论文

标题:Class Re-Activation Maps for Weakly-Supervised Semantic Segmentation
收录:CVPR 2022
paper: https://arxiv.org/abs/2203.00962
code: https://github.com/zhaozhengChen/ReCAM
解读:https://zhuanlan.zhihu.com/p/478133151
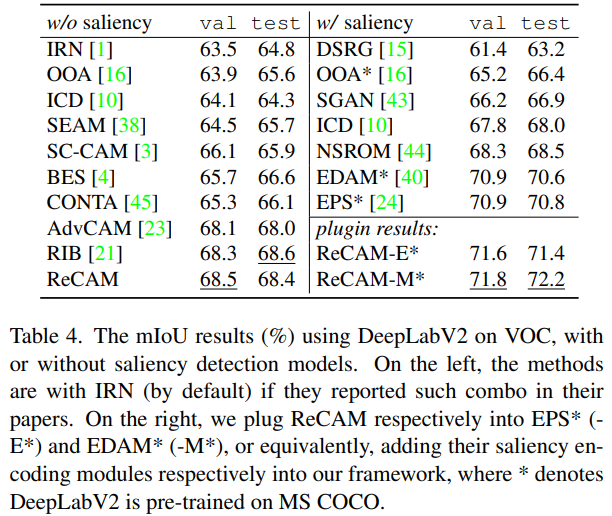
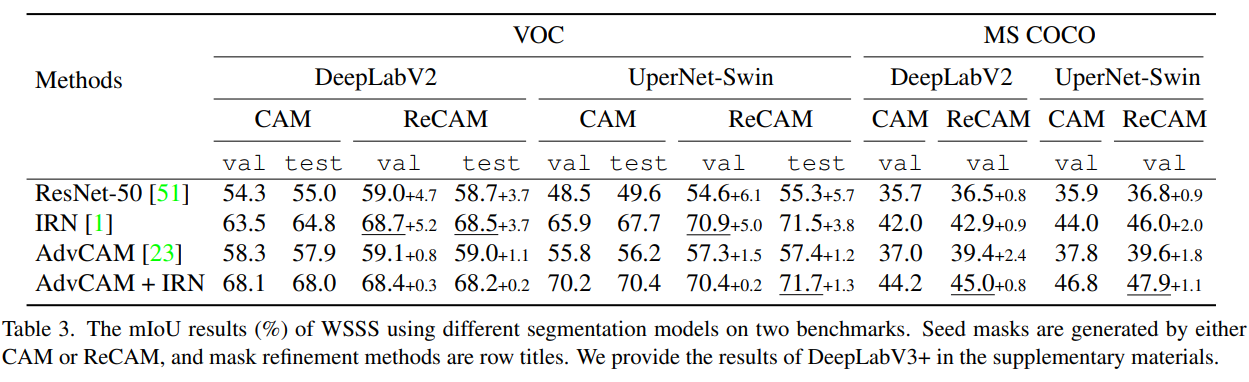
本篇文章利用分类标签训练分类网络生成CAM出发,引出了使用BCE作为损失函数对于分类网络生成CAM的缺陷,并以此为基础,提出了一种结合BCE和SCE(即softmax 交叉熵,一般用于单标签图像分类)来训练分类网络的的方法。该方法极大程度的提升了CAM的质量。以CAM为基础生成的伪标签来训练的分割模型,最终在使用Deeplab v2的情况在VOC和MS COCO测试集上分别达到了68.2%和45.0的mIoU。当然在使用更好的框架和训练技巧后,VOC测试集的mIoU可以提升至72.2%。
摘要
提取类激活图(class activation maps, CAM)可以说是为弱监督语义分割(WSSS)生成 pseudo mask 的最标准步骤。然而,论文发现,在CAM中广泛使用的二进制交叉熵损失(Binary Cross-Entrop, BCE) loss 是导致 pseudo mask 效果不佳的症结所在。具体地说,由于BCE的 sum-over-class pooling 特点,每个像素CAM可以响应于在同一感受野中共同出现的多个类别。因此,给定一个类,它所激活的CAM像素可能错误地侵入属于其他类的区域,或者非激活的CAM像素实际上可能是类的一部分。为此,论文介绍了一种简单但效果惊人的方法:通过使用softmax cross-entropy loss(SCE)来重新激活用BCE收敛的CAM,称为ReCAM。给定一幅图像,使用CAM来提取每个单独类的特征像素,并将它们与类标签一起使用来学习另一个在backbone之后的具有SCE的全连接层。一旦收敛。就可以使用CAM相同的方法提取ReCAM。由于SCE的对比性(contrastive nature),像素响应被分成不同的类别,因此预期的掩码模糊性较小。
引言
Weakly-supervised semantic segmentation (WSSS) 旨在通过使用 "weak" labels,例如:随意的画一笔, bounding box, 或者image-level的标签去减少 "strong" 的标注,image-level的标签是最经济又最具挑战性的任务,因此也是本文的重点。一个比较通用的pipeline由以下三步组成:
