论文: TGIF-QA: Toward Spatio-Temporal Reasoning in Visual Question Answering
作者: 首尔国立大学
来源: CVPR2017
源码:github
文章目录
1.摘要
本篇论文主要是将图像问答(ImageQA)引入到视频领域(VideoQA),其有三个主要贡献:
- 为VideoQA设计了三个任务(需要结合时空信息来回答);
- 在已有的ImageQA工作上进行扩展,得到 TGIF-QA数据集。
- 提出一个双路-LSTM模型(带有时间和空间注意力)
现有的两个数据库[1,2]主要是故事线的综合理解(短视频剪影[1],电影及其字幕[2]),但是问题-答案对却是传统ImageQA的简单拓展。
本片论文提出的三个任务主要受这两篇视频理解论文启发:repetition counting [3],state transitions [4]。
- 计算给定动作的出现次数,答案为0-10+共11种可能;
- 检测一个给定出现次数的动作,为多项选择;
- 确定状态转移,包含面部表情(开心->悲伤),地方(桌子->地板),物体属性(空->满)。

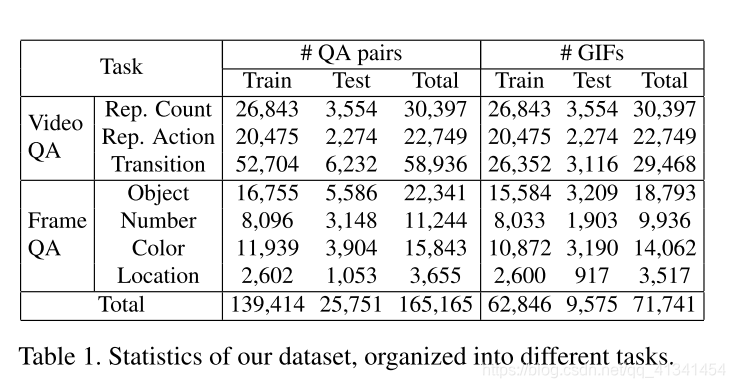
除此还包含关于图像的问答(Frame QA):利用TGIF数据集的视频描述,以及[6]中提出的基于NLP的方法来产生QA对。
其余的QA对主要通过众包服务和基于模板的方法来实现。

数据集的问题可以是开放式的(open-ended)或者多项选择(multiple choice)。 - 开放式的:提供完整或者不完整的句子,系统猜测正确的答案单词;
- 多项选择:提供文本描述或者包围框描述的选项
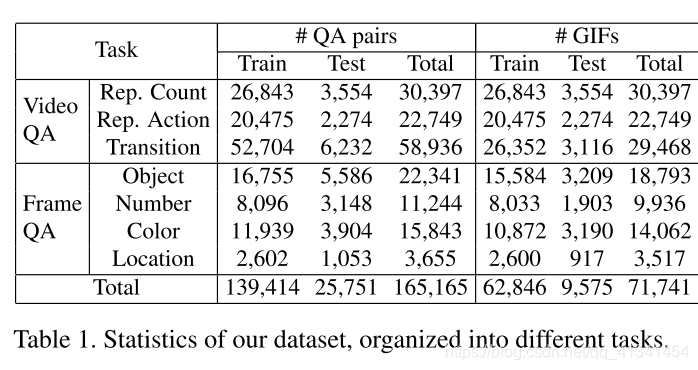
本数据集建立在 Tumblr GIF(TGIF)数据集[5]上(主要用于视频摘要),对来自TGIF的 71,741 标注的 GIFs增加 165,165 问题对以此形成TGIF-QA数据集。
2.方法
本文提出的 spatio-temporal VQA(ST-VQA)如下图:
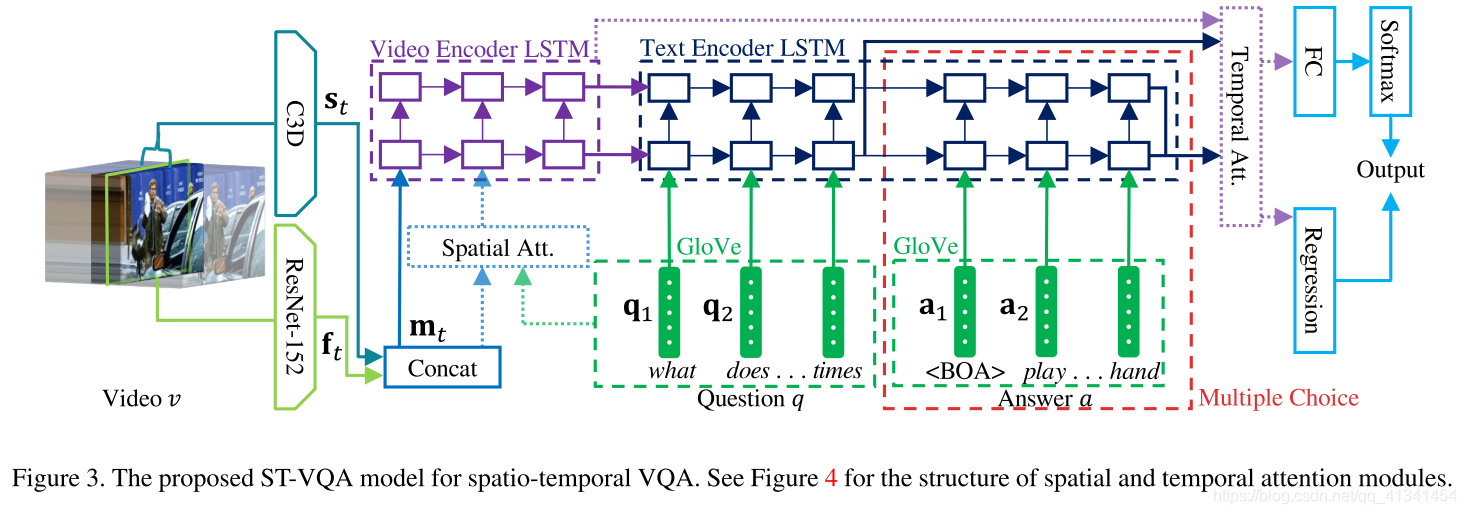
输入是一个三元组
:
- v 表示输入的 video clip
- q 表示输入的 question sentence
- a 表示 answer phrase(只有多项选择题的时候提供)
2.1 特征表达
2.1.1 视频特征
