与感兴趣类别之间的语义关系进行建模,从而将所有可见域聚合的语义嵌入集中到每个点上。
iii)具有挑战性的多模态数据增强被分解为LiDAR、相机世界和本地相机中的非对称变换,从而能够灵活地排列,丰富训练样本。
随着图1中建议部分的累积,mIoU和mIoU1显著增加,mIoU和mIoU1的间距逐渐减小。我们的贡献有四部分:
i)我们提出了一个结合模态内特征提取和模态间特征融合的多模态分割模型MSeg3D,在竞争对手nuScenes[3]、Waymo[37]和SemanticKITTI[1]数据集上实现了最先进的3D分割性能。该框架在2022年CVPR的Waymo 3D语义分割挑战赛中获得了第二名。
ii)提出了跨模态特征完成和基于语义的特征融合阶段。据我们所知,这是第一次解决传感器视场交叉口外被忽视和不适用的多模态融合问题。
iii)通过对点云和图像进行非对称增强变换,提出的非对称多模态数据增强方法显著提高了训练模型多模态样本的多样性,并具有鲁棒性改进。
iv)对我们方法的改进和鲁棒性的大量实验分析清楚地研究了我们的设计。
2、相关工作
Lidar的3D语义分割
SemanticKITTI [1], nuScenes[3]和Waymo[37]数据集促进了lidar专用的3D语义分割。这些方法遵循U-Net[33]架构,但只有三种点云表示方法。
i)点。由PointNet++[31]派生的点方法在无序邻域的采样和采集上花费了大量的计算量,特别是在大规模的LiDAR点云上。主要的点方法[17,32,39,53]在小的合成点云[56]上表现较好,而不是稀疏的LiDAR点云。
ii) 2D图像。PolarNetseries[62,65]等[26,40,46,49]将三维点云投影为鸟瞰视图和距离视图中的二维图像,利用二维cnn实现高效的LiDAR分割。但是3D到2d的投影会损害3D信息和性能。
iii) 3D体素。目前最先进的SPVNAS[38]、Cylinder3D[66]和SDSeg3D[21]显式地探索不同三维坐标系统中的三维结构信息,这些信息可以在非空体素上高效地执行三维稀疏卷积[8,54]。点和图像表示还可能促进RPVNet[50]和AF2-S3Net[7]中的体素特征。我们也执行有效和高效的3D体素特征学习。
多模态三维语义分割
多模态三维语义分割在[13,20,25,67]中进行了研究,使用了激光雷达和摄像机,但性能不理想。将RGB值或单独学习的CNN特征的次优特征源扭曲成点云范围图像作为附加的输入特征[20,25]。近期PMF[67]将点云投影到图像平面上与图像数据进行融合,明显受到相机视场的限制。他们抛弃了视场角以外点的融合和分割。尽管FOV内的分割性能得到了改善,但仍需要另一个LiDAR模型负责其余区域[43,67]。这种不平衡和不方便使得研究人员无法专注于多模态三维语义分割。上述作品中点云的图像格式限制了他们只能进行二维翻转等图像增强,而不能进行三维点云增强。相反,我们指出对于我们的三维分割网络,点云增强的必要性。与另一种多模态三维物体检测器PointAugmenting[43]在保持图像不变的同时保持点云增强不同,我们的方法从两种形式的非对称变换开始。2D3DNet[13]的目标是通过减少3D标注,增加未标注数据,增加手工2D标注,训练2D模型,提前获得2D分割结果。2D分割也绘制到这些点上,作为3D模型[42]的附加输入。这种分阶段的训练方法缺乏联合2D-3D优化。我们的动机、技术和结果与他们不同。
3、方法
3.1 准备工作
问题设置
设 为多模态样本,其中
为多模态样本,其中 表示具有
表示具有 维输入特征(如三维坐标、反射率)的
维输入特征(如三维坐标、反射率)的 点云,
点云, 表示
表示 相机的多相机RGB图像。在传感器标定的基础上,利用像素坐标(c, u, v)将三维坐标(x, y, z)的点投影到第c个局部摄像机图像上。
相机的多相机RGB图像。在传感器标定的基础上,利用像素坐标(c, u, v)将三维坐标(x, y, z)的点投影到第c个局部摄像机图像上。
激光雷达特征提取
考虑到图2中的输入,我们首先使用并行主干进行模内特征提取,以解决点云与图像之间的异质性。由于3D体素的优越性,我们在补充材料(SM)中使用一种通用的稀疏3D U-Net[9,35]进行基于体素的LiDAR特征提取。输入点云首先被量化步长d分割,然后通过平均体素内局部点的逐点初始特征,将其分组为非空体素。这些非空体素 构成点云主干的稀疏张量输入,用于学习表达体素特征
构成点云主干的稀疏张量输入,用于学习表达体素特征 。
。
相机特征提取。
为了用联合优化的相机特性增强LiDAR特性,我们使用可训练的图像骨干(默认为HRNet-w48[44])非线性投影 为
为 ,下采样形状H×W,增加通道
,下采样形状H×W,增加通道 。
。

