简介
双十一刚过,TB的销售额又创下了新高,我也为2000+亿做出了贡献
恰巧买了一袋德运奶粉,味道还不错。我就在想,接触爬虫也有两个多月了,还没有爬过TB这种经典的网站,借着劲头就爬取了一下TB上奶粉的销售信息
爬虫
在淘宝框搜索奶粉,就会弹出各式各样的奶粉

可以爬取的有用信息:价格、销售量、商品名称、店铺、地址
淘宝是一个典型用json格式存储信息的网址,通俗讲,json格式就是一层套一层的字典,像淘宝这样一个网页中有很多商品的网页,源码看起来可能会很复杂,但都是有规律可循,需要仔细观察

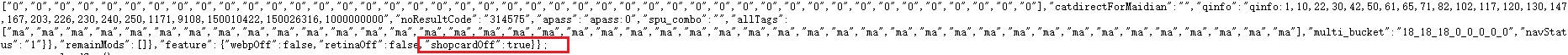
通过分析,可以看出所有的商品信息都存储在开头为g_page_config = 结尾为shopcardOff":true}};的一个字典中,只需要获取这个字典然后用python中的json库进行解析即可
response = requests.get(urls,headers = headers)
response.encoding = 'utf-8'
html = response.text
#print(html)
start = html.find('g_page_config = ')+len('g_page_config = ')
end = html.find('"shopcardOff":true}')+len('"shopcardOff":true}')
