【论文阅读】Spatio-Temporal Graph Convolutional Networks: A Deep Learning Framework for Traffic Forecasting[时空图卷积网络: 用于交通预测的深度学习框架](3)
原文地址:https://transport.ckcest.cn/Search/get/298151?db=cats_huiyi_jtxs
3. Proposed Model(模型)
3.1 Network Architecture(网络结构)
In this section, we elaborate on the proposed architecture of spatio-temporal graph convolutional networks (STGCN). As shown in Figure 2, STGCN is composed of several spatio- temporal convolutional blocks, each of which is formed as a “sandwich” structure with two gated sequential convolution layers and one spatial graph convolution layer in between. The details of each module are described as follows.
在本节中,我们详细阐述了提出的时空图卷积网络(STGCN)架构。如图2所示,STGCN由多个时空卷积块组成,每个卷积块形成一个“三明治”结构,中间有两个门控顺序卷积层和一个空间图卷积层。各模块的详细信息如下所示。
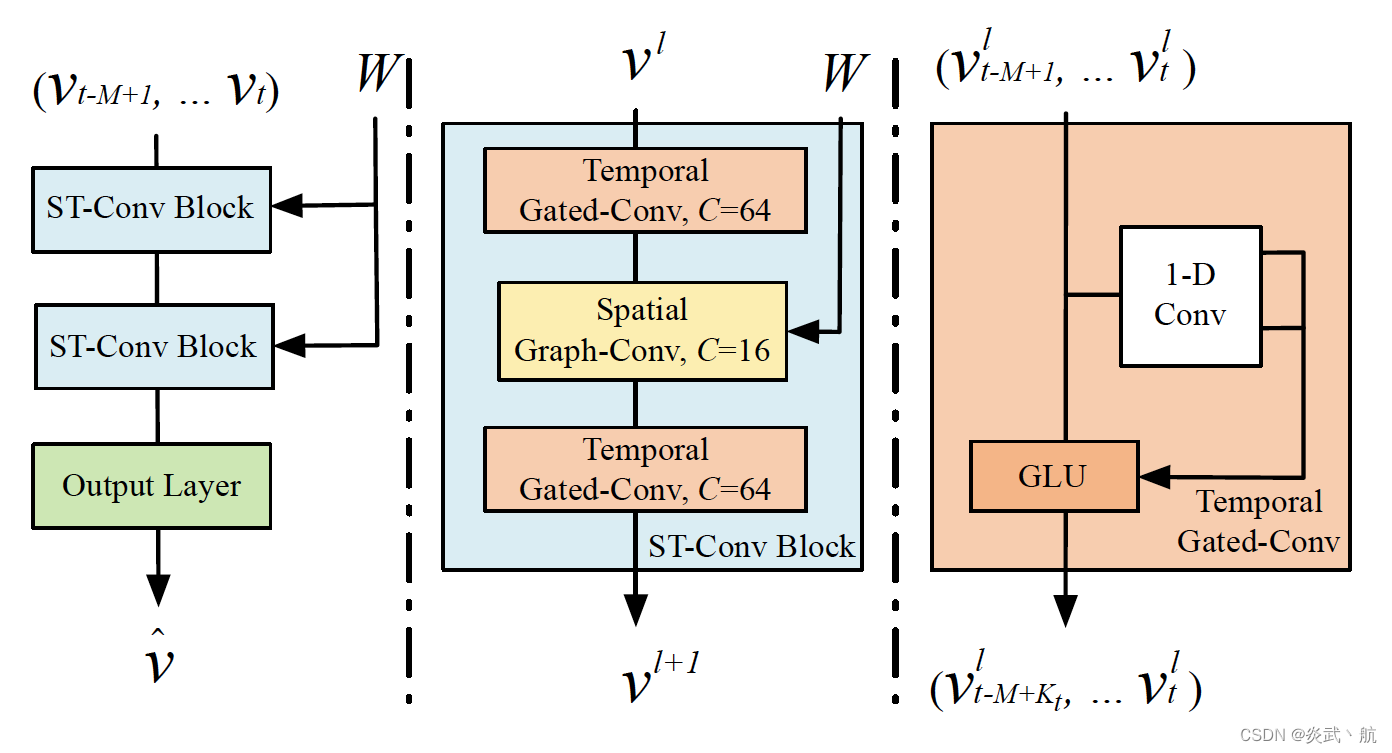
Figure 2: Architecture of spatio-temporal graph convolutional net- works. The framework STGCN consists of two spatio-temporal convolutional blocks (ST-Conv blocks) and a fully-connected output layer in the end. Each ST-Conv block contains two temporal gated convolution layers and one spatial graph convolution layer in the middle. The residual connection and bottleneck strategy are applied inside each block. The input v t − M + 1 , … , v t v_{t-M+1},…,v_t vt−M+1,…,vt is uniformly processed by ST-Conv blocks to explore spatial and temporal dependencies coherently. Comprehensive features are integrated by an output layer to generate the final prediction v ^ \hat{v} v^.