点云和图像骨干可以从各种成熟的网络中灵活选择。此外,在整个三维分割模型中,我们联合优化两个主干,从不同的模式中学习相关的语义特征表示。表达体素特征V和图像特征X保证了跨模态特征融合,包括图2右半部分的GF-Phase、交叉模态特征补全和SF-Phase。
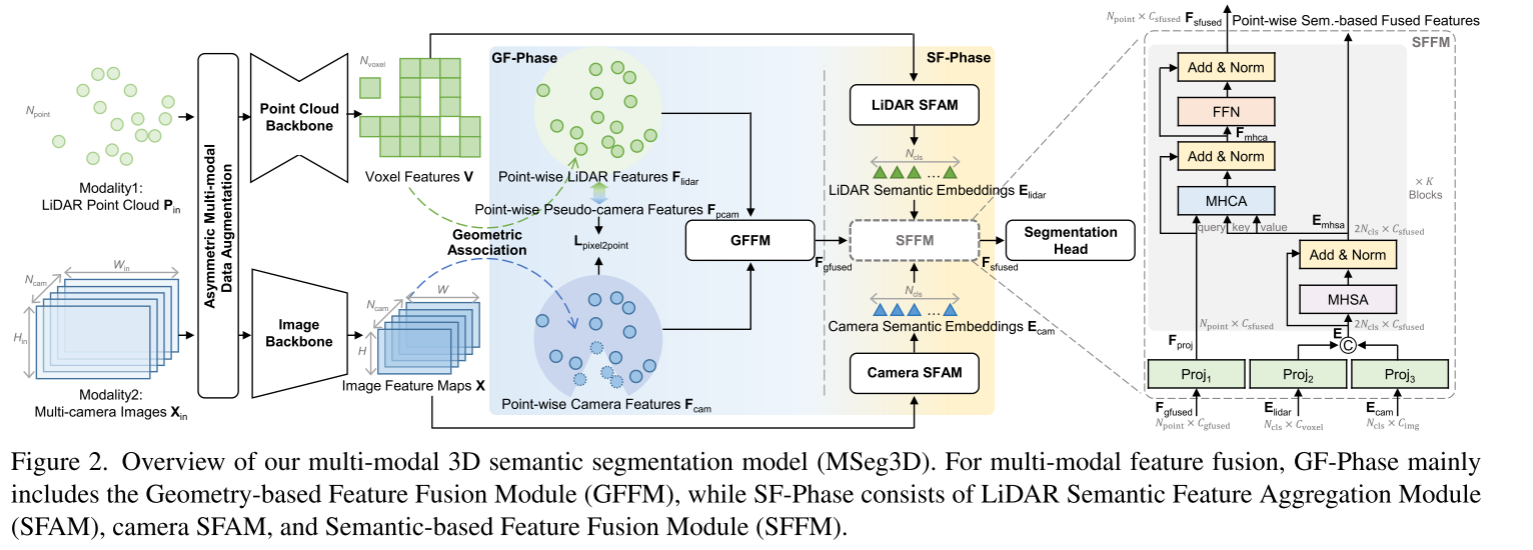
3.2 GF-Phase: Geometry-based Feature Fusion 基于几何的GF-Phase特征融合
点中心分割促使我们利用LiDAR与多相机的几何关联,将体素特征V、图像特征X映射到 中的点,逐点LiDAR特征
中的点,逐点LiDAR特征 ,逐点相机特征
,逐点相机特征 ,通过使用激光雷达和多相机的的几何关系。
,通过使用激光雷达和多相机的的几何关系。
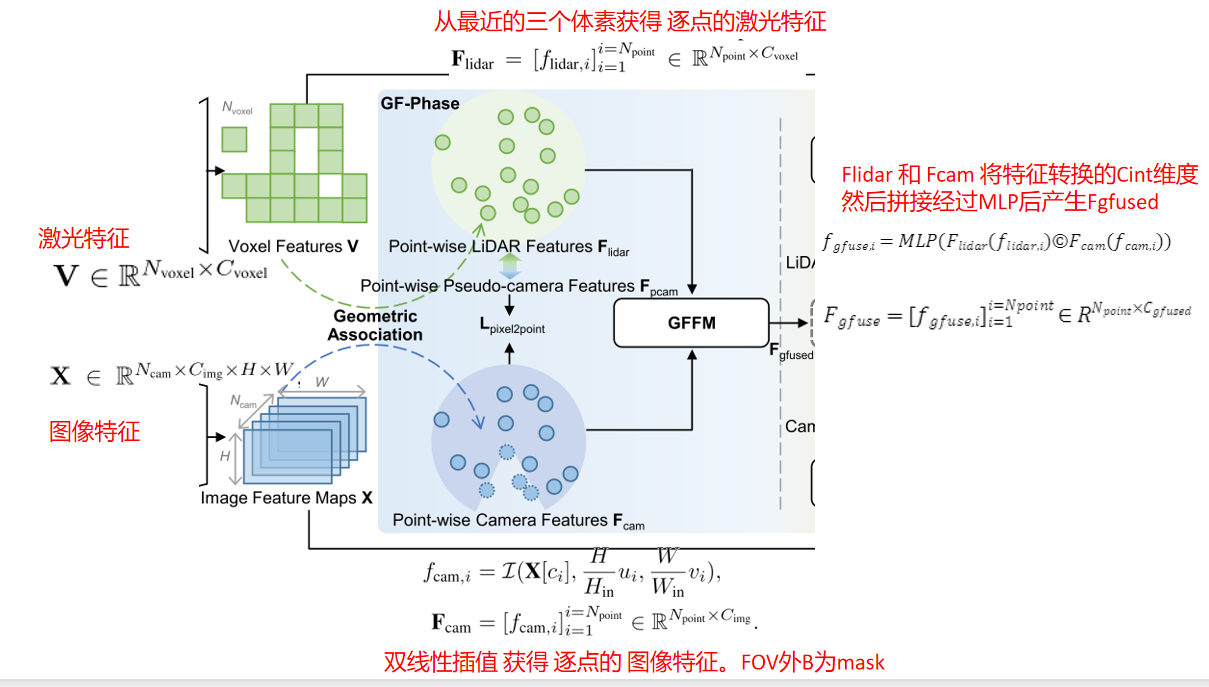
从体素和像素学习点特征
我们反体素化 体素特征V 为逐点LiDAR特征 以增强逐点融合和分割。给定一个点,我们从三个最近的相邻体素[22]插值它的点特征。
以增强逐点融合和分割。给定一个点,我们从三个最近的相邻体素[22]插值它的点特征。
对于LiDAR特征 的第i个点
的第i个点 ,我们利用已知的点式图像坐标
,我们利用已知的点式图像坐标 对ci局部相机内的图像特征映射
对ci局部相机内的图像特征映射 进行双线性插值I,如式1。零被临时填充到相机视场之外的那些点,这允许每个点用维度特征
进行双线性插值I,如式1。零被临时填充到相机视场之外的那些点,这允许每个点用维度特征 装饰。为了区分外面的点,我们设置元素的二进制掩码B,当他们是外部点为0,否则为1。
装饰。为了区分外面的点,我们设置元素的二进制掩码B,当他们是外部点为0,否则为1。
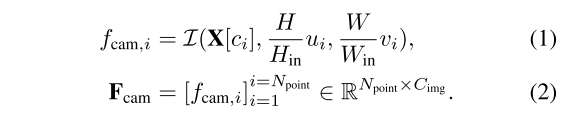
基于几何的特征融合模块(GFFM) Geometry-based Feature Fusion Module
首先通过使用全连接层 和
和 将
将 和作为
和作为 维度,并将它们连接在一起以便使用另一个MLP将
维度,并将它们连接在一起以便使用另一个MLP将 输出通道连接在一起,如