js = json.loads(html[start:end+1])
# goods = re.search(r'g_page_config = (.*?)}};', response.text)
# print(goods)
# js = json.loads(str(goods))
这里列举了两种获取方式,一是用find方法,二是用正则匹配,都能成功获取网页信息
解析网页过后,就可以从获取到的信息中提取有用信息,通过分析可得知有用信息都存储在很多层嵌套的字典中,所以通过遍历这个字典提取出信息
for i in js['mods']['itemlist']['data']['auctions']:
#产品名称
title = i['raw_title']
#产品价格
price = i['view_price']
#地区
location = i['item_loc'].split()[0]
#销售量
sales = i['view_sales'].replace('人收货','')
#评价人数
people = i['comment_count']
#店铺类型
store = i['nick']
为了便于数据分析,所以在提取信息时,将地区和销售量做了处理,例浙江 杭州→浙江;500人收货→500
数据处理
爬取数据结果如下
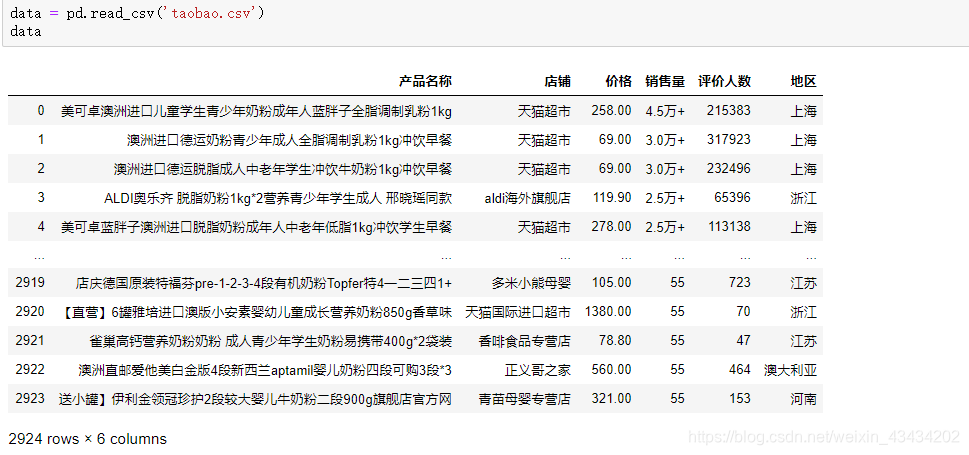
