1. 概述
作者将GAN(原始的)应用到视频去雾中,由于2D卷积只能提取输入的位置信息,针对视频连续帧具有时间信息的特点作者采用了3D卷积(部分卷积层中),取得了SOTA的效果。
2. 模型结构
生成模型如图1所示,
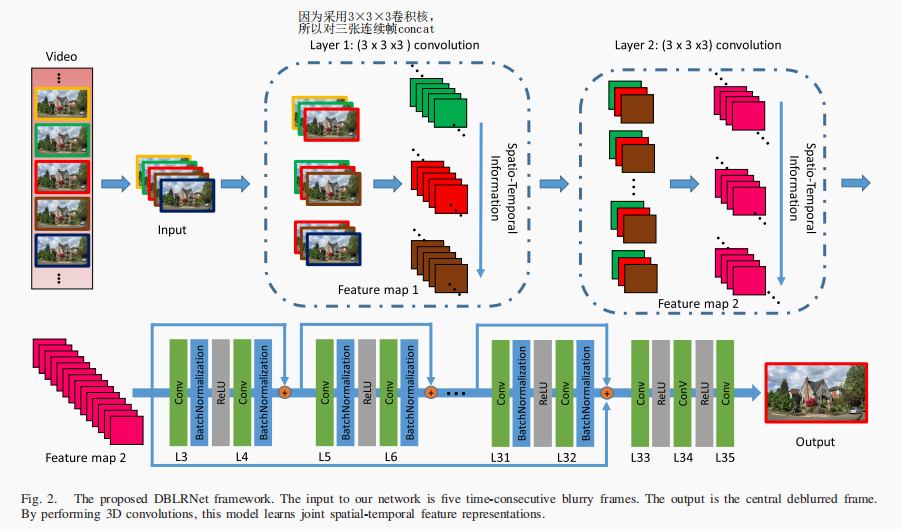
图1 生成模型。
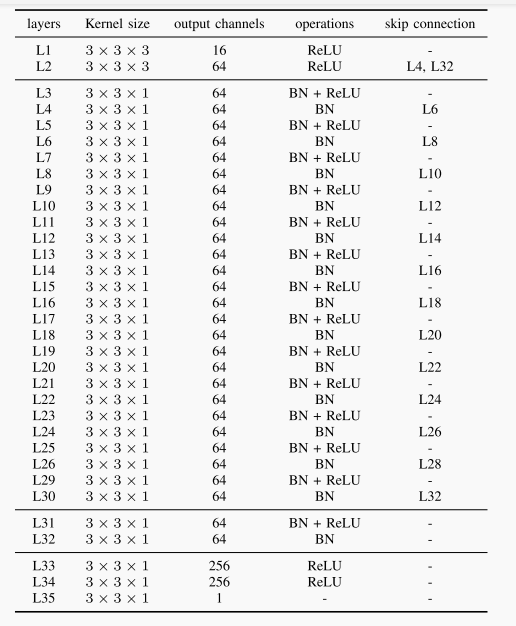
表1 生成模型。它是由两个卷积层(L1和L2), 14个残差块,两个卷积层(L31和L32)没有跳转连接,和三个额外的卷积层数(L33、L34和L35)组成。
作者通过对不同数量(3,5,7,9)的连续帧作为输入,对模型性能进行比较,选择了5作为模型输入连续帧的数量。因为作者采用的是3×3×3的卷积核,因此将三张连续帧进行concat,然后进行卷积。
在输入前,作者将RGB图像转换到YCbCr色彩空间,并将Y通道图像(光照强度通道,即灰度图)作为输入(“since the illumination is the most salient one”),得到模型输出后在利用原始CbCr信息将输出转换到RGB空间。
由于作者在卷积过程中保持输出特征图大小不变,因此没有采用上采样,下采样和反卷积。
将该模型称为视频去雾是因为它的输入是视频,输出也是视频。具体来说,模型对输入拦截五张连续帧作为输入,输出一张复原图,如此连续的输入输出便达到视频输入视频输出的效果。
模型整体结构如图2所示:
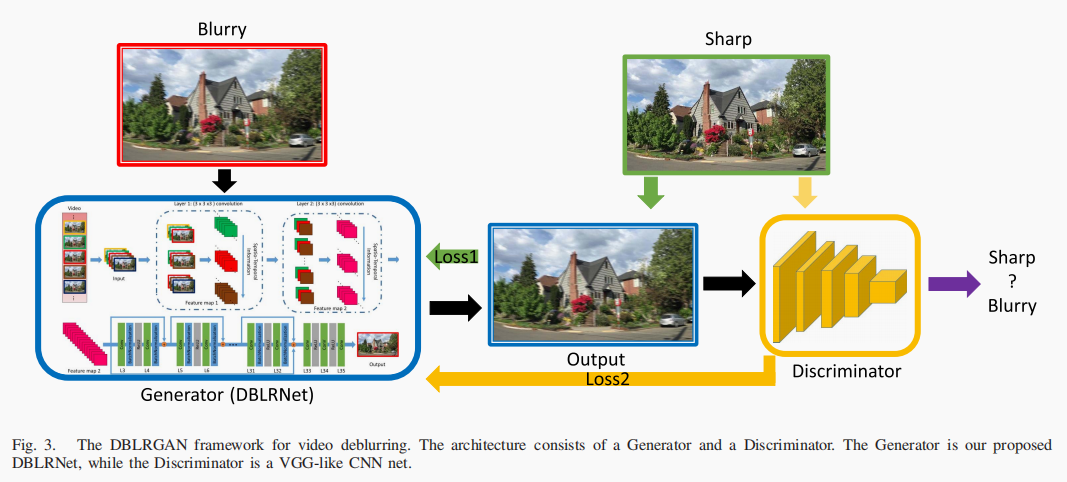
图2 GAN的整体网络结构
其中判别器借鉴了VGG网络。
3. 损失函数
即为图2中的loss1。
表示清晰图像,即GT。
即为图2中的loss2。
整体损失如式3表示:
4. 参考文献:
[1] Kaihao Zhang , Wenhan Luo , Yiran Zhong, Lin Ma , Member, IEEE, Wei Liu , and Hongdong Li, “Adversarial Spatio-Temporal Learning
for Video Deblurring.” IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 28, NO. 1, JANUARY 2019.
