Spatio-Temporal Graph Transformer Networks for Pedestrian Trajectory Prediction 代码梳理
import copy #导入拷贝库
import numpy as np #导入数值计算库,以后调用采用np缩写
import torch #导入torch库包含一些常用的数据类型
import torch.nn as nn #导入torch中的网络层以后调用采用nn缩写,例如nn.liner()
import torch.nn.functional as F #导入torch中的一些函数,例如常用的激活函数
from .multi_attention_forward import multi_head_attention_forward
#.表示在当前目录下multi_attention_forward.py,导入multi_head_attention_forward函数
def get_noise(shape, noise_type):#定义一个函数get_noise,输入参数为shape,noise_type,shape-表示数据结构,比如2行2列(2,2) noise_type字符串型
if noise_type == "gaussian":#如果noise_type为高斯
return torch.randn(shape).cuda()#生成标准正态分布,数据结构为shape-(x,y),放入cuda中,返回
elif noise_type == "uniform":#如果为均匀分布
return torch.rand(*shape).sub_(0.5).mul_(2.0).cuda()#生成均匀分布(0,1),然后-0.5得到(-0.5,0.5),再乘以2得到(-1,1)的均匀分布,数据结构为shape-(x,y),放入到cuda中,返回
raise ValueError('Unrecognized noise type "%s"' % noise_type)#如果nosie_type不是前两种情况,报错
def get_subsequent_mask(seq):#定义一个函数get_subsequent_mask,输入参数为seq,其中seq第一维度表示数据集场景,第二维表示障碍物编号
''' For masking out the subsequent info. '''
sz_b, len_s = seq.size()#得到seq数据结构比如(3,6)
subsequent_mask = (1 - torch.triu(
torch.ones((1, len_s, len_s), device=seq.device), diagonal=1)).bool() #得到下三角矩阵,并放入到seq.device中,数据变为bool型即{True,False}.过程见下↓
return subsequent_mask#返回
( 1 − t o r c h . t r i u ( t o r c h . o n e s ( ( 1 , l e n s , l e n s ) , d e v i c e = s e q . d e v i c e ) , d i a g o n a l = 1 ) ) . b o o l ( ) 数据变化 (1 - torch.triu( torch.ones((1, len_s, len_s), device=seq.device), diagonal=1)).bool() 数据变化 (1−torch.triu(torch.ones((1,lens,lens),device=seq.device),diagonal=1)).bool()数据变化
[ 1 1 ⋯ 1 1 1 ⋯ 1 ⋮ ⋮ ⋱ ⋮ 1 1 ⋯ 1 ] \begin{bmatrix} {1}&{1}&{\cdots}&{1}\\ {1}&{1}&{\cdots}&{1}\\ {\vdots}&{\vdots}&{\ddots}&{\vdots}\\ {1}&{1}&{\cdots}&{1}\\ \end{bmatrix} 11⋮111⋮1⋯⋯⋱⋯11⋮1 [ 1 1 ⋯ 1 0 1 ⋯ 1 ⋮ ⋮ ⋱ ⋮ 0 0 ⋯ 1 ] \begin{bmatrix} {1}&{1}&{\cdots}&{1}\\ {0}&{1}&{\cdots}&{1}\\ {\vdots}&{\vdots}&{\ddots}&{\vdots}\\ {0}&{0}&{\cdots}&{1}\\ \end{bmatrix} 10⋮011⋮0⋯⋯⋱⋯11⋮1 [ 0 1 ⋯ 1 0 0 ⋯ 1 ⋮ ⋮ ⋱ ⋮ 0 0 ⋯ 0 ] \begin{bmatrix} {0}&{1}&{\cdots}&{1}\\ {0}&{0}&{\cdots}&{1}\\ {\vdots}&{\vdots}&{\ddots}&{\vdots}\\ {0}&{0}&{\cdots}&{0}\\ \end{bmatrix} 00⋮010⋮0⋯⋯⋱⋯11⋮0 [ 1 − 0 1 − 1 ⋯ 1 − 1 1 − 0 1 − 0 ⋯ 1 − 1 ⋮ ⋮ ⋱ ⋮ 1 − 0 1 − 0 ⋯ 1 − 0 ] \begin{bmatrix} {1-0}&{1-1}&{\cdots}&{1-1}\\ {1-0}&{1-0}&{\cdots}&{1-1}\\ {\vdots}&{\vdots}&{\ddots}&{\vdots}\\ {1-0}&{1-0}&{\cdots}&{1-0}\\ \end{bmatrix} 1−01−0⋮1−01−11−0⋮1−0⋯⋯⋱⋯1−11−1⋮1−0 [ 1 0 ⋯ 0 1 1 ⋯ 0 ⋮ ⋮ ⋱ ⋮ 1 1 ⋯ 1 ] \begin{bmatrix} {1}&{0}&{\cdots}&{0}\\ {1}&{1}&{\cdots}&{0}\\ {\vdots}&{\vdots}&{\ddots}&{\vdots}\\ {1}&{1}&{\cdots}&{1}\\ \end{bmatrix} 11⋮101⋮1⋯⋯⋱⋯00⋮1 [ T r u e F a l s e ⋯ F a l s e T r u e T r u e ⋯ F a l s e ⋮ ⋮ ⋱ ⋮ T r u e T r u e ⋯ T r u e ] \begin{bmatrix} {True}&{False}&{\cdots}&{False}\\ {True}&{True}&{\cdots}&{False}\\ {\vdots}&{\vdots}&{\ddots}&{\vdots}\\ {True}&{True}&{\cdots}&{True}\\ \end{bmatrix} TrueTrue⋮TrueFalseTrue⋮True⋯⋯⋱⋯FalseFalse⋮True