输出通道连接在一起,如 和
和 。GF-Phase主要将多模态特征与几何线索相结合,称为基于几何的特征融合阶段。
。GF-Phase主要将多模态特征与几何线索相结合,称为基于几何的特征融合阶段。
3.3. SF-Phase: Semantic-based Feature Fusion基于语义的特征融合
虽然简单而有效的GF-Phase通过对两种模式的无偏考虑,在视场交叉点内产生了可观的性能收益,但仍有三个缺陷有待解决。
(1)外面的点仍然不能恢复它们真实的相机特征。
(2)不同区域模式之间的相对重要性不同[5,58],这在GF-Phase中被忽略了。
(3)没有针对类别语义表示的显式关系建模[18,19]。如图2所示,我们进一步提出了GF-Phase之后的SF-Phase。除了欧几里德空间中的几何关联外,我们将LiDAR特征和相机特征聚合为分类语义嵌入,如 和
和 ,以便在隐藏的语义空间中进行多模态融合。
,以便在隐藏的语义空间中进行多模态融合。
激光雷达语义特征聚合模块LiDAR Semantic Feature Aggregation Module (LiDAR SFAM)
LiDAR SFAM从体素特征V开始,以聚集的 LiDAR语义嵌入
LiDAR语义嵌入 结束。对于类,我们假设
结束。对于类,我们假设 ,分布矩阵
,分布矩阵 。当D[j, i]更接近1时,表示第i个体素比其他体素更有可能属于第j个类别,因此在[j]中有更多的贡献。否则,第i个体素对[j]的贡献应该更小。现在我们可以通过矩阵乘积计算
。当D[j, i]更接近1时,表示第i个体素比其他体素更有可能属于第j个类别,因此在[j]中有更多的贡献。否则,第i个体素对[j]的贡献应该更小。现在我们可以通过矩阵乘积计算 。计算
。计算 还需要两个步骤(方程式3 ~ 4)。我们首先使用基于mlp的辅助体素分割头
还需要两个步骤(方程式3 ~ 4)。我们首先使用基于mlp的辅助体素分割头 预测体素特征V上的中间分割
预测体素特征V上的中间分割 。然后,我们在体素之间执行一个空间softmax,将每个类别的值归一化为(0,1)。
。然后,我们在体素之间执行一个空间softmax,将每个类别的值归一化为(0,1)。

