【论文阅读】Human Action Recognition using Factorized Spatio-Temporal Convolutional Networks
这是一篇15年ICCV的论文,在15年的时候,3D卷积网络刚刚兴起,但是因为3D卷积网络的参数量较多,而且训练数据的规模也没有现在这么大,所以网络的参数非常不易优化,这个时候,限制3D卷积网络性能的主要是数据。文章根据当时3D网络的局限性,将 “3D空间时间学习“ 分解为 “2D空间+1D时间学习”,提出了一种空间时间分解卷积网络(factorized spatio-temporal convolutional networks,
)。
级联地组合视频中的时空信息,在网络的底层,使用2D空间卷积核学习视频帧的空间appearance特征。在网络的顶层,使用1D时间卷积核学习视频的时间motion特征。这种网络结构与3D卷积网络相比大大减少了参数量,所以对训练数据量要求比较低。
插一句嘴:自从17年Google的DeepMind提出了kinetics-400,kinetics-600数据集以后,数据量不再是3D卷积网络的局限[1],人们设计了很多巧妙的3D卷积网络,很大地促进了3D卷积网络的发展。
论文地址:下载链接
代码(pytorch):下载地址
网络结构
分解原理
正如上一篇介绍C3D的博客所说(链接地址),不考虑channel的情况下,3D卷积核
的尺寸为
,我们从
表示的集合中抽出一个子集
,该子集可以由一个2D空间卷积核
和一个1D时间卷积核
的外积来表示,如下式所示:
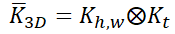
其中
表示外积(outer product),我画了一张图方便理解,如下图所示。

虽然完成
的分解后,只能表达原3D卷积核集合中的一个子集,牺牲了一定的表达能力,但是存在很多优点,比如:
- 卷积核的尺寸可以认为从 降低成了 ,大大地减小了网络的参数量,这在当时数据规模不大的情况下还是很有意义的。
- 分解后的2D空间卷积核还可以提前在ImageNet上预训练,这对于提升最终的结果还是很有帮助的。
同时文章也认为牺牲了的表达能力可以通过学习冗余的2D和1D卷积核来弥补。
详细的网络结构
文章根据上述分解的原理,提出了一种
网络,其结构如下图所示:
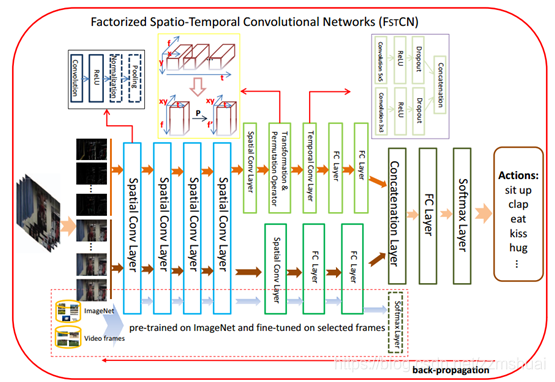
该网络的总体思想是级联地提取视频中的时空信息,在网络的底层使用2D空间卷积核,在网络的顶层使用1D时间卷积核。我们从底到顶一步一步地来分析网络的结构。
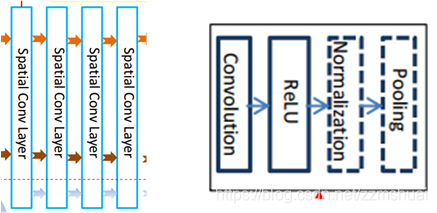
首先左侧蓝色方框中的为2D空间卷积层,也被称为SCL层(spatial convolutional layer),其作用是提取视频每一帧的空间appearance特征。每一层都是(2D卷积核+Relu+LRN+Maxpooling)的结构,如右侧黑色方框中所示。

然后紧接着是空间卷积(SCL)和时间卷积(TCL)的并行分流,下方为空间卷积,上方为时间卷积,文章认为添加并行的空间卷积(SCL),可以提取视频中更加丰富的appearance视觉特征。