使用image-level的标签去训练一个多分类模型。
使用例如 erosion 或者 expansion 的 potential refinement 策略为每一类提取class activation map(CAM)生成一个0-1mask。
使用生成的mask作为伪标签去训练一个基础的全监督语义分割网络。
影响最终分割模型性能的因素各有不同,但第一步的分类模型绝对是根本。我们经常观察到两个共同的缺陷:对于种类A的一个object 的CAM,他有:
为A类激活但具有B类的实际标签的假阳性像素false positive pixels,其中B通常是A的混淆类而不是背景-语义分割中的特殊类。
属于A类但是却被错误的贴上背景标签的 false negative pixels。
作者指出,当用具有Sigmoid激活函数的二进制交叉熵(Binary Cross-Entrop, BCE)损失来训练模型时,这些缺陷尤其明显。具体的说,sigmoid function是 ,其中 x代表每个单个类的预测分。 输出被喂给BCE函数去计算loss。此loss表示对应于x的错误分类的惩罚强度。因此,BCE损失不是类别互斥的——一个类别的错误分类不会惩罚其他类别的激活。这对于训练多标签分类器是必不可少的。因此,当从这些分类器中提取CAM的时候,我们可以看到这些缺点:不同的类别会共同激活一个区域,结果就是CAM中的false positive pixels。由于部分激活是共享的,所以对Tota lClass的激活是有限的(导致false negative pixels)。
,其中 x代表每个单个类的预测分。 输出被喂给BCE函数去计算loss。此loss表示对应于x的错误分类的惩罚强度。因此,BCE损失不是类别互斥的——一个类别的错误分类不会惩罚其他类别的激活。这对于训练多标签分类器是必不可少的。因此,当从这些分类器中提取CAM的时候,我们可以看到这些缺点:不同的类别会共同激活一个区域,结果就是CAM中的false positive pixels。由于部分激活是共享的,所以对Tota lClass的激活是有限的(导致false negative pixels)。
动机
图1说明,使用BCE时CAM质量比不过使用SCE的质量,SCE的分类能力比BCE强。作者指出这是因为BCE的Sigmoid激活函数没有强制类独占学习,混淆了相似类之间的模型。
SCE鼓励改善 ground truth的分数,同时惩罚其他的。这对CAM有两个影响:
减少不同类别间融合模型的假阳性像素 false positive pixels;
鼓励模型探索特定于类的特征,以减少假阴性像素 false negative pixels。