为了获得更精确的 ,我们在公式15中使用体素分割监督来明确地引导
,我们在公式15中使用体素分割监督来明确地引导 。
。
相机语义特征聚合模块(Camera SFAM)
(Camera SFAM)类似地使用另一个分布矩阵 和另一个辅助图像分割头
和另一个辅助图像分割头 ,由简单的FCN头[34]实现,从图像特征映射聚集
,由简单的FCN头[34]实现,从图像特征映射聚集 。不同之处在于相机SFAM是用跨Ncam本地相机的图像特征映射的所有
。不同之处在于相机SFAM是用跨Ncam本地相机的图像特征映射的所有 像素设计的,其中为 ×H ×W。
像素设计的,其中为 ×H ×W。
首先通过 预测中间分割
预测中间分割 。注意,
。注意, 和X通过移位和重塑操作被重新排列为
和X通过移位和重塑操作被重新排列为 和
和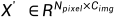 。Eq. 7中最终的相机语义嵌入是
。Eq. 7中最终的相机语义嵌入是 和X '的矩阵乘积,其中归一化是在
和X '的矩阵乘积,其中归一化是在 上应用spatial softmax的结果,如Eq. 6。
上应用spatial softmax的结果,如Eq. 6。

需要注意的是,在这样的三维语义分割数据集中,图像分割标注无法指导 [3,37]。然而,我们也通过跨模态语义监督方案来解决这一问题,该方案在Eq. 16和Eq. 17中详述。
[3,37]。然而,我们也通过跨模态语义监督方案来解决这一问题,该方案在Eq. 16和Eq. 17中详述。
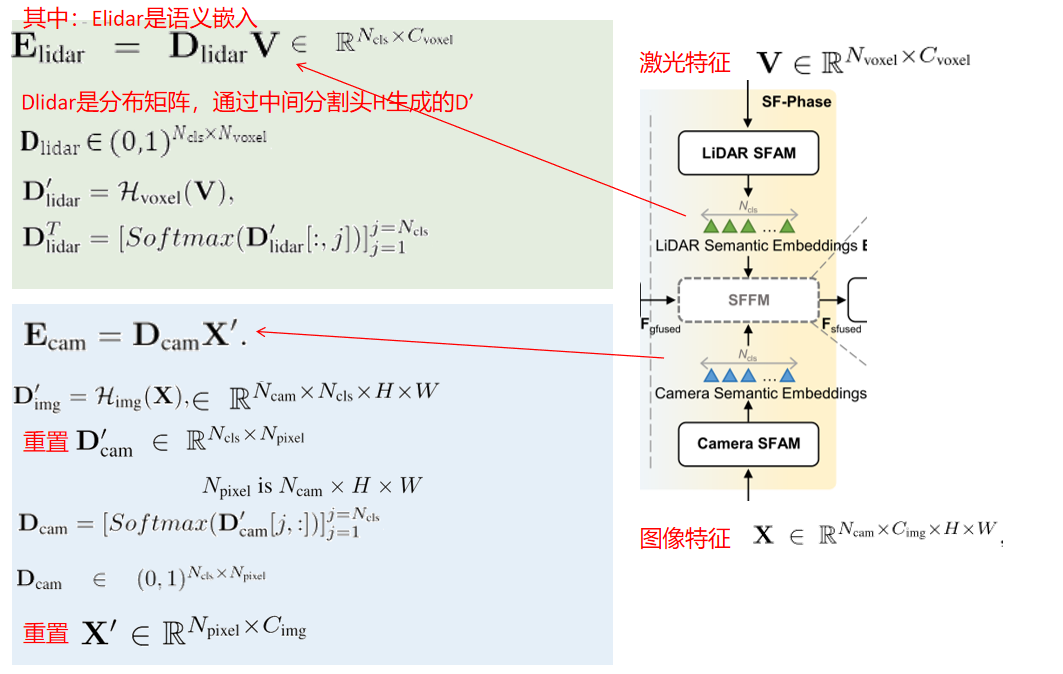
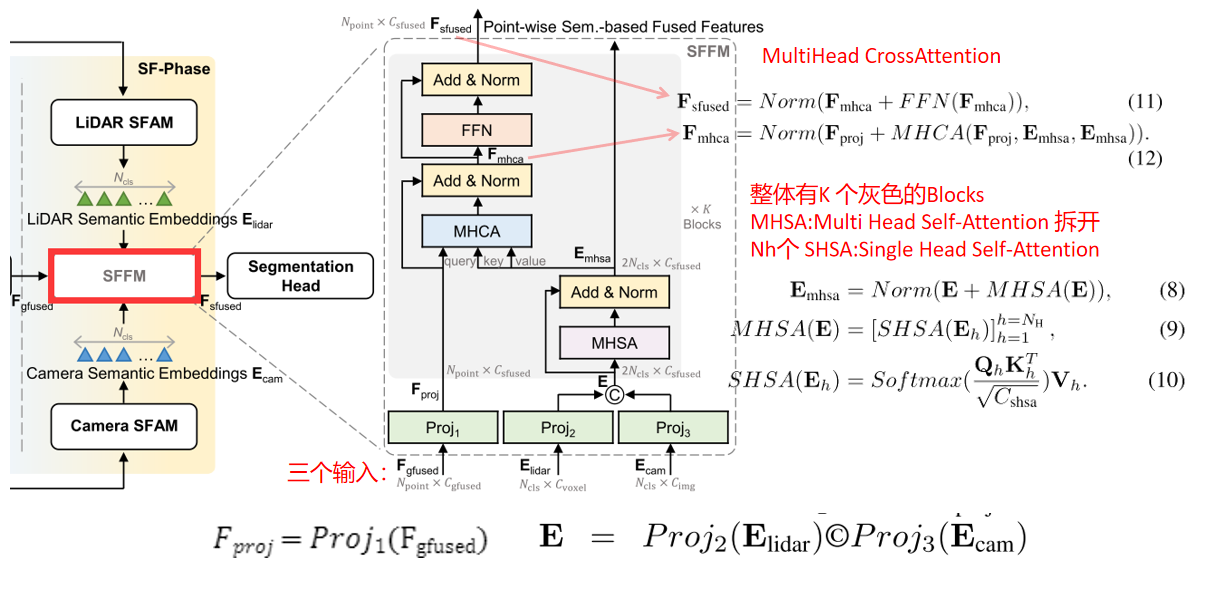
基于语义的特征融合模块(Semantic-based Feature Fusion Module (SFFM)
如图2中右虚线框所示,给定基于点几何的融合特征 、基于类别语义嵌入特征和的输入,SFFM首先将它们分别投射到
、基于类别语义嵌入特征和的输入,SFFM首先将它们分别投射到 维度空间中,分别为
维度空间中,分别为 和
和 。在SFFM中叠加K个灰块之前,我们将投影的多模态语义嵌入连接在一起,
。在SFFM中叠加K个灰块之前,我们将投影的多模态语义嵌入连接在一起, ,可以将其视为一个字典,从LiDAR和摄像机的角度描述每个类别的典型特征。
,可以将其视为一个字典,从LiDAR和摄像机的角度描述每个类别的典型特征。
在每个灰色块中,我们使用multihead Self-Attention (MHSA)[41]作为Eq. 8对所有 类别语义嵌入之间的语义关系建模,其中Norm表示LayerNorm操作。设
类别语义嵌入之间的语义关系建模,其中Norm表示LayerNorm操作。设 为
为 ,则MHSA可分解为
,则MHSA可分解为 单头自注意(SHSA)操作,
单头自注意(SHSA)操作, 为
为
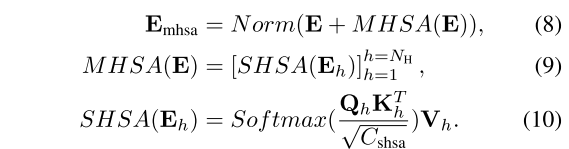
由于E包括Elidar和Ecam,注意矩阵