def _get_activation_fn(activation): #定义得到激活函数
if activation == "relu":#如果采用relu
return F.relu #返回F.relu即import torch.nn.functional as F 中的torch.nn.functional.relu
elif activation == "gelu":#如果采用gelu
return F.gelu#返回F.gelu即import torch.nn.functional as F 中的torch.nn.functional.gelu
else:
raise RuntimeError("activation should be relu/gelu, not %s." % activation)#如果不是前面的两种情况返回报错activation should be relu/gelu, not “activation”。
def _get_clones(module, N):#定义得到克隆函数
return nn.ModuleList([copy.deepcopy(module) for i in range(N)]) #返回n个module模型
class MultiheadAttention(nn.Module):#定义一个类对象MultiheadAttention,继承nn.Module
r"""Allows the model to jointly attend to information
from different representation subspaces.
See reference: Attention Is All You Need
.. math::
\text{MultiHead}(Q, K, V) = \text{Concat}(head_1,\dots,head_h)W^O
\text{where} head_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V)
Args:
embed_dim: total dimension of the model.
num_heads: parallel attention heads.
dropout: a Dropout layer on attn_output_weights. Default: 0.0.
bias: add bias as module parameter. Default: True.
add_bias_kv: add bias to the key and value sequences at dim=0.
add_zero_attn: add a new batch of zeros to the key and
value sequences at dim=1.
kdim: total number of features in key. Default: None.
vdim: total number of features in key. Default: None.
Note: if kdim and vdim are None, they will be set to embed_dim such that
query, key, and value have the same number of features.
Examples::
>>> multihead_attn = nn.MultiheadAttention(embed_dim, num_heads)
>>> attn_output, attn_output_weights = multihead_attn(query, key, value)
"""
__constants__ = ['q_proj_weight', 'k_proj_weight', 'v_proj_weight', 'in_proj_weight']
def __init__(self, embed_dim, num_heads, dropout=0., bias=True, add_bias_kv=False, add_zero_attn=False, kdim=None,
vdim=None):
super(MultiheadAttention, self).__init__() #初始化先找到 MultiheadAttention的父类nn.Module,并用nn.Module的初始化方法初始化子类MultiheadAttention
self.embed_dim = embed_dim #transfomer经过编码后的输入数据维度
self.kdim = kdim if kdim is not None else embed_dim #k的维度如果输入参数有则赋值,没有计为embed_dim
self.vdim = vdim if vdim is not None else embed_dim #v的维度如果输入参数有则赋值,没有计为embed_dim
self._qkv_same_embed_dim = self.kdim == embed_dim and self.vdim == embed_dim #如果k与v维数相同则赋值为True
self.num_heads = num_heads #多头个数
self.dropout = dropout
#定义一个dropout层为了出现过拟合,在训练时,按照伯努利分布的样本以概率P将输入张量的某些元素随机归零,输入结果放缩为 1/(1-p)
import torch.nn as nn
input = torch.ones(5,5)
m = nn.Dropout(p=0.2)
output = m(input)
print(output)
tensor([[1.2500, 1.2500, 0.0000,1.2500, 0.0000],
[1.2500, 1.2500, 1.2500, 0.0000, 1.2500],
[1.2500, 1.2500, 1.2500, 1.2500, 0.0000],
[1.2500, 1.2500, 1.2500, 1.2500, 0.0000],
[1.2500, 1.2500, 1.2500, 1.2500, 1.2500]])
1-0.2=0.8 1/0.8=1.25符合