图2: 时空图卷积网络架构。STGCN框架由两个时空卷积模块(ST-Conv模块)和一个全连接的输出层组成。每个ST-Conv模块包含两个时间门控卷积层和中间的一个空间图卷积层。在每个块内部应用剩余连接和瓶颈策略。ST-Conv块对输入 v t − M + 1 , … , v t v_{t-M+1},…,v_t vt−M+1,…,vt 进行统一处理,以一致性地探索空间和时间相关性。综合功能被输出层集成,以生成最终的预测 v ^ \hat{v} v^ 。
3.2 Graph CNNs for Extracting Spatial Features(用于提取空间特征的图CNN)
The traffic network generally organizes as a graph structure. It is natural and reasonable to formulate road networks as graphs mathematically. However, previous studies neglect spatial attributes of traffic networks: the connectivity and globality of the networks are overlooked, since they are split into multiple segments or grids. Even with 2 2 2-D convolutions on grids, it can only capture the spatial locality roughly due to compromises of data modeling. Accordingly, in our model, the graph convolution is employed directly on graph-structured data to extract highly meaningful patterns and features in the space domain. Though the computation of kernel Θ Θ Θ in graph convolution by Eq. (2) can be expensive due to O ( n 2 ) O(n^2) O(n2) multiplications with graph Fourier basis, two approximation strategies are applied to overcome this issue.
交通网络通常以图的形式呈现。用数学的方法来表示路网是自然而合理的。然而,以往的研究忽略了交通网络的空间属性: 由于将交通网络划分为多个区段或网格,忽视了交通网络的连通性和全局性。即使是网格上的二维卷积,由于数据建模的局限性,它也只能粗略地捕获空间局部性。因此,在我们的模型中,直接对图结构数据使用图卷积来提取空间域中高度有意义的模式和特征。虽然通过Eq.(2)计算图卷积中的卷积核 Θ Θ Θ 可能会由于图傅里叶基的 O ( n 2 ) O(n^2) O(n2) 乘法而代价高昂,但我们采用了两种近似策略来克服这个问题。
Chebyshev Polynomials Approximation To localize the filter and reduce the number of parameters, the kernel Θ Θ Θ can be restricted to a polynomial of Λ Λ Λ as Θ ( Λ ) = ∑ k = 0 K − 1 θ k Λ k Θ(Λ)=∑_{k=0}^{K-1}θ_k Λ_k Θ(Λ)=∑k=0K−1θkΛk , where θ ∈ R K θ∈\R^K θ∈RK is a vector of polynomial coefficients. K K K is the kernel size of graph convolution, which determines the maximum radius of the convolution from central nodes. Traditionally, Chebyshev polynomial T k ( x ) T_k(x) Tk(x) is used to approximate kernels as a truncated expansion of order K − 1 K-1 K−1 as Θ ( Λ ) ≈ ∑ k = 0 K − 1 θ k Λ k ( Λ ~ ) Θ(Λ)≈∑_{k=0}^{K-1}θ_k Λ_k (\tilde{Λ}) Θ(Λ)≈∑k=0K−1θkΛk(Λ~) with rescaled Λ ~ = 2 Λ / λ max − I n \tilde{Λ}=2Λ/λ_{\text{max}} -I_n Λ~=2Λ/λmax−In ( λ max λ_{\text{max}} λmax denotes the largest eigenvalue of L L L) [Hammond et al., 2011]. The graph convolution can then be rewritten as,