视频特征主要分为 外观特征(frame-level) 和 序列特征(sequence-level) ,
。
- 对于外观特征,使用在ImageNet-2012 [7]上预训练的 ResNet152[8]
- 对于运动特征,使用在Sport1M Dataset [9]上预训练的 C3D[10].
[7] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. S. Bernstein, A. C. Berg, and F.-F. Li. ImageNet Large Scale Visual Recognition Challenge. IJCV, 2015.
[8] K. He, X. Zhang, S. Ren, and J. Sun. Deep Residual Learning for Image Recognition. In CVPR, 2016.
[9] A. Karpathy, G. Toderici, S. Shetty, T. Leung, R. Sukthankar, and F.-F. Li. Large-Scale Video Classification with Convolutional Neural Networks. In CVPR, 2014.
[10] D. Tran, L. D. Bourdev, R. Fergus, L. Torresani, and M. Paluri. Learning Spatiotemporal Features with 3D Convolutional Networks. In ICCV, 2015.
- 同时,我们每4帧提取一帧来减少帧的数目
- 对于C3D特征,我们每个时间步取16个后续帧居中
- 两个特征分别记为
- 如果使用时空注意力机制,我们在 1) ResNet152的 res5c 层( )使用空间注意力机制,在 pool5 层( )使用时间注意力机制。在C3D特征的 conv5b( )使用空间注意力,在 fc6( )使使用时间注意力机制。
2.1.2 文本特征
对于问题以及答案,我们都使用在 Commom Crawl Dataset[11] 上预训练的 GloVe word embedding[12] 的 300D 特征。分别表示为
和
。
[11]
[12] J. Pennington, R. Socher, and C. D. Manning. Glove - Global Vectors for Word Representation. In EMNLP, 2014.
