【论文阅读】Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition
这是2017ICCV workshop的一篇文章,这篇文章只是提出了一个3D-ResNets网络,与之前介绍的一篇文章链接地址非常非常相似,在结构上只有一点点不同,既然如此,那么我为什么还要介绍这一篇文章呢,因为本文最大的贡献就是它的github代码。这篇文章的代码算是我的启蒙代码,写得非常地整洁规范,所以我极力推荐大家下载下来看一看。
正文
本文提出了3D-ResNets网络,该网络基于2DResNets网络而来,虽然文章只实验了18层和34层的网络,但是在它的github中提供了各种深度的网络。它的github中提供了效果很好的用于时空特征提取的在kinetics上预训练了的模型,建议大家可以star一下。
3D-ResNets网络结构
文章提出的3D-ResNets网络结构如下表所示:
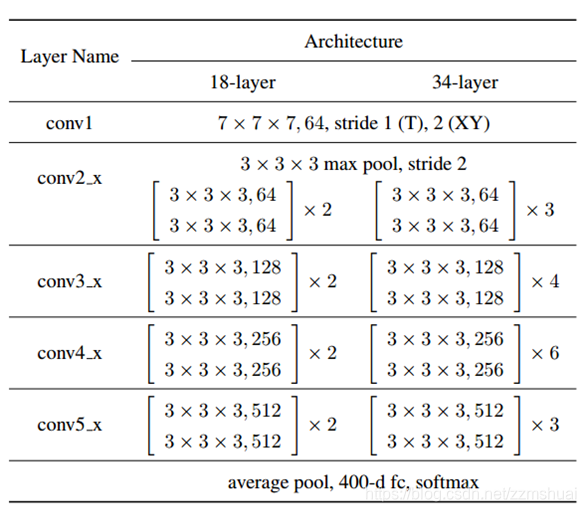
可以看到该网络结构真的与之前介绍的一篇非常相似,这里就不再多赘述了。网络的输入为16x112x112。
训练细节
训练的时候:优化算法为动量随机梯度下降法,学习率初始化为0.1,当验证集的准确率连续下降3次时学习率乘以0.1,动量为0.9,weight decay为0.001,batch size为256。测试的时候,视频被分成若干不重叠的16帧的视频段,结果为所有视频段的结果的平均。输入的16帧视频是从原视频中均匀采样得到的,使用了数据增强的方法,包括:
- 在5个不同的尺度下进行空间裁剪,尺度设置为
- 空间裁剪时在视频帧的4个角和中心处的进行空间裁剪
- 水平随机翻转
实验结果
文章使用3D-ResNets和C3D分别在kinetics上进行了训练,实验结果如下图所示:
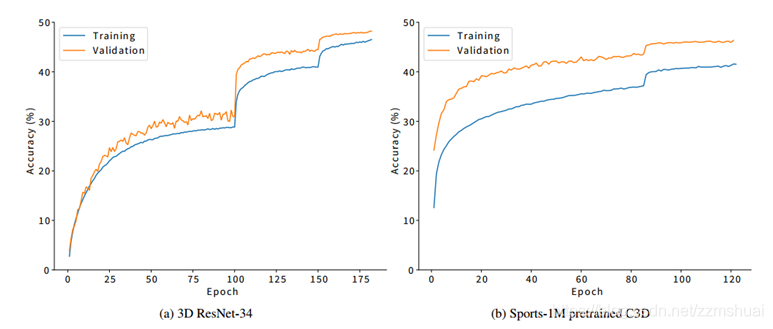
可以看到上图右侧C3D的验证集准确率要高于训练集,所以欠拟合了。而3D-ResNets则没有欠拟合,表明对于kinetics数据集来说,C3D网络太小了。
结论
介绍这篇论文主要还是为了让大家关注它的github,哈哈。