图1. BCE和SCE的比较,在MS COCO 2014选single-label训练80class和5class分类器,SCE的分类能力都比BCE强。
通过观察分类网络生成的类激活图(CAM),可以发现,在CAM中通常会出现如图2所示的两种错误:
False Negative(假负例):即会把一些不是背景的像素激活为背景;
False Positive(假正例):即会把一些区域的像素激活为图像中存在的其他类别。
作者认为这是使用BCE作为损失函数来监督多标签分类任务的局限性。在BCE的这种多标签分类模式中,模型最终会把特征图全局平均池化得到的预测向量输入到sigmoid中,然后计算BCE损失。这种模式中,各个类别的预测是互不相关的(本质上就是多个独立二分类器集成)。就拿一个图片中存在摩托车和人两个类别而言,模型对于车的预测的错误不会影响到对于人的预测,反之亦然。因此,这导致了在进行CAM时,同一区域,两个类别的激活值都高,甚至错误类别的激活值高于正确类别的。这也是False Positive现象出现的原因。CAM只能发现目标最具判别力的部分的缘故,利用CAM作为监督信息训练出的语义分割网络始终与真正的ground truth作为监督信息的网络存在较大差距。(CAM通常只覆盖了对象中最具识别性的部分,在背景区域激活不正确,这可以分别概括为目标的激活不足和背景的激活过度。)
因此,作者针对以上问题提出了在BCE的基础上加入SCE(即softmax来激活预测向量再送入交叉熵损失函数CE中,常用于单分类)来联合训练分类网络。
具体地说,当模型收敛于BCE时,对于图像中标注的每个独立类,作者通过normalized soft mask的格式提取CAM,即非hard thresholding。分别将所有 mask 应用于特征(即由backbone输出的 feature map block),每个mask “highlighting”用于特定类别分类的特征像素。这样,将多标签特征分解为一组单标签特征。因此,可以使用这些特征(和标签)来训练具有SCE的多类分类器,例如,通过在backbone之后插入另一完全连接层。SCE Loss可以惩罚任何由不良特征或不良mask引起的错误分类。然后,反向传播它的梯度也有助于这两点。一旦收敛,可以用与CAM相同的方式提取ReCAM。
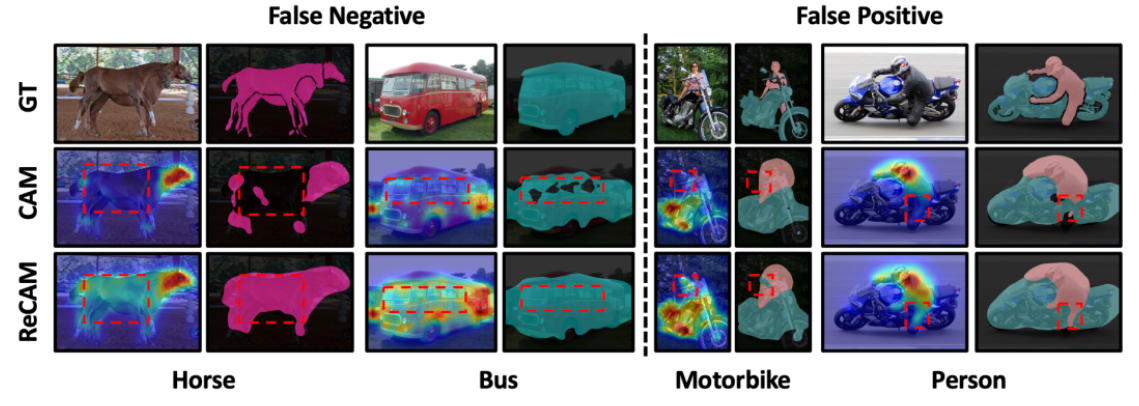
图2. CAM中的两种错误以及ReCAM对其的改进。
方法
多标签的分类任务与单标签分类任务的结合。
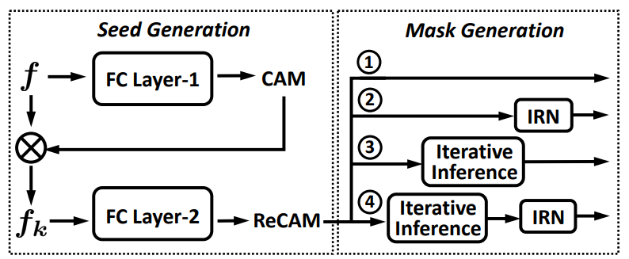
图3. 使用ReCAM的pipeline。两个步骤:种子生成和掩码生成(4种方式)。
使用BCE进行多标签分类器的常规训练。论文使用ResNet50做BackBone提取特征f。再提取每个类的CAM,然后将其(作为归一化的软掩码)应用于特征图f,以获得类的特征。软掩码)在特征图f上,以获得特定类别的特征f_k。在下部分,使用fk和它的单一标签来学习 用SCE损失学习多类分类器。这个损失的梯度被 通过整个网络包括主干网进行反向传播。
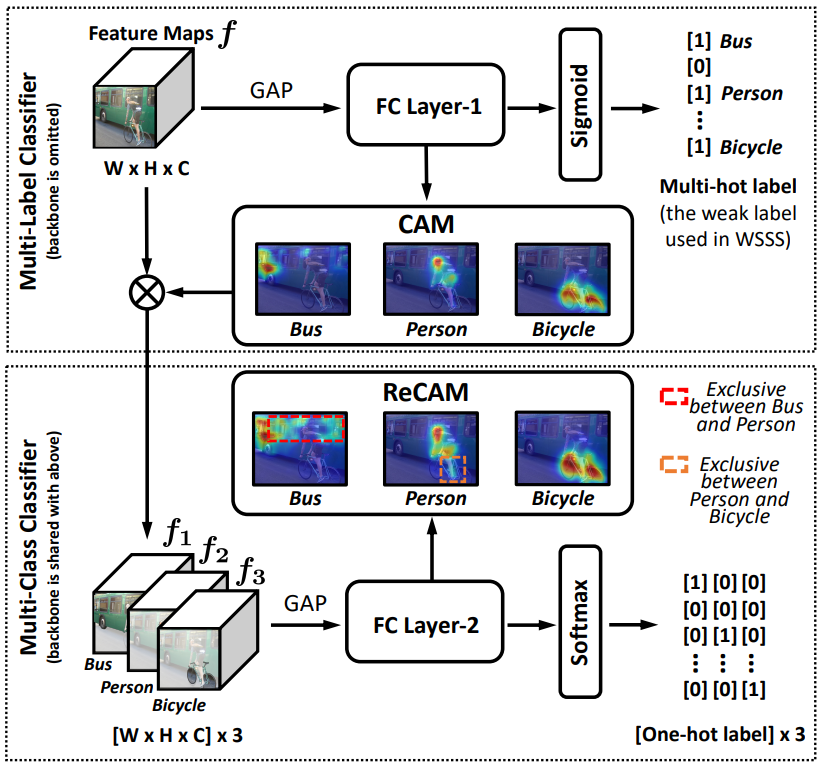
图4. ReCAM框架图