直观地包括Elidar→Elidar、Elidar→Ecam、Ecam→Elidar、Ecam→Ecam四个部分的关系建模。
在将E更新为Emhsa后,我们将逐点投影特征Fproj与语义嵌入特征Emhsa进一步融合,在Eq. 12中分别使用multihead CrossAttention (MHCA)进行语义关系建模,在Eq. 11中分别使用前馈网络(FFN)进行特征嵌入。

与Eq. 8不同,Eq. 12中的MHCA从点状特征Fproj中设置查询Q,并从语义嵌入Emhsa中设置键K和值V。因此,我们计算一个形状为Npoint × 2Ncls的注意矩阵,在GF-Phase的配对几何关联之外,集中聚合相对于单个点的更重要的语义嵌入。遵循多头注意[4]的常用用法,将K(即6)灰块进行堆叠。
SFFM的讨论
multihead attention[41]是一种有用的通用技术[4,28,47],虽然没有在本文中提出,但它可以有效地适应我们不同动机和设计的多模态特征融合。
i)在Eq. 12中,MHCA使点方向特征能够关注多模态语义嵌入,从而使得内点和外点都能得到表达性多模态语义嵌入的一致支持。
ii) MHCA注意矩阵计算两种模式对每个点的相对重要性,改进了GF-Phase模式的无偏考虑。
iii) Eq. 8中的MHSA明确地模拟了范畴内模态和模态间的语义关系,从而推导出共性学习。
iv) LiDAR SFAM和Camera SFAM用Nvoxel/Ncls和Npixel/Ncls次数将体素特征V和图像特征X’的长序列聚合成Elidar和Ecam的短序列,实现了对多头注意力的高效计算。
3.4跨模态特征补全
如图2所示,设置具有像素到点损失 (Eq. 13)的交叉模态特征完成模块,其中逐点伪相机特征
(Eq. 13)的交叉模态特征完成模块,其中逐点伪相机特征 由另一个基于mlp的
由另一个基于mlp的 从逐点LiDAR特征Flidar映射为逐点伪相机特征()。在实践中,我们计算和内部的点之间的均方误差损失
从逐点LiDAR特征Flidar映射为逐点伪相机特征()。在实践中,我们计算和内部的点之间的均方误差损失 ,以便从正确配对的交叉模态特征关系中学习。
,以便从正确配对的交叉模态特征关系中学习。