一共有2924条数据,其实是远远少于100页中商品数量
在进行数据处理前,必须先要确定所有数据的字段是否完整
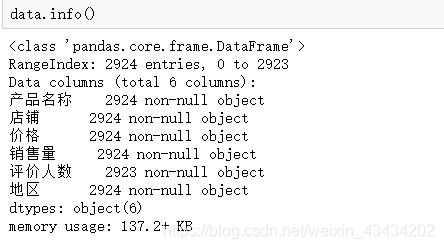
只有评价人数这个字段缺少一个数据,填充数据或者删去都不会对数据集整体产生很大影响
在观察数据时,可能在写入csv文件时语句不规范,出现了下图问题
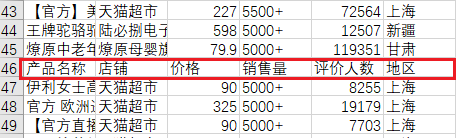
列索引多次出现在数据集中,所以必须要删去,只需要将数据集中不包含产品名称字样的样本保留即可
data1 = data[~data['产品名称'].isin(['产品名称'])]
数据集中6个特征都为object类型,所以为了进行数据可视化,需要对数据进行强制转换
价格和评价人数数据比较规范,直接用astype进行转化即可
data1['价格'] = data1['价格'].astype(float)
data1['评价人数'] = data1['评价人数'].astype(int)
但是销售量这一样本中还有其他字符存在,可以编写一个函数处理数据
def price(e):
if '万+' in e:
num1 = re.findall('(.*?)万+',e)
return float(num1[0])*10000
elif '+' in e:
return e.replace('+','')