算法流程
FC Layer-1 with BCE Loss. 在传统的CAM模型中,特征 f(x)首先通过 GAP 层,然后将结果馈送到FC层进行预测。因此,预测逻辑可以表示为:

然后,使用 z 和 image-level label y来计算BCE Loss。
Extracting CAM. 在给定特征 f(x) 和FC层的相应权重 w_k的情况下,我们提取每个单独类 k的CAM,如公式(2)所示。为简明起见,我们将 记为
记为 。
。

Single-Label Feature. 使用M_k作为soft mask 应用于 f(x) 去提取class-specific feature  ,我们如下计算M_k和f(x) 的每个通道之间的逐元素乘法,
,我们如下计算M_k和f(x) 的每个通道之间的逐元素乘法,

其中 和
和  表示通过使用M_k 乘法之前和之后的单通道, c的范围从 1 到C ,C 代表feature map的通道数。feature map block (每个包含C个通道)对应于图3中的示例 f_1,f_2,f_3。
表示通过使用M_k 乘法之前和之后的单通道, c的范围从 1 到C ,C 代表feature map的通道数。feature map block (每个包含C个通道)对应于图3中的示例 f_1,f_2,f_3。
FC Layer-2 with SCE Loss. 每个 具有单个对象标签(即,其中第 k 个位置为 1的一个热标签)。然后,我们将其提供给FC第二层以学习多类分类器,因此我们有了新的预测逻辑x ,如下所示:
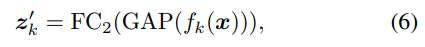
这里的 FC2和 FC1有相同的结构。通过这种方法,成功地将基于BCE的多标签图像模型转换为基于SCE的单标签特征模型。SCE loss公式为:

其中y[k]和 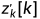 表示 y和
表示 y和 的第k 个元素,我们使用L_sce的梯度来更新包括backbone在内的模型。
的第k 个元素,我们使用L_sce的梯度来更新包括backbone在内的模型。

其中  要在 BCE和SCE之间取得平衡。
要在 BCE和SCE之间取得平衡。
Extracting ReCAM. 在重新激活之后,我们将图像 x 馈入其中以如下提取其每个类别 k 的 ReCAM,(消融实验见Table1)

Refining ReCAM (Optional).


分析
1)为什么加入SCE后要优于只使用BCE?
作者花了很多的篇幅来解释这一点。具体来说就是通过分析BCE的损失函数与SCE的损失函数的梯度来证明。SCE在模型预测正例与负例的的概率相近时会梯度较大,鼓励模型偏向预测正例而抑制负例的预测。而BCE则不然,此时,模型的梯度很小,模型倾向于不更新参数。这其实本质上就是sigmoid函数和softmax函数的区别。以上就解释了为什么加入SCE后能够减少图2中的False Positive现象。
2)为什么要将原始CAM与特征图相乘?
翻看实验,可以发现在MS COCO上没有使用这一操作,只在VOC上用了这一操作。MS COCO是直接将特征图 f 直接copy三份送入FC2中。这样效果更好。文中也没有给出明确的解释。
个人认为,这种相当于一种先验信息的加权,告诉分类器哪些区域的响应值应该重点关注,以此作为分类的依据。这种做法显然我觉得是能够提升分类的性能的。同时也能够降低那些False Positive现象。因为CAM中如果用错位激活成了别的类别的话,会在相乘后在SCE的监督下重点被改正。但是,我认为这样的做法会导致False Negative的现象得不到改善。因为分类器只需要依靠这些区域就能分类了,就不用再去注意其他的非判别性区域了,因此,那些非判别性区域就很有可能会被激活成背景。
综上,这种相乘的做法优势和劣势并存,需要结合具体情况使用。
实验
消融实验




比较实验