self.head_dim = embed_dim // num_heads #整数除,计算每一个head的维数比如8//3=2
assert self.head_dim * num_heads == self.embed_dim, "embed_dim must be divisible by num_heads" #判断是否整除比如上面的2 * 3 !=8 所以输出错误
if self._qkv_same_embed_dim is False: #如果k v维度不一样则执行,对q k v 权重分别初始化,不注册in_proj_weight
self.q_proj_weight = nn.Parameter(torch.Tensor(embed_dim, embed_dim))
self.k_proj_weight = nn.Parameter(torch.Tensor(embed_dim, self.kdim))
self.v_proj_weight = nn.Parameter(torch.Tensor(embed_dim, self.vdim))
self.register_parameter('in_proj_weight', None)
else: #如果k v维度一样则执行,对q k v 权重一起初始化,不注册q k v_proj_weight
self.in_proj_weight = nn.Parameter(torch.empty(3 * embed_dim, embed_dim))
self.register_parameter('q_proj_weight', None)
self.register_parameter('k_proj_weight', None)
self.register_parameter('v_proj_weight', None)
if bias:#如果存在偏执参数,则执行
self.in_proj_bias = nn.Parameter(torch.empty(3 * embed_dim))
else: #否则不注册in_proj_bias
self.register_parameter('in_proj_bias', None)
self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias) #输出为全连接网络,网络输入数据的维度为embed_dim,输出数据的维度为embed_dim,偏执为bias
if add_bias_kv:#如果 k v 存在偏执则执行
self.bias_k = nn.Parameter(torch.empty(1, 1, embed_dim))
self.bias_v = nn.Parameter(torch.empty(1, 1, embed_dim))
else: #否则设置为none
self.bias_k = self.bias_v = None
self.add_zero_attn = add_zero_attn #对k v按照列是否添加一些0序列
self._reset_parameters()#参数进行重新设置,为什么重新设置?
如果初始化值很小,那么随着层数的传递,方差就会趋于0,此时输入值 也变得越来越小,在sigmoid上就是在0附近,接近于线性,失去了非线性
如果初始值很大,那么随着层数的传递,方差会迅速增加,此时输入值变得很大,而sigmoid在大输入值写倒数趋近于0,反向传播时会遇到梯度消失的问题
def _reset_parameters(self):# 上面参数重新设置的调用函数采用了 nn.init.xavier_uniform_对参数重新设置[参考文献](https://blog.csdn.net/weixin_44225182/article/details/126655294)
if self._qkv_same_embed_dim: #如果 k v 维度相同,统一重新设置
nn.init.xavier_uniform_(self.in_proj_weight)
else: #否则分别设置
nn.init.xavier_uniform_(self.q_proj_weight)
nn.init.xavier_uniform_(self.k_proj_weight)
nn.init.xavier_uniform_(self.v_proj_weight)
if self.in_proj_bias is not None:#有则初始化填充为常数0
nn.init.constant_(self.in_proj_bias, 0.)
nn.init.constant_(self.out_proj.bias, 0.)
if self.bias_k is not None:有则重新设置
nn.init.xavier_normal_(self.bias_k)
if self.bias_v is not None:
nn.init.xavier_normal_(self.bias_v)
def __setstate__(self, state):#反序列化时调用,[序列化与反序列化](https://blog.csdn.net/jiang_huixin/article/details/109674221)[pickle模块](https://blog.csdn.net/chunmi6974/article/details/78392230)
# Support loading old MultiheadAttention checkpoints generated by v1.1.0
if '_qkv_same_embed_dim' not in state:#如果_qkv_same_embed_dim不在state字典中,添加到字典中并记为True
state['_qkv_same_embed_dim'] = True
super(MultiheadAttention, self).__setstate__(state)
def forward(self, query, key, value, key_padding_mask=None,
need_weights=True, attn_mask=None): #模型的各网络连接方式
# type: (Tensor, Tensor, Tensor, Optional[Tensor], bool, Optional[Tensor]) -> Tuple[Tensor, Optional[Tensor]]
r"""
Args:
query, key, value: map a query and a set of key-value pairs to an output.