切比雪夫多项式逼近(Chebyshev Polynomials Approximation) 为了定位滤波器并减少参数的数量,卷积核 Θ Θ Θ 可以被限制为 Λ Λ Λ 的一个多项式 Θ ( Λ ) = ∑ k = 0 K − 1 θ k Λ k Θ(Λ)=∑_{k=0}^{K-1}θ_k Λ_k Θ(Λ)=∑k=0K−1θkΛk ,其中 θ ∈ R K θ∈\R^K θ∈RK 是多项式系数的一个向量。 K K K 是图卷积的核大小,它决定了从中心节点卷积的最大半径。传统上,用切比雪夫多项式(Chebyshev polynomial) T k ( x ) T_k (x) Tk(x) 近似 K − 1 K-1 K−1 阶的截断展开为 Θ ( Λ ) ≈ ∑ k = 0 K − 1 θ k Λ k ( Λ ~ ) Θ(Λ)≈∑_{k=0}^{K-1}θ_k Λ_k (\tilde{Λ}) Θ(Λ)≈∑k=0K−1θkΛk(Λ~) 用重标 Λ ~ = 2 Λ / λ max − I n \tilde{Λ}=2Λ/λ_{\text{max}} -I_n Λ~=2Λ/λmax−In ( λ max λ_{\text{max}} λmax 表示 L L L 的最大特征值) [Hammond et al., 2011]。图卷积可以被重写为,
Θ ∗ G x = Θ ( L ) x ≈ ∑ k = 0 K − 1 θ k T k ( L ~ ) x , (3) Θ_{*_G}\ x=Θ(L)x≈∑_{k=0}^{K-1}θ_k T_k (\tilde{L})x , \tag{3} Θ∗G x=Θ(L)x≈k=0∑K−1θkTk(L~)x,(3)
where T k ( L ~ ) ∈ R n × n T_k (\tilde{L})∈\R^{n×n} Tk(L~)∈Rn×n is the Chebyshev polynomial of order k k k evaluated at the scaled Laplacian L ~ = 2 L / λ max − I n \tilde{L}=2L/λ_{\text{max}}-I_n L~=2L/λmax−In. By recursively computing K K K-localized convolutions through the polynomial approximation, the cost of Eq. (2) can be reduced to O ( K ∣ E ∣ ) O(K|E|) O(K∣E∣) as Eq. (3) shows [Defferrard et al., 2016].
其中 T k ( L ~ ) ∈ R n × n T_k (\tilde{L})∈\R^{n×n} Tk(L~)∈Rn×n 是 k k k 阶的切比雪夫多项式(Chebyshev polynomial),在标量拉普拉斯算子 L ~ = 2 L / λ max − I n \tilde{L}=2L/λ_{\text{max}}-I_n L~=2L/λmax−In 处取值。通过多项式逼近递归计算 K K K 阶局部卷积,Eq.(2)的代价可以降为 O ( K ∣ E ∣ ) O(K|E|) O(K∣E∣) ,如Eq.(3)所示 [Defferrard et al., 2016]。
1 s t \bf1^{st} 1st-order Approximation A layer-wise linear formulation can be defined by stacking multiple localized graph convolutional layers with the first-order approximation of graph Laplacian [Kipf and Welling, 2016]. Consequently, a deeper architecture can be constructed to recover spatial information in depth without being limited to the explicit parameterization given by the polynomials. Due to the scaling and normalization in neural networks, we can further assume that λ max ≈ 2 λ_\text{max}≈2 λmax≈2. Thus, the Eq. (3) can be simplified to,