注意,外面的点被二进制掩码B忽略了,它在GF-Phase被提到。为了优化Fpcam的学习,分离了Fcam的梯度。
我们之所以采用这种跨模式功能完成模块,是出于两个动机:
i)优化迫使LiDAR特征通过模仿相机特征,然后在推理阶段,Eq. 14将学习到的伪像特征,替换原来中填充的零,作为交叉模态特征补全,增强特征学习。因此,我们进一步缩小内外点之间的特征差距。
ii) 将丰富的外观先验从摄像机分支传输到LiDAR分支,并具有有效的一致性约束,增强训练阶段的模内特征学习。

3.5跨模态语义监督Cross-modal Semantic Supervision
点监督Point Supervision
设Npoint元素的Y为逐点的3D语义分割标签。Y[i]的值在[0,Ncls−1]中,0表示被忽略的类别。在 的基础上建立了一个基于MLP的点分割头
的基础上建立了一个基于MLP的点分割头 ,用于三维分割预测
,用于三维分割预测 。根据[6,21,66],我们采用点损失Lpoint作为交叉熵损失
。根据[6,21,66],我们采用点损失Lpoint作为交叉熵损失 和lovaszsoftmax损失Llovasz[2]的组合作为
和lovaszsoftmax损失Llovasz[2]的组合作为 。
。
点对体素监督Point-to-voxel Supervision
为了引导式3中的 ,体素损失
,体素损失 定义为:
定义为:


其中, 元素的体素标签
元素的体素标签 可以从体素中点的标签确定。为了避免中的歧义,包含多个类别的点的体素的标签被设置为0作为被忽略的类别。
可以从体素中点的标签确定。为了避免中的歧义,包含多个类别的点的体素的标签被设置为0作为被忽略的类别。
点对像素监控Point-to-pixel Supervision
如何仅使用点标签来正确引导 (Eq. 5)的问题仍然没有解决。对于每个训练样本的,我们初始化一个
(Eq. 5)的问题仍然没有解决。对于每个训练样本的,我们初始化一个 的全零的
的全零的  作为图像分割标签。然后,我们将每个点投影到下采样的图像平面上,并检索对应最近(·)像素的点标签Y[i],如公式16。虽然生成的图像标签是稀疏的,但它提供了足够的监督。在SM中,图S2和图S3提供了的可视化,表明这些稀疏的点对像素监控可以传播到其他具有相似外观的区域,从而正确引导。由于是稀疏的,所以我们只计算公式17中的基本交叉熵损失Lce。
作为图像分割标签。然后,我们将每个点投影到下采样的图像平面上,并检索对应最近(·)像素的点标签Y[i],如公式16。虽然生成的图像标签是稀疏的,但它提供了足够的监督。在SM中,图S2和图S3提供了的可视化,表明这些稀疏的点对像素监控可以传播到其他具有相似外观的区域,从而正确引导。由于是稀疏的,所以我们只计算公式17中的基本交叉熵损失Lce。

总的损失函数Total Loss Function.
为了联合优化所提分割模型中的所有模块,总损耗将不同模式的损耗项组合成L为
α1Lpoint + α2Lp2v + α3Lpoint2pixel + α4Lpixel2point
其中α1 ~ α4设为1.0、1.0、0.5、1.0以平衡损耗项。
3.6 非对称多模态数据扩充
分割输出和我们的多模态融合机制是点为中心的。在Eq. 1和Eq. 16中,只要预先计算坐标对并保持同步的所有点之间的坐标对的顺序,点和像素总是可以由坐标对(xi, yi, zi)和(ci, ui, vi)连接起来。有了这个排序约束,我们可以灵活地解耦多模态数据增强:
i)我们可以保留表1中所有的LiDAR变换,而图像和坐标(c, u, v)保持不变。
ii)当坐标(c, u, v)与图像同步变换后,我们可以进一步将表1中仅对相机进行的变换应用到图像上,这与LiDAR变换是不对称的。
iii)由于图像视图是由本地摄像机自然分割的,我们可以在本地摄像机的图像之间进行独立转换。