See "Attention Is All You Need" for more details.
key_padding_mask: if provided, specified padding elements in the key will
be ignored by the attention. This is an binary mask. When the value is True,
the corresponding value on the attention layer will be filled with -inf.
need_weights: output attn_output_weights.
attn_mask: mask that prevents attention to certain positions. This is an additive mask
(i.e. the values will be added to the attention layer).
Shape:
- Inputs:
- query: :math:`(L, N, E)` where L is the target sequence length, N is the batch size, E is
the embedding dimension.
- key: :math:`(S, N, E)`, where S is the source sequence length, N is the batch size, E is
the embedding dimension.
- value: :math:`(S, N, E)` where S is the source sequence length, N is the batch size, E is
the embedding dimension.
- key_padding_mask: :math:`(N, S)`, ByteTensor, where N is the batch size, S is the source sequence length.
- attn_mask: :math:`(L, S)` where L is the target sequence length, S is the source sequence length.
- Outputs:
- attn_output: :math:`(L, N, E)` where L is the target sequence length, N is the batch size,
E is the embedding dimension.
- attn_output_weights: :math:`(N, L, S)` where N is the batch size,
L is the target sequence length, S is the source sequence length.
"""
if not self._qkv_same_embed_dim:#如果k v 维度不相等,则单独传入参数(对比后面三项)
return multi_head_attention_forward(
query, key, value, self.embed_dim, self.num_heads,
self.in_proj_weight, self.in_proj_bias,
self.bias_k, self.bias_v, self.add_zero_attn,
self.dropout, self.out_proj.weight, self.out_proj.bias,
training=self.training,
key_padding_mask=key_padding_mask, need_weights=need_weights,
attn_mask=attn_mask, use_separate_proj_weight=True,
q_proj_weight=self.q_proj_weight, k_proj_weight=self.k_proj_weight,
v_proj_weight=self.v_proj_weight)
else:#如果k v 维度相等,则一起传入参数(对比后面三项)
return multi_head_attention_forward(
query, key, value, self.embed_dim, self.num_heads,
self.in_proj_weight, self.in_proj_bias,
self.bias_k, self.bias_v, self.add_zero_attn,
self.dropout, self.out_proj.weight, self.out_proj.bias,
training=self.training,
key_padding_mask=key_padding_mask, need_weights=need_weights,
attn_mask=attn_mask)
class TransformerEncoderLayer(nn.Module):#定义Transfomer的EncoderLayer层,并继承nn.Moudle
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0, activation="relu"): #实例化时的初始化参数
super(TransformerEncoderLayer, self).__init__()#继承父类并实例化
self.self_attn = MultiheadAttention(d_model, nhead, dropout=dropout)#注意力机制层的输出
# Implementation of Feedforward model #前馈神经网络层
self.linear1 = nn.Linear(d_model, dim_feedforward)#前馈神经网络,输入层,输入向量维度为d_model,输出向量维度为dim_feedforward2048
self.dropout = nn.Dropout(dropout)#建立一层Dropout层,用于训练时防止过拟合。
self.linear2 = nn.Linear(dim_feedforward, d_model)#前馈神经网络,输出层,输入向量维度为dim_feedforward2048,输出向量维度为d_model
self.norm1 = nn.LayerNorm(d_model)#建立一层Layer Normalization
self.norm2 = nn.LayerNorm(d_model)#建立一层Layer Normalization
self.dropout1 = nn.Dropout(dropout)#建立一层Dropout
self.dropout2 = nn.Dropout(dropout)#建立一层Dropout
self.activation = _get_activation_fn(activation)#建立一个激活函数
def forward(self, src, src_mask=None, src_key_padding_mask=None):#定义连接方式
r"""Pass the input through the encoder layer.
Args:
src: the sequnce to the encoder layer (required).
src_mask: the mask for the src sequence (optional).
src_key_padding_mask: the mask for the src keys per batch (optional).
Shape:
see the docs in Transformer class.
"""
src2, attn = self.self_attn(src, src, src, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask) #多头注意力机制输入与输出
src = src + self.dropout1(src2) #引入dropout防止训练过拟合
src = self.norm1(src)#做一次Layer Normalization
if hasattr(self, "activation"):#如果定义了激活函数则执行
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
else: # for backward compatibility #否则调用relu
src2 = self.linear2(self.dropout(F.relu(self.linear1(src))))
src = src + self.dropout2(src2)#引入dropout防止训练过拟合
src = self.norm2(src)#做一次Layer Normalization
return src, attn#返回
class TransformerEncoder(nn.Module):#定义Transfomer Encoder
r"""TransformerEncoder is a stack of N encoder layers ##Transfomer Encoder由N个Transfomer Encoder layers组成
Args:
encoder_layer: an instance of the TransformerEncoderLayer() class (required).
num_layers: the number of sub-encoder-layers in the encoder (required).
norm: the layer normalization component (optional).