1 \bf1 1 阶近似( 1 s t \bf1^{st} 1st-order Approximation) 用图拉普拉斯一阶近似叠加多个局部图卷积层可以定义分层线性公式 [Kipf and Welling, 2016]。因此,可以构建一个更深层次的体系结构,在不局限于多项式所给出的显式参数化的情况下对空间信息进行深度恢复。由于神经网络的扩展和归一化,我们可以进一步假设 λ max ≈ 2 λ_\text{max}≈2 λmax≈2。因此,式(3)可简化为:
Θ ∗ G x ≈ θ 0 x + θ 1 ( 2 λ max L − I n ) x ≈ θ 0 x + θ 1 ( D − 1 2 W D − 1 2 ) x , (4) \begin{aligned}Θ_{*_G}\ x&≈θ_0 x+θ_1 (\frac{2}{λ_\text{max}}L-I_n )x\\ &≈θ_0 x+θ_1 (D^{-\frac{1}{2}}WD^{-\frac{1}{2}})x, \tag{4}\end{aligned} Θ∗G x≈θ0x+θ1(λmax2L−In)x≈θ0x+θ1(D−21WD−21)x,(4)
where θ 0 θ_0 θ0, θ 1 θ_1 θ1 are two shared parameters of the kernel. In order to constrain parameters and stabilize numerical performances, θ 0 θ_0 θ0 and θ 1 θ_1 θ1 are replaced by a single parameter θ by letting θ = θ 0 = − θ 1 θ=θ_0=-θ_1 θ=θ0=−θ1; W W W and D D D are renormalized by W ~ = W + I n \tilde{W}=W+I_n W~=W+In and D ~ i i = ∑ j W ~ i j \tilde{D}_{ii}=∑_j\tilde{W}_{ij} D~ii=∑jW~ij separately. Then, the graph convolution can be alternatively expressed as,
其中 θ 0 θ_0 θ0 和 θ 1 θ_1 θ1 是核的两个共享参数。为了约束参数和稳定数值性能, θ 0 θ_0 θ0 和 θ 1 θ_1 θ1 用单一参数 θ θ θ 代替,使 θ = θ 0 = − θ 1 θ=θ_0=-θ_1 θ=θ0=−θ1; W W W 和 D D D 分别为 W ~ = W + I n \tilde{W}=W+I_n W~=W+In 和 D ~ i i = ∑ j W ~ i j \tilde{D}_{ii}=∑_j\tilde{W}_{ij} D~ii=∑jW~ij 。那么,图卷积可以交替表示为:
Θ ∗ G x = θ ( I n + D − 1 2 W D − 1 2 ) x = θ ( D ~ − 1 2 W ~ D ~ − 1 2 ) x . (5) \begin{aligned}Θ_{*_G}\ x&=θ(I_n+D^{-\frac{1}{2}}WD^{-\frac{1}{2}})x\\ &=θ(\tilde{D}^{-\frac{1}{2}}\tilde{W}\tilde{D}^{-\frac{1}{2}})x. \tag{5}\end{aligned} Θ∗G x=θ(In+D−21WD−21)x=θ(D~−21W~D~−21)x.(5)
Applying a stack of graph convolutions with the 1 s t 1^{st} 1st-order approximation vertically that achieves the similar effect as K K K-localized convolutions do horizontally, all of which exploit the information from the ( K − 1 ) (K-1) (K−1)-order neighborhood of central nodes. In this scenario, K K K is the number of successive filtering operations or convolutional layers in a model instead. Additionally, the layer-wise linear structure is parameter-economic and highly efficient for large-scale graphs, since the order of the approximation is limited to one.