else:
return float(e)
data1['商品销售量'] = data1['销售量'].apply(price)
同时可以通过数据字符串中特有的字符,将奶粉和店铺进行分类
奶粉大致可分为:全脂奶粉、低脂奶粉、脱脂奶粉、婴幼儿奶粉、高钙奶粉、未知
店铺大致可分为:天猫超市、旗舰店、专营店、海外类型店铺、其他店铺
已知商品价格和销售量后,也可以算出该商品的销售额
data1['销售额'] = data1['价格']*data1['商品销售量']
处理后的数据如下

在对处理后数据大致浏览时,出现了评价人数为0的情况
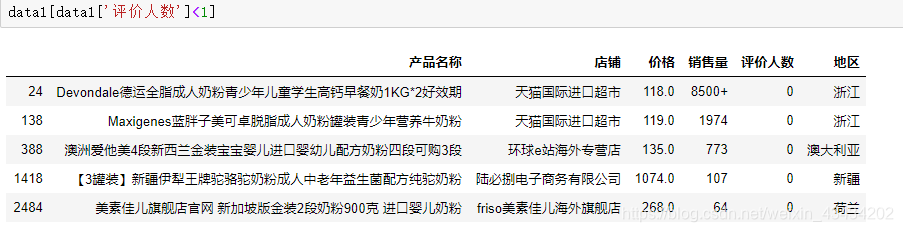
评价人数为0并不能判断这个数据是否对错,但是销售量8500的商品评价为0,就显着不符合常理,为了确定判断,找到了该商品,评价人数有33w+,显然这些是错误数据
list = data1[data1['评价人数']<1].index.tolist()
data1.drop([24, 138, 388, 1418, 2484],inplace = True)
用drop函数直接将这几行数据删去,下面进行数据可视化
数据可视化
1.类型

奶粉的类型,相对来说还是婴儿奶粉比较多,由于对产品名称提取特征不够细化,所以未知也比较多,达到了800+;店铺类型则是其他店铺占比最多,普通奶粉可依据价格挑选,但是婴儿奶粉一定要依据质量挑选才可,尽可能在旗舰店这样比较可靠的店铺购买