Examples::
>>> encoder_layer = nn.TransformerEncoderLayer(d_model=512, nhead=8)
>>> transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers=6)
>>> src = torch.rand(10, 32, 512)
>>> out = transformer_encoder(src)
"""
def __init__(self, encoder_layer, num_layers, norm=None):#初始化函数
super(TransformerEncoder, self).__init__()#继承父类nn.Moudle属性,并初始化
self.layers = _get_clones(encoder_layer, num_layers)#复制N个Transformer enconder layer
self.num_layers = num_layers #enconder 中 enconder layer的个数
self.norm = norm #是否包含layer normalization模块
def forward(self, src, mask=None, src_key_padding_mask=None):#定义模型之间的连接方式
r"""Pass the input through the encoder layers in turn.
Args:
src: the sequnce to the encoder (required).
mask: the mask for the src sequence (optional).
src_key_padding_mask: the mask for the src keys per batch (optional).
Shape:
see the docs in Transformer class.
"""
output = src#将输入赋值给输出
atts = [] #定义一个空数组,用于记录每一层enconder输出
for i in range(self.num_layers):
output, attn = self.layers[i](output, src_mask=mask,
src_key_padding_mask=src_key_padding_mask)#将前一级的encoder layer输出放入到当前的 enconder layer中,循环得到最后Enconder层的输出
atts.append(attn) #保存每一层的输出
if self.norm:#如果含有norm模块则执行
output = self.norm(output)
return output#返回
class TransformerModel(nn.Module):#定义Transfomer的模型
def __init__(self, ninp, nhead, nhid, nlayers, dropout=0.5):#模型初始化语句
super(TransformerModel, self).__init__()#继承父类,并初始化
self.model_type = 'Transformer'#模型的类型为Transfomer
self.src_mask = None #mask初始化为none
encoder_layers = TransformerEncoderLayer(ninp, nhead, nhid, dropout) #定义enconder层
self.transformer_encoder = TransformerEncoder(encoder_layers, nlayers)#定义enconder
self.ninp = ninp #输入向量的维度
def forward(self, src, mask):#定义模型的连接方式
n_mask = mask + torch.eye(mask.shape[0], mask.shape[0]).cuda()#mask+对角线矩阵
n_mask = n_mask.float().masked_fill(n_mask == 0., float(-1e20)).masked_fill(n_mask == 1., float(0.0))#矩阵元素为0赋值负小值,矩阵元素为1赋值0
output = self.transformer_encoder(src, mask=n_mask)#输出enconder层
return output#返回
torch.eye(6,6).cuda()
tensor([[1., 0., 0., 0., 0., 0.],
[0., 1., 0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0.],
[0., 0., 0., 1., 0., 0.],
[0., 0., 0., 0., 1., 0.],
[0., 0., 0., 0., 0., 1.]], device=‘cuda:0’)
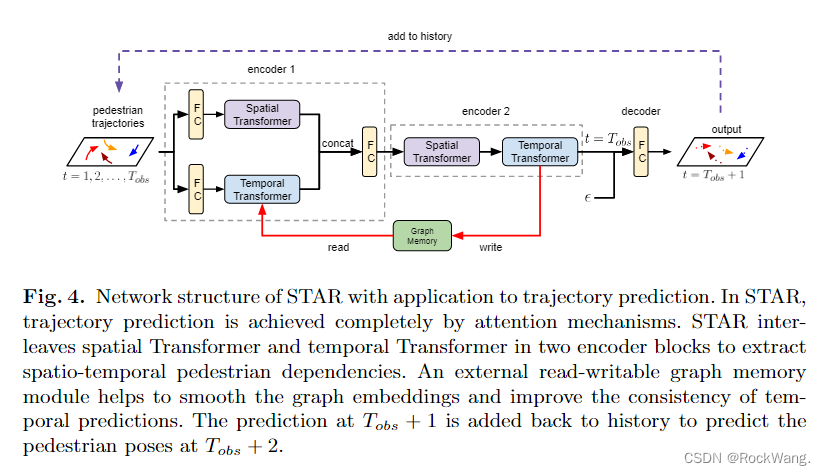
class STAR(torch.nn.Module):#定义STAR模型
def __init__(self, args, dropout_prob=0):#初始化
super(STAR, self).__init__()#继承父类nn.Moudle并初始化
# set parameters for network architecture
self.embedding_size = [32]#编码后的向量维度
self.output_size = 2#最终输出的向量维度(x,y)两维度
self.dropout_prob = dropout_prob#dropout层
self.args = args#参数
self.temporal_encoder_layer = TransformerEncoderLayer(d_model=32, nhead=8) #时间Transformer enconder建立输入为32维,8个head
emsize = 32 # embedding dimension
nhid = 2048 # the dimension of the feedforward network model in TransformerEncoder
nlayers = 2 # the number of nn.TransformerEncoderLayer in nn.TransformerEncoder
nhead = 8 # the number of heads in the multihead-attention models
dropout = 0.1 # the dropout value
self.spatial_encoder_1 = TransformerModel(emsize, nhead, nhid, nlayers, dropout) #定义空间Transfomer 1 其中enconder layer为2层
self.spatial_encoder_2 = TransformerModel(emsize, nhead, nhid, nlayers, dropout)#定义空间Transfomer 2 其中enconder layer为2层
self.temporal_encoder_1 = TransformerEncoder(self.temporal_encoder_layer, 1)#定义时间Transfomer 1 其中enconder layer为1层
self.temporal_encoder_2 = TransformerEncoder(self.temporal_encoder_layer, 1)#定义时间Transfomer 2 其中enconder layer为1层