在垂直方向上使用 1 1 1 阶近似的图卷积堆栈,可以获得与水平方向上 K K K 阶局部卷积类似的效果,所有这些都利用了中心节点 ( K − 1 ) (K-1) (K−1) 阶邻域的信息。在这种情况下, K K K 是一个模型中连续过滤操作或卷积层的数量。此外,分层线性结构对大规模图具有参数经济性和高效率,因为近似的阶数限制在 1 1 1 。
Generalization of Graph Convolutions The graph convolution operator “ ∗ G *_G ∗G” defined on X ∈ R n X∈\R^n X∈Rn can be extended to multi-dimensional tensors. For a signal with C i C_i Ci channels X ∈ R n × C i X∈\R^{n×C_i} X∈Rn×Ci , the graph convolution can be generalized by,
图卷积的概括 定义在 X ∈ R n X∈\R^n X∈Rn 上的图卷积算子 “ ∗ G *_G ∗G” 可以推广到多维张量。对于一个 C i C_i Ci 信道 X ∈ R n × C i X∈\R^{n×C_i} X∈Rn×Ci 的信号,其图卷积可以概括为:
y j = ∑ i = 1 C i Θ i , j ( L ) x i ∈ R n , 1 ≤ j ≤ C o (6) y_j=∑_{i=1}^{C_i}Θ_{i,j} (L)x_i∈\R^n,1≤j≤C_o \tag{6} yj=i=1∑CiΘi,j(L)xi∈Rn,1≤j≤Co(6)
with the C i × C o C_i×C_o Ci×Co vectors of Chebyshev coefficients Θ i , j ∈ R K Θ_{i,j}∈\R^K Θi,j∈RK ( C i C_i Ci, C o C_o Co are the size of input and output of the feature maps, respectively). The graph convolution for 2 2 2-D variables is denoted as “ Θ ∗ G X Θ_{*_G}\ X Θ∗G X” with Θ ∈ R K × C i × C o Θ∈\R^{K×C_i×C_o} Θ∈RK×Ci×Co . Specifically, the input of traffic prediction is composed of M M M frame of road graphs as Figure 1 shows. Each frame v t v_t vt can be regarded as a matrix whose column I I I is the C i C_i Ci-dimensional value of v t v_t vt at the I t h I^{th} Ith node in graph G t G_t Gt, as X ∈ R K × C i X∈\R^{K×C_i} X∈RK×Ci (in this case, C i = 1 C_i=1 Ci=1). For each time step t t t of M M M , the equal graph convolution operation with the same kernel Θ Θ Θ is imposed on X t ∈ R K × C i X_t∈\R^{K×C_i} Xt∈RK×Ci in parallel. Thus, the graph convolution can be further generalized in 3 3 3-D variables, noted as “ Θ ∗ G X Θ_{*_G}\ X Θ∗G X” with X ∈ R M × n × C i X∈\R^{M×n×C_i} X∈RM×n×Ci .
切比雪夫系数的 C i × C o C_i×C_o Ci×Co 向量 Θ i , j ∈ R K Θ_{i,j}∈\R^K Θi,j∈RK ( C i C_i Ci, C o C_o Co分别为特征映射的输入和输出的大小)。二维变量的图卷积记为 “ Θ ∗ G X Θ_{*_G}\ X Θ∗G X” 与 Θ ∈ R K × C i × C o Θ∈\R^{K×C_i×C_o} Θ∈RK×Ci×Co 。其中,交通预测的输入由道路图的 M M M 帧组成,如图1所示。每一帧 v t v_t vt 可以看成是一个矩阵,其第 i i i 列是图 G t G_t Gt 中第 i i i 个节点 v t v_t vt 的 C i C_i Ci 维度值,如 X ∈ R K × C i X∈\R^{K×C_i} X∈RK×Ci (本例中为 C i = 1 C_i=1 Ci=1)。对于 M M M 的每一个时间步长 t t t ,并行地对 X t ∈ R K × C i X_t∈\R^{K×C_i} Xt∈RK×Ci 进行具有相同核数 Θ Θ Θ 的等图卷积运算。因此,图卷积可以在三维变量中进一步推广,记为 “ Θ ∗ G X Θ_{*_G}\ X Θ∗G X”, X ∈ R M × n × C i X∈\R^{M×n×C_i} X∈RM×n×Ci 。
3.3 Gated CNNs for Extracting Temporal Features(门控CNN提取时间特征)
Although RNN-based models become widespread in time-series analysis, recurrent networks for traffic prediction still suffer from time-consuming iterations, complex gate mechanisms, and slow response to dynamic changes. On the contrary, CNNs have the superiority of fast training, simple structures, and no dependency constraints to previous steps. Inspired by [Gehring et al., 2017] , we employ entire convolutional structures on time axis to capture temporal dynamic behaviors of traffic flows. This specific design allows parallel and controllable training procedures through multi-layer convolutional structures formed as hierarchical representations.