这种不对称不仅存在于激光雷达和摄像机领域,也存在于局部摄像机领域。因此,我们使用引入的相机转换和保留的LiDAR转换,显著丰富了用于3D语义分割的多模态数据增强。除了表1之外,还可以利用更多潜在的转换。
(这里其实没看太懂,为什么可以只改点云图像,这种不应该两种数据一起改吗)
4. 实验
4.1实验设置
nuScenes数据集分割了28,130个训练样本、6,019个验证样本和6,008个测试样本[3,11]。每个nuScenes样本包含相对稀疏的32束点云和由6个摄像机捕获的RGB图像:前、前左、前右、后、后左和后右。由于激光雷达和摄像机的垂直视场不同,外部的点投影在图像底部的下方。按照官方规定,Ncls为17。语义分割标注只适用于点云,而不适用于图像。
Waymo三维语义分割数据集包括23,691个训练样本,5,976个验证样本,2,982个测试样本[37]。每个样本包含64光束的点云和由5个摄像机捕获的RGB图像:前、前左、前右、左右和左右。waymo自用车没有后置摄像头,因此更多的外置点不公平地增加了多模态分割的难度。Ncls为23。类似地,语义分割标注只在点云上。
SemanticKITTI数据集由64波束[1]激光雷达采集。在[10,50,66,67]之后,序列00到10(不包括08)有19,130个训练样本,序列08有4,071个验证样本。它只提供前视摄像头的图像。Ncls为20。
评估指标是平均交叉合并(mIoU)定义为1 C PNcls−1 C =1 TPc TPc+FPc+FNc,其中TPc、FPc、FNc表示ncls−1有效类别中第C类的真阳性、假阳性和假阴性预测的数量。此外,nuScenes计算另一个度量fwIoU,方法是用类别的点频率加权分类IoU。
设置。虽然轻量级的LiDRA-only基线模型可以用更大的批数和更多的epoch来训练,以获得相对更好的结果,但我们仍然在相同的时间表下训练所有模型:一批32个随机样本,分布在16个特斯拉V100 gpu上,24个epoch。关于点云体素化、网络架构、模型训练和推理的更多实现细节都包含在SM中。
4.2 与最新方法的比较
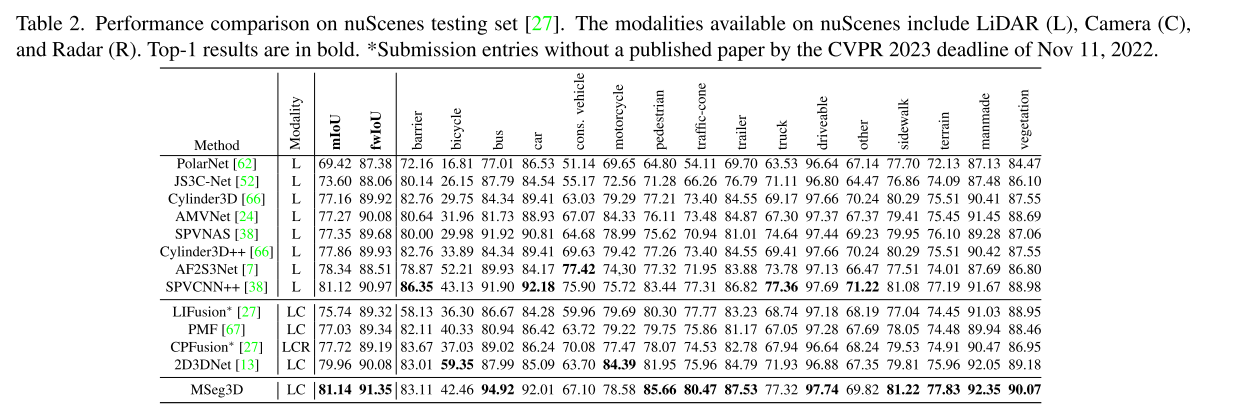
nuScenes的结果。从表2可以看出,多模态方法反直觉地远远落后于仅使用激光雷达的方法。在nuScenes基准测试[27]的前20个提交作品中,只有4个多模式方法。Cylinder3D++,SPVCNN++、LIFusion和CPFusion的详细信息在提交前不可用。我们的框架通过多模态融合机制和非对称多模态数据增强实现了最佳的mIoU和fwIoU。特别是,我们的方法在具有挑战性的小对象,如行人和交通锥上取得了卓越的性能,在这些地方,激光点通常是不够的,只有激光雷达的方法。我们的方法也明显优于表2中所有公共和私有的多模态提交。
Waymo的结果。我们在表3中对Waymo基准[45]进行评估,其中LiDAR传感器提供更密集的激光点,且多摄像机不包括后视镜。这种密集的点云和不完整的相机视场不公平地削弱了多种模式的优势。尽管如此,我们的方法仍然使用一般的点云骨干网实现了最先进的性能[9,35]。我们相信,通过整合来自其他最先进的激光雷达方法的更强大的点云骨干网,性能可以得到改善。