# Linear layer to map input to embedding
self.input_embedding_layer_temporal = nn.Linear(2, 32)
self.input_embedding_layer_spatial = nn.Linear(2, 32) #编码嵌入层采用2-32编码网络
# Linear layer to output and fusion
self.output_layer = nn.Linear(48, 2)#输出层48-2
self.fusion_layer = nn.Linear(64, 32)#融合层64-32
# ReLU and dropout init
self.relu = nn.ReLU()#激活函数
self.dropout_in = nn.Dropout(self.dropout_prob)#两个dropout层
self.dropout_in2 = nn.Dropout(self.dropout_prob)
def get_st_ed(self, batch_num):#得到累加后的不同场景的起始索引跟终止索引
"""
:param batch_num: contains number of pedestrians in different scenes for a batch
:type batch_num: list
:return: st_ed: list of tuple contains start index and end index of pedestrians in different scenes
:rtype: list
"""
cumsum = torch.cumsum(batch_num, dim=0)#对batch_num按行进行累加
st_ed = []#定义一个空白list,用于记录
for idx in range(1, cumsum.shape[0]):
st_ed.append((int(cumsum[idx - 1]), int(cumsum[idx])))#提取累加后的行人编号区间
st_ed.insert(0, (0, int(cumsum[0])))#起始位置插入(0,cumsum[0])
return st_ed#返回
def get_node_index(self, seq_list):
"""
:param seq_list: mask indicates whether pedestrain exists
:type seq_list: numpy array [F, N], F: number of frames. N: Number of pedestrians (a mask to indicate whether
the pedestrian exists)
:return: All the pedestrians who exist from the beginning to current frame
:rtype: numpy array
"""
for idx, framenum in enumerate(seq_list):#将seq_list变为枚举类型
if idx == 0:#索引为0时,framenum中大于0为True,小于0为False
node_indices = framenum > 0
else:
node_indices *= (framenum > 0)#索引不为0时,node_indices*framenum,其中framenum中大于0为True,小于0为False
return node_indices#返回
def update_batch_pednum(self, batch_pednum, ped_list):
"""
:param batch_pednum: batch_num: contains number of pedestrians in different scenes for a batch
:type list
:param ped_list: mask indicates whether the pedestrian exists through the time window to current frame
:type tensor
:return: batch_pednum: contains number of pedestrians in different scenes for a batch after removing pedestrian who disappeared
:rtype: list
"""
updated_batch_pednum_ = copy.deepcopy(batch_pednum).cpu().numpy() #复制一份batch_pednum到CPU
updated_batch_pednum = copy.deepcopy(batch_pednum)#复制一份
cumsum = np.cumsum(updated_batch_pednum_)#累加
new_ped = copy.deepcopy(ped_list).cpu().numpy()#复制一份ped_list到CPU
for idx, num in enumerate(cumsum):#变为枚举
num = int(num)#强制转换为int类型
if idx == 0:
updated_batch_pednum[idx] = len(np.where(new_ped[0:num] == 1)[0])#计算new_ped[0:num] == 1的个数
else:
updated_batch_pednum[idx] = len(np.where(new_ped[int(cumsum[idx - 1]):num] == 1)[0])#计算new_ped[int(cumsum[idx - 1]):num] == 1)的个数
return updated_batch_pednum#返回
def mean_normalize_abs_input(self, node_abs, st_ed):#绝对坐标系,转化为相对坐标系
"""
:param node_abs: Absolute coordinates of pedestrians
:type Tensor
:param st_ed: list of tuple indicates the indices of pedestrians belonging to the same scene
:type List of tupule
:return: node_abs: Normalized absolute coordinates of pedestrians
:rtype: Tensor
"""
node_abs = node_abs.permute(1, 0, 2)#原始数据是y在前,x在后,互换一下维度,把x放在前面,y放在后面。
for st, ed in st_ed:
mean_x = torch.mean(node_abs[st:ed, :, 0])#x的平均值
mean_y = torch.mean(node_abs[st:ed, :, 1])#y的平均值
node_abs[st:ed, :, 0] = (node_abs[st:ed, :, 0] - mean_x)
node_abs[st:ed, :, 1] = (node_abs[st:ed, :, 1] - mean_y)#相对坐标
return node_abs.permute(1, 0, 2)#变换回y在前,x在后,并且返回
def forward(self, inputs, iftest=False):#定义STAR模型的连接方式
nodes_abs, nodes_norm, shift_value, seq_list, nei_lists, nei_num, batch_pednum = inputs
num_Ped = nodes_norm.shape[1]
outputs = torch.zeros(nodes_norm.shape[0], num_Ped, 2).cuda()#输出每个行人的坐标(y,x)