尽管基于RNN的模型在时间序列分析中得到广泛应用,但用于流量预测的递归网络仍然存在迭代耗时、门控机制复杂、对动态变化响应缓慢等问题。相反,CNN具有训练速度快、结构简单、不依赖前几步的优势。受 [Gehring et al., 2017] 启发,我们采用时间轴上的全卷积结构来捕捉交通流的时间动态行为。这种特殊的设计允许通过形成分层表示的多层卷积结构并行和可控的训练程序。
As Figure 2 (right) shows, the temporal convolutional layer contains a 1 1 1-D causal convolution with a width- K t K_t Kt kernel followed by gated linear units (GLU) as a non-linearity. For each node in graph G G G, the temporal convolution explores K t K_t Kt neighbors of input elements without padding which leading to shorten the length of sequences by K t − 1 K_t-1 Kt−1 each time. Thus, input of temporal convolution for each node can be regarded as a length- M M M sequence with C i C_i Ci channels as Y ∈ R M × C i Y∈\R^{M×C_i} Y∈RM×Ci . The convolution kernel Γ ∈ R K t × C i × 2 C o Γ∈\R^{K_t×C_i×2C_o} Γ∈RKt×Ci×2Co is designed to map the input Y Y Y to a single output element [ P Q ] ∈ R ( M − K t + 1 ) × ( 2 C o ) [P\ Q] ∈\R^{(M-K_t+1)×(2C_o)} [P Q]∈R(M−Kt+1)×(2Co) ( P P P , Q Q Q is split in half with the same size of channels). As a result, the temporal gated convolution can be defined as,
如图2 (右) 所示,时间卷积层包含一个一维因果卷积,其宽度为 K t K_t Kt 的核,后面是非线性的门控线性单元(GLU)。对于图 G G G 中的每个节点,时间卷积对输入元素的 K t K_t Kt 近邻进行不填充的搜索,使得序列的长度每次缩短 K t − 1 K_t-1 Kt−1 。因此,每个节点的时间卷积输入可以看作是一个长度为 m m m 的序列, 通道 C i C_i Ci 为 Y ∈ R M × C i Y∈\R^{M×C_i} Y∈RM×Ci 。卷积核 Γ ∈ R K t × C i × 2 C o Γ∈\R^{K_t×C_i×2C_o} Γ∈RKt×Ci×2Co 设计用于将输入 Y Y Y 映射到单个输出元素 [ P Q ] ∈ R ( M − K t + 1 ) × ( 2 C o ) [P\ Q] ∈\R^{(M-K_t+1)×(2C_o)} [P Q]∈R(M−Kt+1)×(2Co) ( P P P , Q Q Q 被一分为二,通道大小相同)。因此,时间门控卷积可以定义为:
Γ ∗ γ Y = P ⊙ σ ( Q ) ∈ R ( M − K t + 1 ) × ( 2 C o ) , (7) Γ_{*_γ}\ Y=P\odotσ(Q)∈\R^{(M-K_t+1)×(2C_o)}, \tag{7} Γ∗γ Y=P⊙σ(Q)∈R(M−Kt+1)×(2Co),(7)
where P P P , Q Q Q are input of gates in GLU respectively; ⊙ \odot ⊙ denotes the element-wise Hadamard product. The sigmoid gate σ ( Q ) σ(Q) σ(Q) controls which input P P P of the current states are relevant for discovering compositional structure and dynamic variances in time series. The non-linearity gates contribute to the exploiting of the full input filed through stacked temporal layers as well. Furthermore, residual connections are implemented among stacked temporal convolutional layers. Similarly, the temporal convolution can also be generalized to 3 3 3-D variables by employing the same convolution kernel Γ Γ Γ to every node Y i ∈ R M × C i Y_i∈\R^{M×C_i} Yi∈RM×Ci (e.g. sensor stations) in G G G equally, noted as “ Γ ∗ γ Y Γ_{*_γ}\ Y Γ∗γ Y” with Y ∈ R M × n × C i Y∈\R^{M×n×C_i} Y∈RM×n×Ci .