2.2 视频和文本编码
2.2.1 视频编码

- 我们先将两个特征进行联合,形成 ,并将其送入一个双层的LSTM。每个时间点送一个,得到一个隐藏状态 (D = 512):
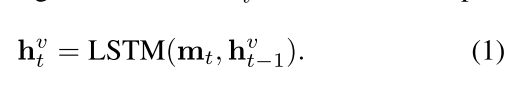
- 由于是双层,最后得到两个隐藏层状态 。
2.2.2 文本编码

- 我们各使用一个双层的LSTM来编码问题向量组和答案向量组:
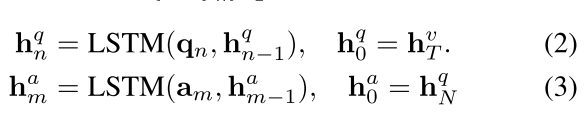
- 特别地,我们这里问题编码器的起始状态 是视频编码器的末状态 ,以致于视觉信息被送到文本编码器,和[13][14]中的序列-序列模型类似。
[13] I. Sutskever, O. Vinyals, and Q. Le. Sequence to Sequence Learning with Neural Networks. In NIPS, 2014.
[14] S. Venugopalan, M. Rohrbach, J. Donahue, R. Mooney, T. Darrell, and K. Saenko. Sequence to Sequence – Video to Text. In ICCV, 2015.
- 对于答案编码器,为了表明候选答案的开始,我们用一个特殊的字符 (begin of answer)。同样的,我们也用问题编码器的最后一个隐藏层状态来作为答案编码器的初始隐藏层状态。(与视频编码器统一,我们的文本编码器也使用维度大小D=512)。
2.3 答案解码
设置了三个解码器来计算最终答案:一个适用于多项选择,两个适用于开放式问题。
2.3.1 多项选择
我们用一个线性回归函数来从答案编码器的最终状态来计算每一个候选答案的实值分数:

然后用 hinge loss 来进行训练:
,其中
和
分别是正确答案和错误答案的分数。
这个解码器适用于:状态转移和重复动作判断
2.3.2 回答数字问题(开放式问题)
和上面一个解码器类似,都是从答案编码器的末隐藏状态开始:
适用于计算重复动作的次数
问题:
为什么回答数字是从答案编码器中取隐藏层状态,对于回答数字的开放式问题,难道类似于多项选择0-10?
2.3.3 回答单词(开放式问题)
将问题编码器中的末隐藏层状态
作为输入,使用一个线性分类器计算一个置信向量:
其中
,
是我们预选的字典集合。所以
。
最后使用
来进行训练。
可以用于解决 ImageQA 问题:
2.4 注意力机制
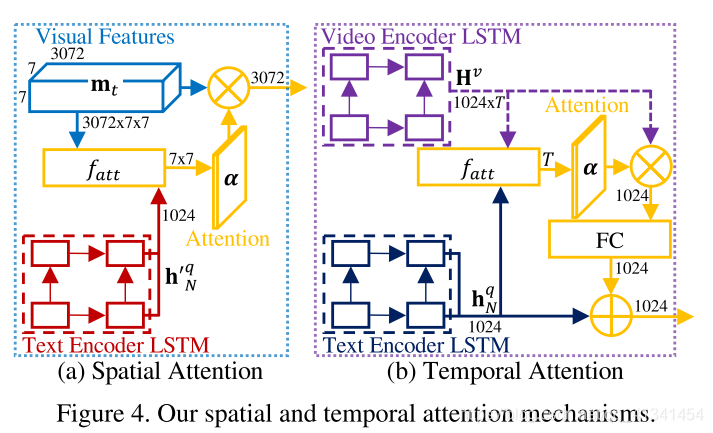
左图的空间注意力机制:选择一个视频的一个帧中哪个区域需要注意[15];
右图的时间注意力机制:选择一个视频中哪些帧需要注意[16];
[15] K. Xu, J. Ba, R. Kiros, K. Cho, A. Courville, R. Salakhutdinov, R. Zemel, and Y. Bengio. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. In ICML, 2015.
[16] D. Bahdanau, K. Cho, and Y. Bengio. Neural Machine Translation by Jointly Learning to Align and Translate. In ICLR, 2015.