GM = torch.zeros(nodes_norm.shape[0], num_Ped, 32).cuda()#w/r记忆模块,每一个行人32维
noise = get_noise((1, 16), 'gaussian')#16维度的高斯噪声
for framenum in range(self.args.seq_length - 1):#对每一帧的数据进行遍历
if framenum >= self.args.obs_length and iftest:#如果是超过数据集范围,或者是测试集则执行
node_index = self.get_node_index(seq_list[:self.args.obs_length])#得到当前帧还存在的行人信息
updated_batch_pednum = self.update_batch_pednum(batch_pednum, node_index)#更新行人的数量,删除消失的人
st_ed = self.get_st_ed(updated_batch_pednum)#拿到起始索引和终止索引
nodes_current = outputs[self.args.obs_length - 1:framenum, node_index]#得到当前帧还存在的行人坐标输出
nodes_current = torch.cat((nodes_norm[:self.args.obs_length, node_index], nodes_current))#将当前行人坐标加入到原始数据中
node_abs_base = nodes_abs[:self.args.obs_length, node_index]#当前帧的行人绝对坐标
node_abs_pred = shift_value[self.args.obs_length:framenum + 1, node_index] + outputs[
self.args.obs_length - 1:framenum,
node_index]
node_abs = torch.cat((node_abs_base, node_abs_pred), dim=0)#将输出拼接到之前的数据中
# We normalize the absolute coordinates using the mean value in the same scene
node_abs = self.mean_normalize_abs_input(node_abs, st_ed)#记录为相对坐标
else:#否则执行
node_index = self.get_node_index(seq_list[:framenum + 1])
nei_list = nei_lists[framenum, node_index, :]
nei_list = nei_list[:, node_index]
updated_batch_pednum = self.update_batch_pednum(batch_pednum, node_index)
st_ed = self.get_st_ed(updated_batch_pednum)
nodes_current = nodes_norm[:framenum + 1, node_index]
# We normalize the absolute coordinates using the mean value in the same scene
node_abs = self.mean_normalize_abs_input(nodes_abs[:framenum + 1, node_index], st_ed)
# Input Embedding
if framenum == 0:#如果是第0帧则执行
temporal_input_embedded = self.dropout_in(self.relu(self.input_embedding_layer_temporal(nodes_current)))#用FN网络进行编码嵌入时间enconder
else:否则
temporal_input_embedded = self.dropout_in(self.relu(self.input_embedding_layer_temporal(nodes_current)))#用FN网络进行编码嵌入时间enconder
temporal_input_embedded[:framenum] = GM[:framenum, node_index]#framenum之前的用GM存储器中的代替时间enconder输入
spatial_input_embedded_ = self.dropout_in2(self.relu(self.input_embedding_layer_spatial(node_abs)))
spatial_input_embedded = self.spatial_encoder_1(spatial_input_embedded_[-1].unsqueeze(1), nei_list)#空间enconder编码嵌入,引入了邻居矩阵
spatial_input_embedded = spatial_input_embedded.permute(1, 0, 2)[-1]
temporal_input_embedded_last = self.temporal_encoder_1(temporal_input_embedded)[-1]
temporal_input_embedded = temporal_input_embedded[:-1]
fusion_feat = torch.cat((temporal_input_embedded_last, spatial_input_embedded), dim=1)#将时间与空间enconder输出按列拼接
fusion_feat = self.fusion_layer(fusion_feat)#全连接网络64-32
spatial_input_embedded = self.spatial_encoder_2(fusion_feat.unsqueeze(1), nei_list)
spatial_input_embedded = spatial_input_embedded.permute(1, 0, 2)#第二个空间enconder
temporal_input_embedded = torch.cat((temporal_input_embedded, spatial_input_embedded), dim=0)#第二个时间enconder为第二个空间enconder的输出+ temporal_input_embedded[:-1]
temporal_input_embedded = self.temporal_encoder_2(temporal_input_embedded)[-1]
noise_to_cat = noise.repeat(temporal_input_embedded.shape[0], 1)#16维的高斯噪声
temporal_input_embedded_wnoise = torch.cat((temporal_input_embedded, noise_to_cat), dim=1)#拼接为16+32=48维向量
outputs_current = self.output_layer(temporal_input_embedded_wnoise)#48-2网络层
outputs[framenum, node_index] = outputs_current
GM[framenum, node_index] = temporal_input_embedded
return outputs#返回
模型输出:
STAR(
(temporal_encoder_layer): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): Linear(in_features=32, out_features=32, bias=True)