式中, P P P , Q Q Q 分别为GLU中的门的输入; ⊙ \odot ⊙ 表示两个矩阵对应位置进行乘积。激活门 σ ( Q ) σ(Q) σ(Q) 控制输入 P P P 的状态与发现时间序列中的结构和动态方差有关。非线性门还有助于通过叠加的时间层利用全输入场。此外,在堆叠的时间卷积层之间实现剩余连接。同样,时间卷积也可以推广到三维变量,将 G G G 中的每个节点 Y i ∈ R M × C i Y_i∈\R^{M×C_i} Yi∈RM×Ci (如传感器站)使用相同的卷积核 Γ Γ Γ ,记为 “ Γ ∗ γ Y Γ_{*_γ}\ Y Γ∗γ Y” ,其中 Y ∈ R M × n × C i Y∈\R^{M×n×C_i} Y∈RM×n×Ci 。
3.4 Spatio-temporal Convolutional Block(时空卷积模块)
In order to fuse features from both spatial and temporal domains, the spatio-temporal convolutional block (ST-Conv block) is constructed to jointly process graph-structured time series. The block itself can be stacked or extended based on the scale and complexity of particular cases.
为了融合时空两方面的特征,构造了时空卷积模块 (ST-Conv block) 来联合处理图结构时间序列。模块本身可以根据特定情况的规模和复杂度进行堆叠或扩展。
As illustrated in Figure 2 (mid), the spatial layer in the middle is to bridge two temporal layers which can achieve fast spatial-state propagation from graph convolution through temporal convolutions. The “sandwich” structure also helps the network sufficiently apply bottleneck strategy to achieve scale compression and feature squeezing by downscaling and upscaling of channels C C C through the graph convolutional layer. Moreover, layer normalization is utilized within every ST-Conv block to prevent overfitting.
如图2 (中间) 所示,中间的空间层是连接两个时间层,可以通过时间卷积从图卷积实现快速的空间状态传播。“三明治”结构也有助于网络充分运用瓶颈策略,通过图卷积层对通道 C C C 进行降尺度和升尺度,实现尺度压缩和特征压缩。此外,在ST-Conv的每个块内都进行了层归一化,以防止过拟合。
The input and output of ST-Conv blocks are all 3 3 3-D tensors. For the input v l ∈ R M × n × C l v^l∈\R^{M×n×C^l} vl∈RM×n×Cl of block l l l, the output v l + 1 ∈ R ( M − 2 ( K t − 1 ) ) × n × C l + 1 v^{l+1}∈\R^{(M-2(K_t-1))×n×C^{l+1}} vl+1∈R(M−2(Kt−1))×n×Cl+1 is computed by,
ST-Conv模块的输入和输出都是三维张量。对于模块 l l l 的输入 v l ∈ R M × n × C l v^l∈\R^{M×n×C^l} vl∈RM×n×Cl ,输出 v l + 1 ∈ R ( M − 2 ( K t − 1 ) ) × n × C l + 1 v^{l+1}∈\R^{(M-2(K_t-1))×n×C^{l+1}} vl+1∈R(M−2(Kt−1))×n×Cl+1 的计算公式为:
v l + 1 = Γ 1 l ∗ γ ReLU ( Θ l ∗ G ( Γ 0 l ∗ γ v l ) ) , (8) v^{l+1}=Γ_1^l{*_γ}\ \text{ReLU}\big(Θ^l{*_G}(Γ_0^l{*_γ}v^l)\big), \tag{8} vl+1=Γ1l∗γ ReLU(Θl∗G(Γ0l∗γvl)),(8)
where Γ 0 l Γ_0^l Γ0l , Γ 1 l Γ_1^l Γ1l are the upper and lower temporal kernel within block l l l, respectively; Θ l Θ^l Θl is the spectral kernel of graph convolution; ReLU ( ⋅ ) \text{ReLU}(\cdot) ReLU(⋅) denotes the rectified linear units function. After stacking two ST-Conv blocks, we attach an extra temporal convolution layer with a fully-connected layer as the output layer in the end (See the left of Figure 2). The temporal convolution layer maps outputs of the last ST-Conv block to a single-step prediction. Then, we can obtain a final output Z ∈ R n × c Z∈\R^{n×c} Z∈Rn×c from the model and calculate the speed prediction for n nodes by applying a linear transformation across c c c-channels as v ^ = Z w + b \hat{v}=Zw+b v^=Zw+b , where w ∈ R c w∈\R^c w∈Rc is a weight vector and b b b is a bias. We use L2 loss to measure the performance of our model. Thus, the loss function of STGCN for traffic prediction can be written as,