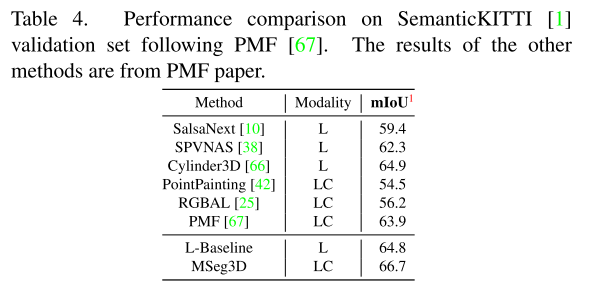
SemanticKITTI结果。在竞争激烈的nuScenes和Waymo数据集上的对比验证了我们的方法的有效性,表4显示了在SemanticKITTI[1]上的实验比较。由于SemanticKITTI只提供前视图像,PMF[67]评估视场交点内的多模态分割性能。在表4中,我们根据PMF报告内部点的mIoU1。我们的方法不仅显示了激光雷达方法的改进,而且优于其他多模态方法。
4.3消融研究
表5从各点与内点之间的性能差距以及多模态数据增强两个角度研究了多模态所带来的困难。表5中的实验从使用基本GF-Phase融合的多模态模型的一个普通变体开始,没有多模态数据增强。mIoU相对于mIoU1而言表现较差,因为基于几何的特征融合理想地忽略了相机特征缺失的外部不可避免的点[20,25,67],这也促使我们利用跨模态特征补全和基于语义的fs - phase来弥补mIoU与mIoU1之间的性能差距。此外,在第2行和第1行中,如果我们弃用不能直接应用于两种模式的增广转换,多模态分割性能将会恶化。然而,提出的非对称多模态数据增强可以在点云和图像上积累转换,从而在两个数据集上实现最佳性能。

多模态特征融合模块。由表6可知,我们的监督跨模态特征补全和SF-Phase对mIoU和mIoU1都有好处,且差距逐渐缩小。在第3行中,Lpixel2point也可以带来改进,这说明将外观信息从密集的图像转移到稀疏的点云是适用的,有利于联合特征学习。在第4行,用伪相机特征来完成相机特征,有利于缩小内外点之间的特征差距。最后,SF-Phase进一步将mIoU和mIoU1之间的差距缩小到0.10和0.56的最小值,通过基于语义的特征融合解决了几何关联的局限性。因此,我们将最后一行中的模型设置为我们最终的框架。

mIoU击穿距离。图3为表6中模型对应的基于距离的评价。仅使用激光雷达的模型在远距离会退化,因为有更多的稀疏点。相反,第5行多模态模型有效地缓解了性能的下降。在图3 (a) (b)中,第5行多模态模型与第1行LiDAR-only模型之间的改进也随着距离的增加而增加,这是因为稀疏度的增加。图3 (c)和(d)进一步分析了Waymo上的多模态模型改进不如nuScenes上相似的原因。Waymo点云的点密度更大,减少了对图像的依赖。由于Waymo没有后置摄像头,更多的点分布在不同的距离上。虽然更多的外点阻碍了多模态融合的适用性,但我们最终的多模态模型在第5行Waymo上仍有0.56 mIoU的低性能差距。

鲁棒性相机故障。在表7中,我们的MSeg3D在相机故障的不利条件下表现良好,无需切换模型即可轻松处理实际情况。请注意,即使移除所有摄像机,MSeg3D仍然优于仅使用lidar的基线,我们的交叉模态特征完成监督在训练中提供了有效的交叉模态信息传递。

对多帧点云输入的鲁棒性。由于致密化的点可以缓解稀疏性,因此来自邻近帧的折叠激光点通常可以增强仅用于lidar的3D感知[16,52]。在表8中,我们按照[57]将提供的自我-车辆运动信息中的前几帧压缩到当前帧。对于只使用lidar的模型,在nuScenes和Waymo上的改进达到了25帧和10帧的饱和。在这样的条件下,我们的MSeg3D仍然在上一篇专栏文章中做了进一步的改进,这表明多帧点云输入可以是一个可选的扩展。

复杂性可扩展性。从表9中可以看出,由于采用了多模态输入,轻量级的图像主干还提供了显著的性能提升。性能最好的HRNet-w48是我们默认的图像骨干。然而,多摄像头的图像输入使得效率瓶颈在于图像主干,这对于自动驾驶[23]值得深入研究。我们相信实时图像分割网络,如BiSeNet[59,60]和Fast-SCNN[29]可以加速我们的方法。总的来说,我们的MSeg3D可以适应各种骨干网之间的复杂性可伸缩性,灵活地权衡性能和效率。
5. 结论
本文提出了一种基于激光雷达和多摄像机传感器的自动驾驶多模态三维语义分割方法,称为MSeg3D。我们的跨模态特征完成和基于语义的特征融合解决了一个被忽视的问题,即多模态融合只能发生在传感器视场相交处。提出的非对称多模态数据增强方法能够有效地训练多模态分割模型,并具有可靠的性能。我们的方法在nuScenes、Waymo和SemanticKITTI上实现了最先进的性能。综合实验验证了改进的有效性和鲁棒性。我们希望我们的工作能够对自动驾驶三维语义分割的多模态融合进行进一步的研究。
小结:
1、作者整篇就一个图,但是公式很多(手打好累),慢慢看下来还是挺清晰的,有耐心看完应改可以收获很多
2、数据增强的位置没太看懂,欢迎大家探讨~
3、用0填充,然后通过点云模拟出图像特征比较巧妙,推荐另外一篇 2DPASS https://blog.csdn.net/qq_53086461/article/details/127906288 ,当时看完也觉得巧妙
4、一直觉得transformer就是不同维度空间的特征交互,感觉用在这里很巧妙,既然卷积可以是三维,transformer是不是也可以是三维(虽然运算量很大)
5、有机会会复现下,不过16张v100 可太难了,不知道单卡v100能不能成功