空间注意力机制
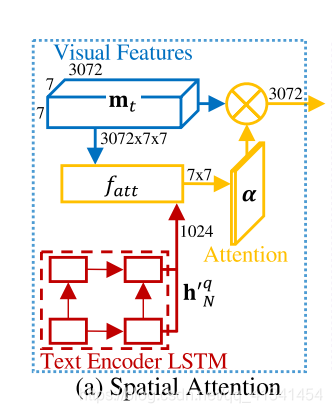
为了学习到每个单词注意的区域,我们将保存了空间信息的视觉表达,与一个 QA 对进行联合。但是,我们的 QA 对只有在视频编码输出后才进行输入,所以 这里,我们需要定义一个与文本编码器共享权重的双层LSTM。
对于
时刻帧的特征图,我们计算一个
的空间注意力掩码:
其中,
是我们文本编码器的输出,
是我们视觉特征图。然后注意力调整的视觉特征
送入我们的视频编码器。
特别地,
是一个多层感知机,在
的大小上进行滑动,然后接一个
计算分数。(隐藏结点大小512,激活函数
)。
这个MLP是一个3072->512的映射吗?然后操作 7x7 次?(看源码确定)
时间注意力

在编码完视频和文本之后,我们计算一个
的时间注意力掩码
其中,
属于文本编码器的末隐藏层状态;
是来自视频编码器的;
然后计算注意力之后的文本信号:
,
其中,
,
是逐元素相加。
最后将其送入答案解码器。
特别地,这里的
与之前的空间注意力类似,只是在时间维度 T 上进行操作。
2.5 实现细节
ResNet[1],C3D[2]和GloVe[3]都使用原始实现。
[1] K. He, X. Zhang, S. Ren, and J. Sun. Deep Residual Learning for Image Recognition. In CVPR, 2016.
[2] D. Tran, L. D. Bourdev, R. Fergus, L. Torresani, and M. Paluri. Learning Spatiotemporal Features with 3D Convolutional Networks. In ICCV, 2015.
[3] J. Pennington, R. Socher, and C. D. Manning. Glove - Global Vectors for Word Representation. In EMNLP, 2014.
[4] J. L. Ba, J. R. Kiros, and G. E. Hinton. Layer Normalization. 2016.
对于双层LSTM,使用 layer normalization[4],而且使用
。
优化器使用 Adam,初始学习率等于 0.001。其中, LSTMs的权重用均匀分布,其它权重用正太分布初始化。
3. 实验
- 对于多项选择和开放式单词回答,我们看成一个多分类器,然后用准确度Acc度量;
- 对于开放式数字回答任务,用平均 损失;
- 按照原来 TGIF 的标准分训练集和测试集:
3.1 实验结果
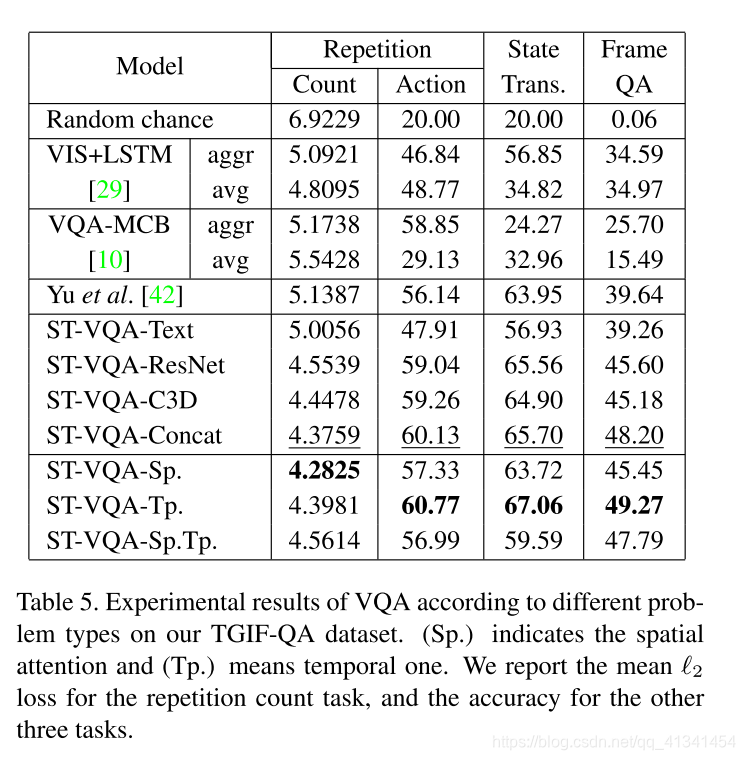
准备好一些BaseLine之后,作者将它提出的模型分了7个变种来做对比实验:
- 前4个(Text, ResNet, C3D, Concat)表示不同的视频特征表达,其中 Text 不用 ResNet 和 C3D 特征,Concat 两个特征都用,其余两个只用一个特征,但是都不用注意力机制;
- 下面两个变种只包含一个注意力特征,但是特征都用上了。最后一个才是上文提出的模型。
3.2 结果分析
- 对于特征的对比实验表明两种特征都对最后的推理起到一定作用;
- 对于注意力的分析表明 时间注意力 对最后的结果有很大的提升。正如之前文献[1]中使用局部和全局时间注意力使得 Video Captioning 任务得到提升一样。
[1] L. Yao, A. Torabi, K. Cho, N. Ballas, C. Pal, H. Larochelle, and A. Courville. Describing Videos by Exploiting Temporal Structure. In ICCV, 2015.