最后详细介绍一下时间卷积,可以看到时间卷积流中有两层比较特殊,分别是 T&P层和TCL层,我们分别进行介绍。
- T&P Operator:该层的目的是为了对输入的feature map的维度进行变换,方便后续的TCL层沿着时间卷积。我们知道SCL层输出的feature map的尺寸为 。因为当时的深度学习框架还不成熟,所以对该尺寸的feature map单独实现时间维度的卷积还很难实现,于是作者想到了一种巧妙的方法,如上图中间的黄色方框内容所示,作者首先将4D尺寸的feature map沿着高和宽展开,得到展开后的feature map的尺寸为 ,我们颠倒一下feature map的维度顺序为 ,从而可以直接在此3D的feature map上使用2D卷积核完成对时间维度和channel维度的卷积。上述维度展开之后还有一种变换操作,它使用一个变换矩阵 对 feature map中的 维度进行变换,变换后的feature map的尺寸为 ,文章认为这个变换是为了调节 维度的尺寸,但是后面实验又设置了 →_→。(在代码实现中,因为考虑到目前深度学习框架都比较成熟,可以直接实现 4D feature map中的时间维度卷积,所以我对T&P层进行了简化)
- TCL层:TCL层是时间卷积层(temporal convolutional layer),其结构如上图最右的紫色方框内容所示,有点参考了Inception模块的结构,整个TCL层有两个分支,分别使用 和 大小的2D卷积核,这样做的目的是可以捕获不用时间尺度的运动信息。
训练细节
在训练阶段,batch size设置为32,优化方法为动量SGD,动量设置为0.9,weight decay设置为0.0005,视频帧输入的尺寸为 。(输入的视频时长没看到,在复现代码中定位16帧)
其他补充
论文中也有一些其他值得学习的技巧:
- 帧差输入:文章中输入网络的视频段为 ,其中 是RGB视频,而 是RGB视频的帧差,文章认为这样输入可以捕获短时的运动信息。
- SCI[2]:是一种late score fusion的方法,在测试阶段,每一个视频会有多个视频段的预测结果,需要将这些视频段的结果融合确定整个视频的预测结果,那么如何确定每个视频段的权值呢,文章使用每个视频段预测结果的熵来确定权值。如果一个视频段结果的熵越小,我们认为这个结果的置信度越高,其在融合的时候权值越大。
探索性的实验
特征可视化
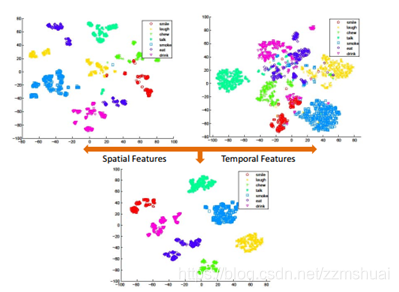
文章选了7种容易混淆的类,并对其空间特征、时间特征和融合后的特征都做了可视化,如下图所示,使用的仍是t-SNE[3]的方法,可以看到不同类的特征之间还是比较容易区分的。
feature map 反卷积可视化
文章对网络的feature map反卷积后可视化,如下图所示,可以看到响应主要还是集中在salient区域。

[1] Hara, Kensho, Hirokatsu Kataoka, and Yutaka Satoh. “Can spatiotemporal 3D CNNs retrace the history of 2D CNNs and ImageNet.” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, pp. 18-22. 2018.
[2] Wright, John, Allen Y. Yang, Arvind Ganesh, S. Shankar Sastry, and Yi Ma. “Robust face recognition via sparse representation.” IEEE transactions on pattern analysis and machine intelligence 31, no. 2 (2009): 210-227.
[3]Maaten, Laurens van der, and Geoffrey Hinton. “Visualizing data using t-SNE.” Journal of machine learning research 9, no. Nov (2008): 2579-2605.