其中 Γ 0 l Γ_0^l Γ0l , Γ 1 l Γ_1^l Γ1l 分别是块 l l l 内的上、下时间核; Θ l Θ^l Θl 是图卷积的核; ReLU ( ⋅ ) \text{ReLU}(\cdot) ReLU(⋅) 为修正后的线性单位函数,结果如下:在叠加两个ST-Conv模块后,我们在最后附加一个全连通的时间卷积层作为输出层 (见图2左侧) 。时间卷积层将最后一个ST-Conv模块的输出映射到一个单步预测。然后,我们可以从模型中得到最终输出 Z ∈ R n × c Z∈\R^{n×c} Z∈Rn×c ,并通过 c c c 通道的线性变换 v ^ = Z w + b \hat{v}=Zw+b v^=Zw+b 计算 n n n 个节点的速度预测,其中 w ∈ R c w∈\R^c w∈Rc 是权重向量, b b b 是偏差。我们使用 L2 损失来衡量我们的模型的性能。则STGCN流量预测的损失函数为:
L ( v ^ ; W θ ) = ∑ t ∥ v ^ ( v t − M + 1 , … , v t , W θ ) ∥ 2 , (9) L(\hat{v}; W_θ )=∑_t\Vert\hat{v}(v_{t-M+1},…,v_t,W_θ)\Vert^2 , \tag{9} L(v^;Wθ)=t∑∥v^(vt−M+1,…,vt,Wθ)∥2,(9)
where W θ W_θ Wθ are all trainable parameters in the model; v t + 1 v_{t+1} vt+1 is the ground truth and v ^ ( ⋅ ) \hat{v}(\cdot) v^(⋅) denotes the model’s prediction.
其中 W θ W_θ Wθ 为模型中所有可训练参数; v t + 1 v_{t+1} vt+1 为真实值, v ^ ( ⋅ ) \hat{v}(\cdot) v^(⋅) 为模型预测结果。
We now summarize the main characteristics of our model STGCN in the following,
下面我们将我们的模型STGCN的主要特点总结如下:
- STGCN is a universal framework to process structured time series. It is not only able to tackle traffic network modeling and prediction issues but also to be applied to more general spatio-temporal sequence learning tasks.
STGCN是处理结构化时间序列的通用框架。它不仅能够解决交通网络建模和预测问题,而且还可以应用于更一般的时空序列学习任务。 - The spatio-temporal block combines graph convolutions and gated temporal convolutions, which can extract the most useful spatial features and capture the most essen- tial temporal features coherently.
该时空块结合了图卷积和门控时间卷积,可以提取最有用的空间特征,同时相干地捕捉最基本的时间特征。 - The model is entirely composed of convolutional struc- tures and therefore achieves parallelization over input with fewer parameters and faster training speed. More importantly, this economic architecture allows the model to handle large-scale networks with more efficiency.
该模型完全由卷积结构组成,因此可以以较少的参数和较快的训练速度实现并行化输入。更重要的是,这种经济架构允许模型更有效地处理大规模网络。
参考文献
[Hammond et al., 2011] David K Hammond, Pierre Van-dergheynst, and Re´mi Gribonval. Wavelets on graphs via spectral graph theory. Applied and Computational Harmonic Analysis, 30(2):129–150, 2011.
[Defferrard et al., 2016] Michae¨l Defferrard, Xavier Bresson, and Pierre Vandergheynst. Convolutional neural networks on graphs with fast localized spectral filtering. In NIPS, pages 3844–3852, 2016.
[Kipf and Welling, 2016] Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907, 2016.
[Gehring et al., 2017] Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, and Yann N Dauphin. Convolutional sequence to sequence learning. arXiv preprint arXiv:1705.03122, 2017.