4.总结
- 本文的模型基于 序列-序列[1] 的模型,可以用 3D卷积[2] 来进行适当改进;
- Concat 模型结合视觉-文本信息 只在文本编码器上。最终模型也只在注意力机制时使用,应该存在更先进的方式来融合多模态信息。例如,[3]中提出的 multimodal compact bilinear pooling。
[1] S. Venugopalan, M. Rohrbach, J. Donahue, R. Mooney, T. Darrell, and K. Saenko. Sequence to Sequence – Video to Text. In ICCV, 2015.
[2] D. Tran, L. D. Bourdev, R. Fergus, L. Torresani, and M. Paluri. Learning Spatiotemporal Features with 3D Convolutional Networks. In ICCV, 2015.
[3] A. Fukui, D. H. Park, D. Yang, A. Rohrbach, T. Darrell, and M. Rohrbach. Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding. In EMNLP, 2016.
5.暂存问题
- 看源码,确定注意力机制中 MLP 的具体实现细节;
6.引用文献
[1] A. Rohrbach, A. Torabi, M. Rohrbach, N. Tandon, C. Pal, H. Larochelle, A. Courville, and B. Schiele. Movie Description. IJCV, 2017.
[2] M. Tapaswi, Y. Zhu, R. Stiefelhagen, A. Torralba, R. Urtasun, and S. Fidler. MovieQA: Understanding Stories in Movies through Question-Answering. In CVPR, 2016.
[3] O. Levy and L. Wolf. Live Repetition Counting. In ICCV, 2015.
[4] P. Isola, J. J. Lim, and E. H. Adelson. Discovering States and Transformations in Image Collections. In CVPR, 2015.
[5] Y. Li, Y. Song, L. Cao, J. Tetreault, L. Goldberg, A. Jaimes, and J. Luo. TGIF: A New Dataset and Benchmark on Animated GIF Description. In CVPR, 2016
[6] M. Ren, R. Kiros, and R. Zemel. Exploring Models and Data for Image Question Answering. In NIPS, 2015.
7.总结知识
1.引入VQA的论文:
- S. Antol, A.D Agrawal, J. Lu, M. Mitchell, D. Batra, C. L. Zitnick, and D. Parikh. VQA: Visual Question Answering. In ICCV, 2015.
- M. Malinowski and M. Fritz. A Multi-World Approach to Question Answering about Real-World Scenes based on Uncertain Input. In NIPS, 2014.
2.关于视频分析的论文
- A. Karpathy, G. Toderici, S. Shetty, T. Leung, R. Sukthankar, and F.-F. Li. Large-Scale Video Classification with Convolutional Neural Networks. In CVPR, 2014.
- N. Srivastava, E. Mansimov, and R. Salakhutdinov. Unsupervised Learning of Video Representations using LSTMs. In ICML, 2015.
- D. Tran, L. D. Bourdev, R. Fergus, L. Torresani, and M. Paluri. Learning Spatiotemporal Features with 3D Convolutional Networks. In ICCV, 2015.
3.其它相关的数据集
- LSMDC-QA: 电影填空任务;
- MovieQA:自动故事理解任务;
4.GloVe word Embedding:
- J.Pennington, R. Socher, and C. D. Manning. Glove - Global Vectors for Word Representation. In EMNLP, 2014.