)
(linear1): Linear(in_features=32, out_features=2048, bias=True)
(dropout): Dropout(p=0, inplace=False)
(linear2): Linear(in_features=2048, out_features=32, bias=True)
(norm1): LayerNorm((32,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((32,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0, inplace=False)
(dropout2): Dropout(p=0, inplace=False)
)
(spatial_encoder_1): TransformerModel(
(transformer_encoder): TransformerEncoder(
(layers): ModuleList(
(0): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): Linear(in_features=32, out_features=32, bias=True)
)
(linear1): Linear(in_features=32, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=32, bias=True)
(norm1): LayerNorm((32,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((32,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
)
(1): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): Linear(in_features=32, out_features=32, bias=True)
)
(linear1): Linear(in_features=32, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=32, bias=True)
(norm1): LayerNorm((32,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((32,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
)
)
)
)
(spatial_encoder_2): TransformerModel(
(transformer_encoder): TransformerEncoder(
(layers): ModuleList(
(0): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): Linear(in_features=32, out_features=32, bias=True)
)
(linear1): Linear(in_features=32, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=32, bias=True)
(norm1): LayerNorm((32,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((32,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
)
(1): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): Linear(in_features=32, out_features=32, bias=True)
)
(linear1): Linear(in_features=32, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=32, bias=True)
(norm1): LayerNorm((32,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((32,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
)
)
)
)
(temporal_encoder_1): TransformerEncoder(
(layers): ModuleList(
(0): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): Linear(in_features=32, out_features=32, bias=True)
)
(linear1): Linear(in_features=32, out_features=2048, bias=True)
(dropout): Dropout(p=0, inplace=False)
(linear2): Linear(in_features=2048, out_features=32, bias=True)
(norm1): LayerNorm((32,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((32,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0, inplace=False)
(dropout2): Dropout(p=0, inplace=False)
)
)
)
(temporal_encoder_2): TransformerEncoder(
(layers): ModuleList(
(0): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): Linear(in_features=32, out_features=32, bias=True)
)
(linear1): Linear(in_features=32, out_features=2048, bias=True)
(dropout): Dropout(p=0, inplace=False)
(linear2): Linear(in_features=2048, out_features=32, bias=True)
(norm1): LayerNorm((32,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((32,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0, inplace=False)
(dropout2): Dropout(p=0, inplace=False)
)
)
)
(input_embedding_layer_temporal): Linear(in_features=2, out_features=32, bias=True)
(input_embedding_layer_spatial): Linear(in_features=2, out_features=32, bias=True)
(output_layer): Linear(in_features=48, out_features=2, bias=True)
(fusion_layer): Linear(in_features=64, out_features=32, bias=True)
(relu): ReLU()
(dropout_in): Dropout(p=0, inplace=False)
(dropout_in2): Dropout(p=0, inplace=False)
)