2.店铺地址分布
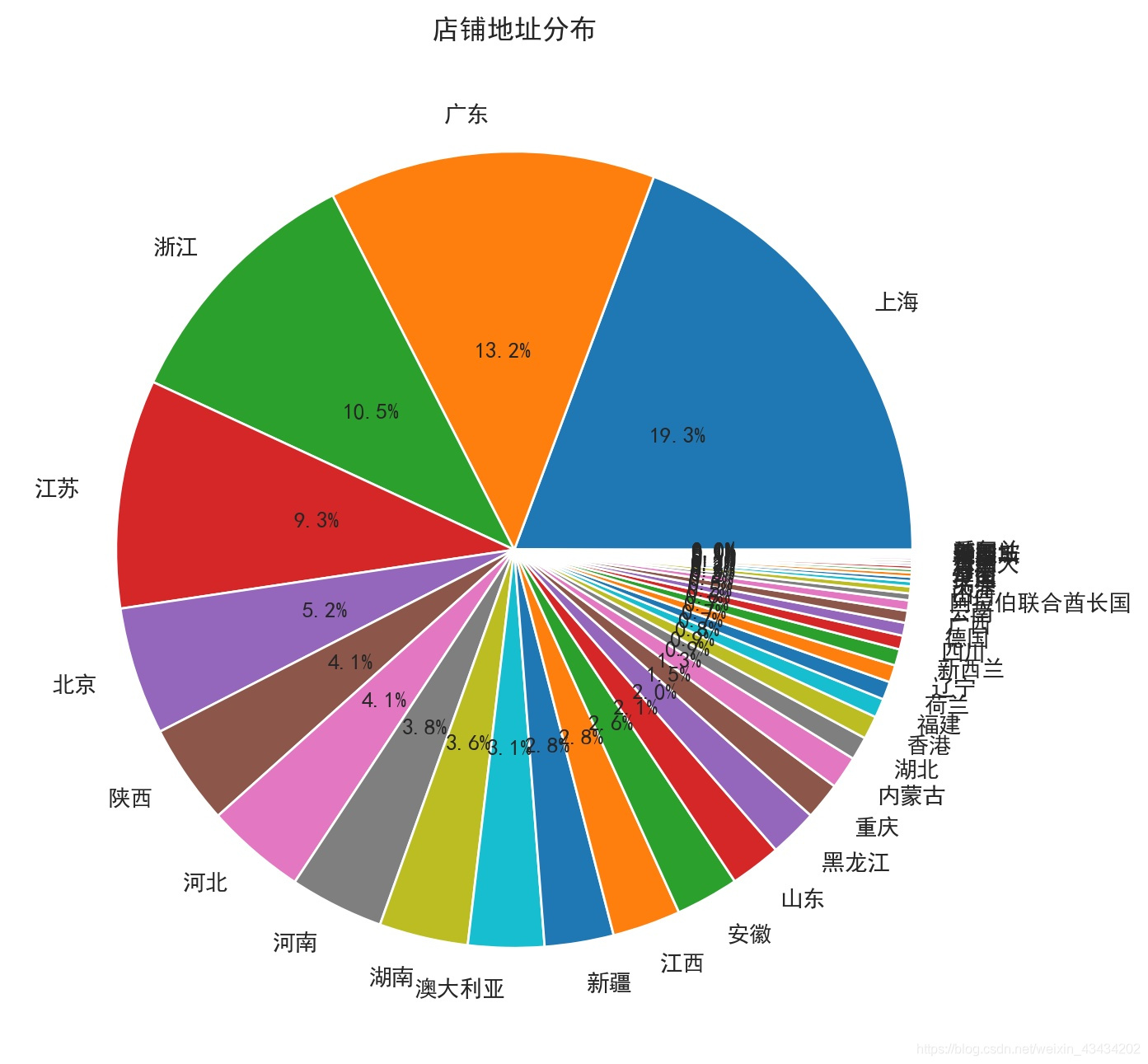
店铺地址仍然是江浙沪、广东占据大比例,可能不止奶粉,许多其他商品的网店、配货仓库都集中分布在这些地区;众所周知,澳大利亚的奶粉是及其出名的,所以也占一定比例
3.价格
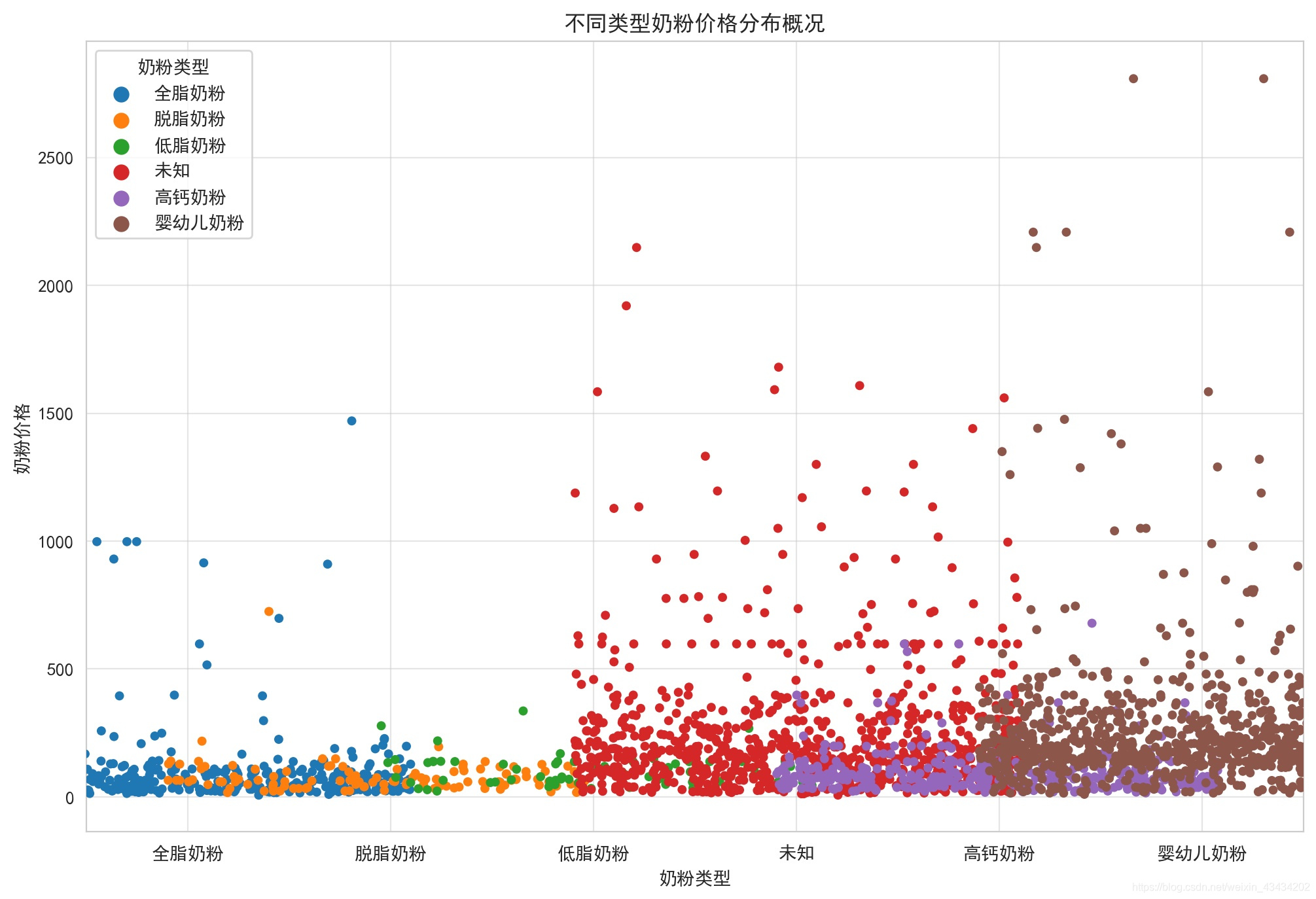
婴儿奶粉的价格品牌是非常多的,所以价格分布也较广泛,有的甚至达到了2000+,看来养孩子真的是不容易;相比脱脂、低脂奶粉,全脂奶粉反而价格更高,有点出乎意料,多了工序价格却还低了?当然品牌造成的影响也不可否认;高钙奶粉价格相对来说中规中矩,贵一点的也不过500左右
4.销售额前50分布
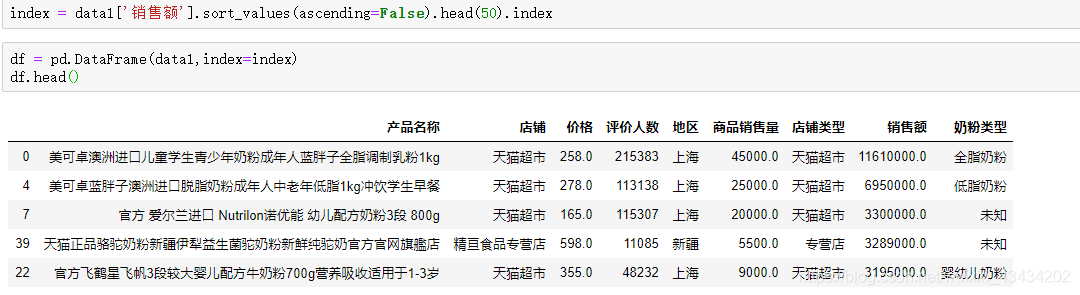
这份数据中奶粉销售额最高的可以达到1100w+,所以在网店中,奶粉的市场还是不小的
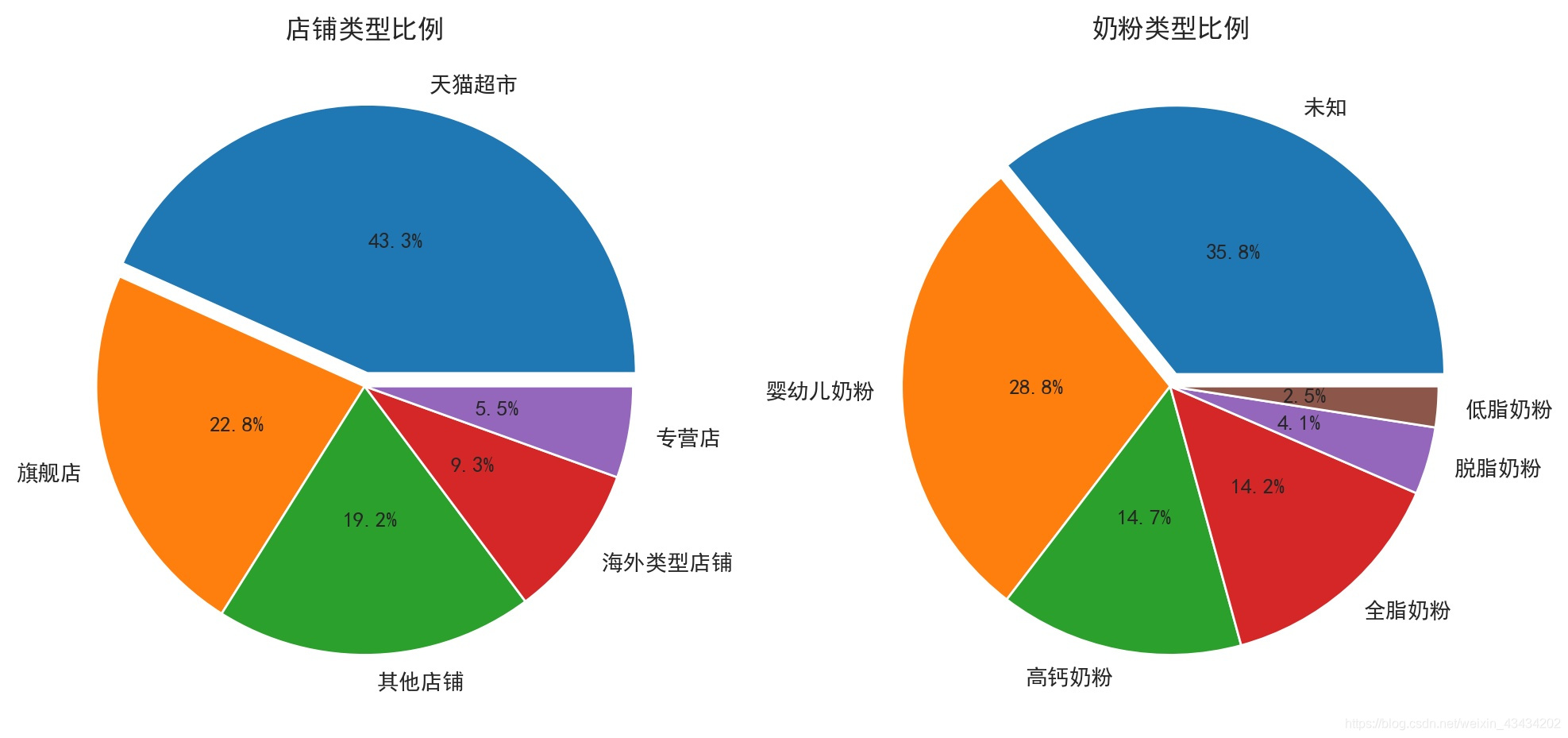
销售额TOP50份样本,43.3%的店铺都为天猫超市,旗舰店也占有22.8%,所以可见大部分人买奶粉还是会到比较可靠的网店购买的;奶粉类型还是未知占据最多,其次婴幼儿奶粉占比28.8%,而低脂奶粉和脱脂奶粉总占比6.7%,这两类奶粉会对健身人士、老年人及消化不良的婴儿的人有些益处,所以销售额也会相对较低
